


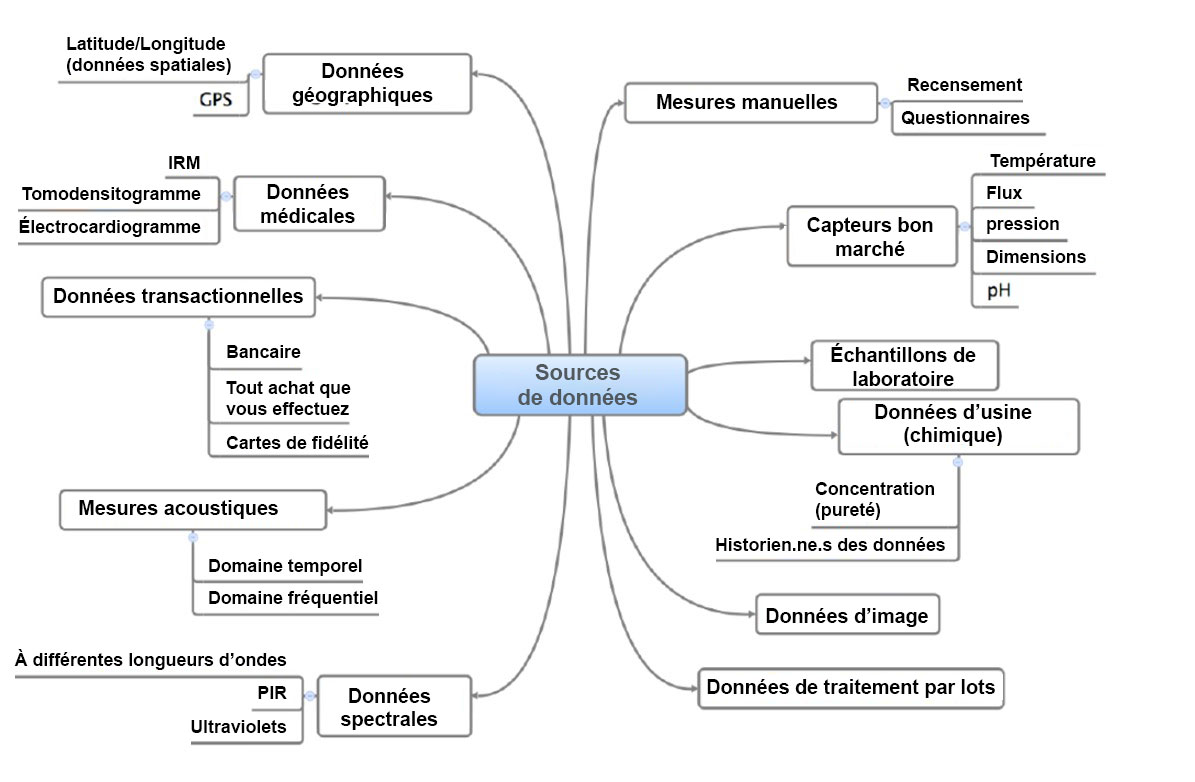

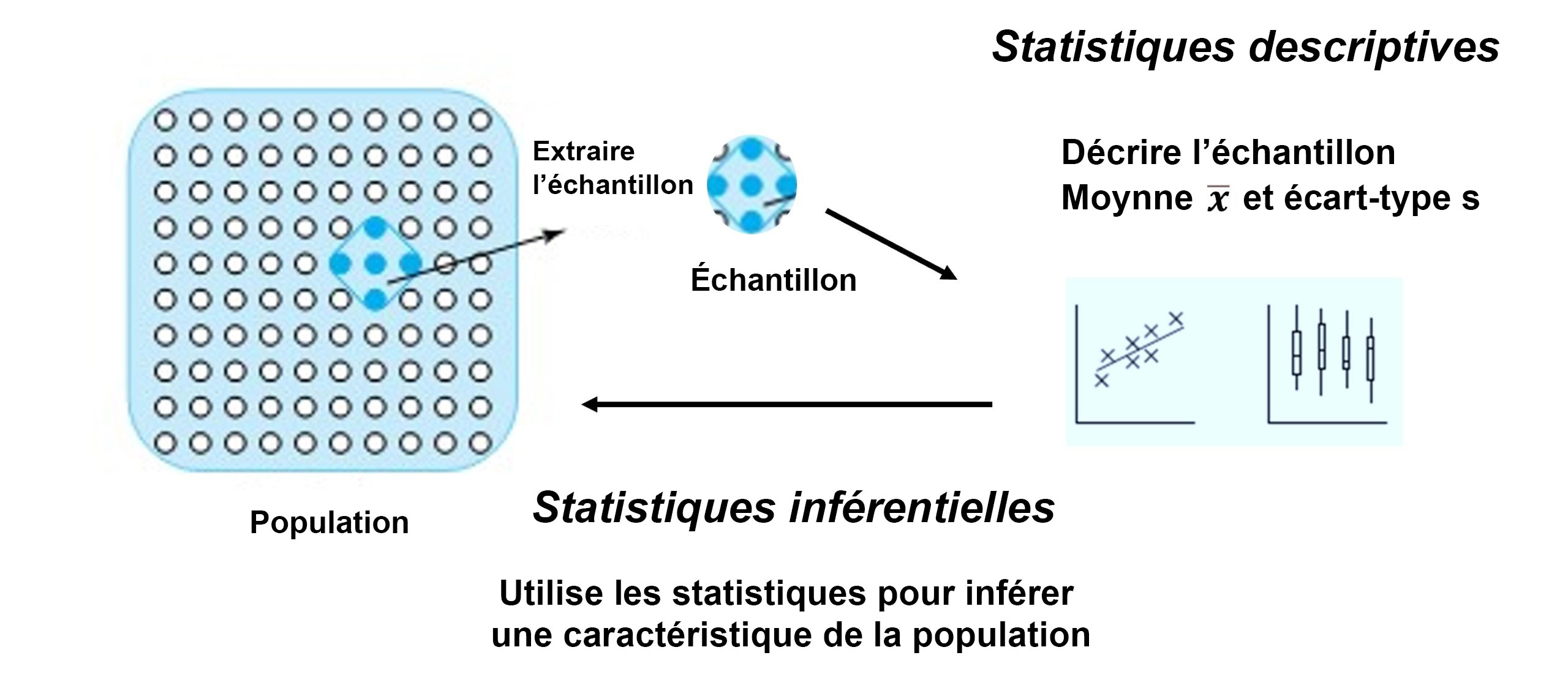
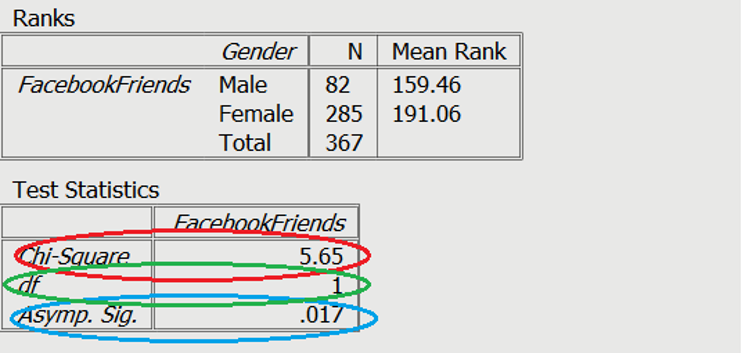
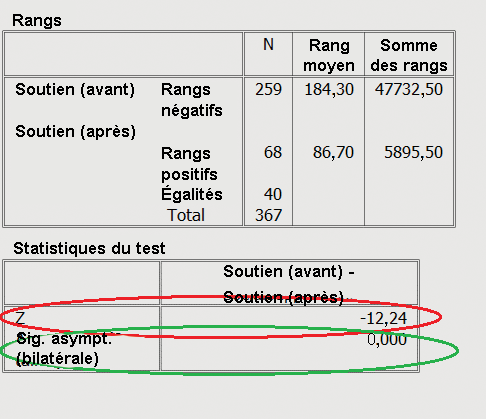
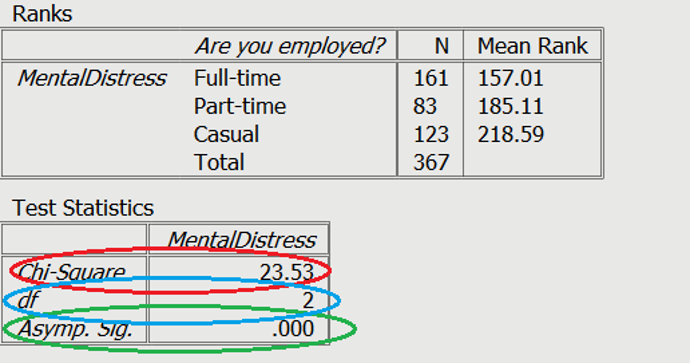
 =
= 
 , un objet initialement au repos en chute libre se déplacera à la vitesse
, un objet initialement au repos en chute libre se déplacera à la vitesse =
= 

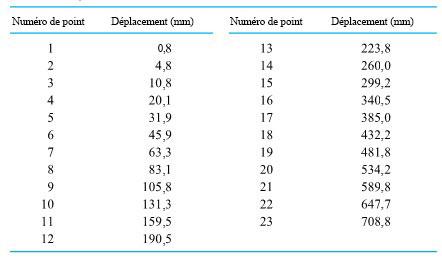
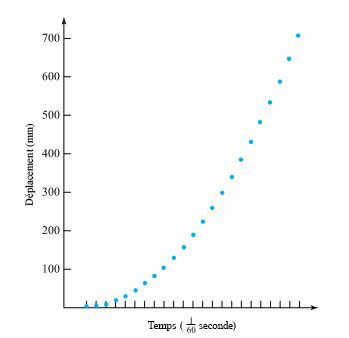
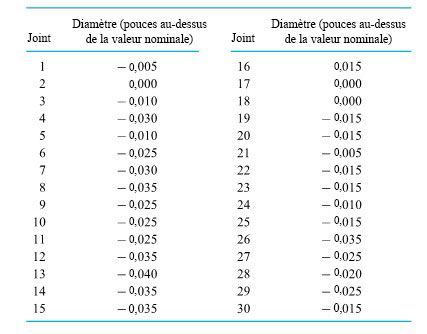
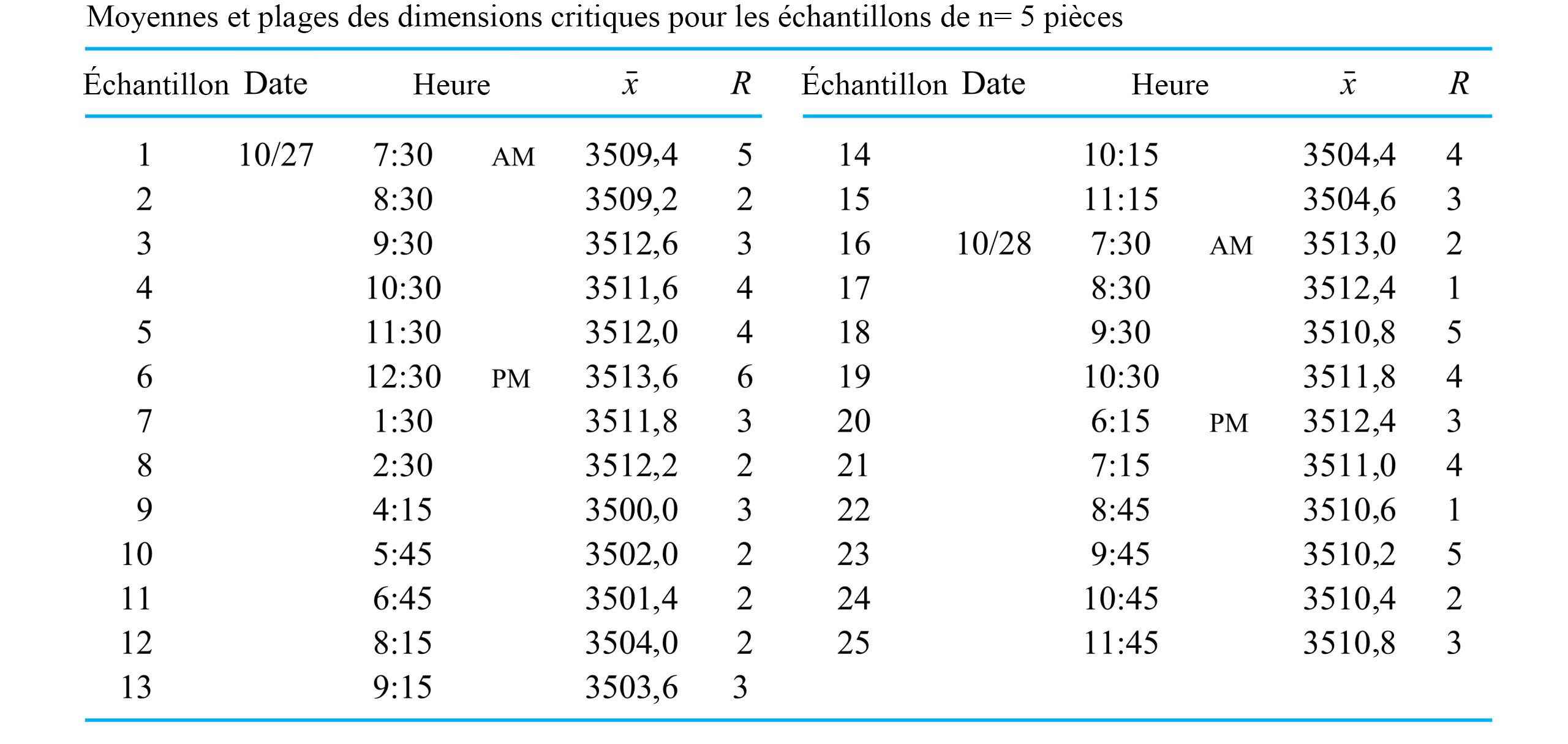
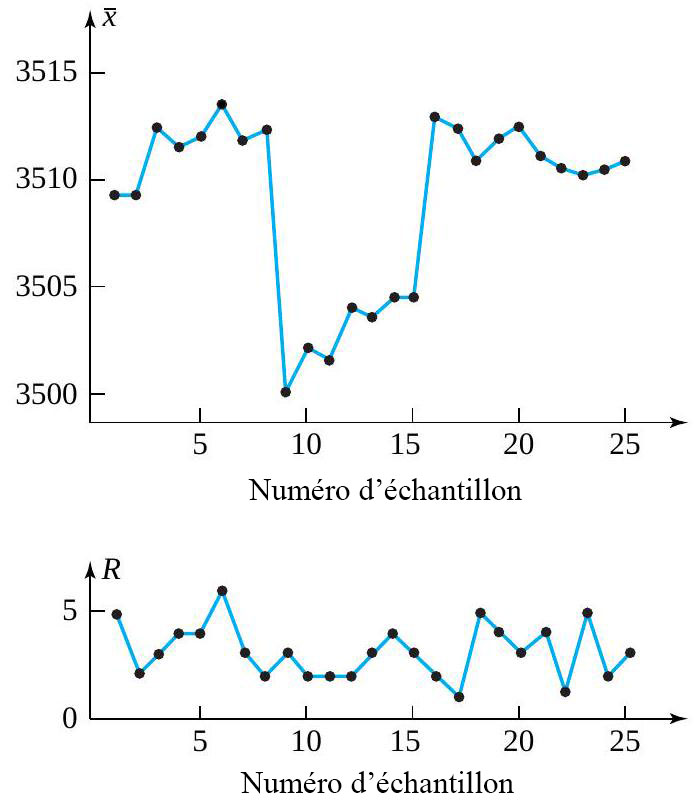
 d’une seconde. Le tableau 1.1.7.1 répertorie les mesures de ces positions. (Le ruban a été fourni par Frank Peterson, du département de physique et d’astronomie de l’ISU.) Le tracé des positions de la masse dans le tableau à intervalles égaux produit le tracé approximativement quadratique illustré à la figure 1.1.7.2. Pour obtenir la valeur de
d’une seconde. Le tableau 1.1.7.1 répertorie les mesures de ces positions. (Le ruban a été fourni par Frank Peterson, du département de physique et d’astronomie de l’ISU.) Le tracé des positions de la masse dans le tableau à intervalles égaux produit le tracé approximativement quadratique illustré à la figure 1.1.7.2. Pour obtenir la valeur de  /
/ pour g, très proche de la valeur communément admise de 9,8
pour g, très proche de la valeur communément admise de 9,8 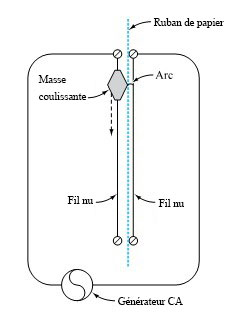
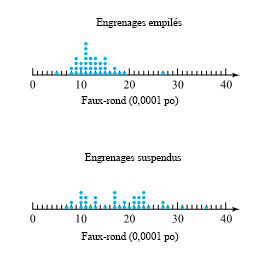
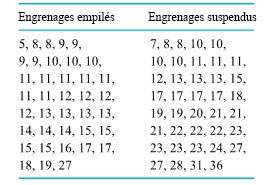
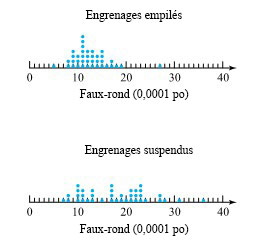
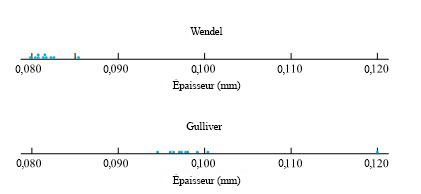
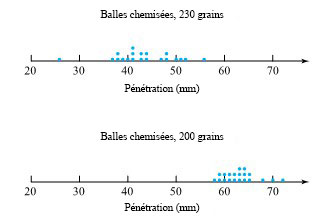
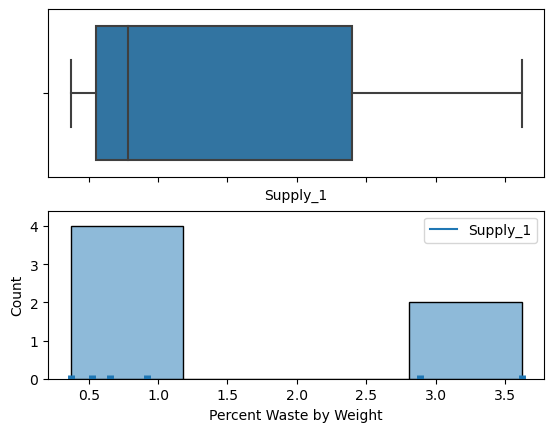
 de la surface de la cible jusqu’à l’arrière des balles) pour deux types de balles. La figure 2.1.2.2 présente une paire de diagrammes à points correspondants.
de la surface de la cible jusqu’à l’arrière des balles) pour deux types de balles. La figure 2.1.2.2 présente une paire de diagrammes à points correspondants.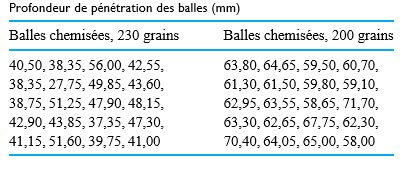

 » et «
» et «  » pour chaque premier chiffre possible, au lieu d’une seule feuille «
» pour chaque premier chiffre possible, au lieu d’une seule feuille «  » pour chaque premier chiffre.
» pour chaque premier chiffre.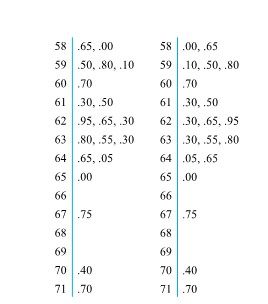
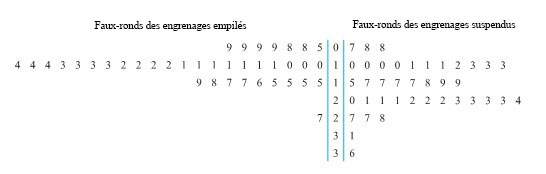
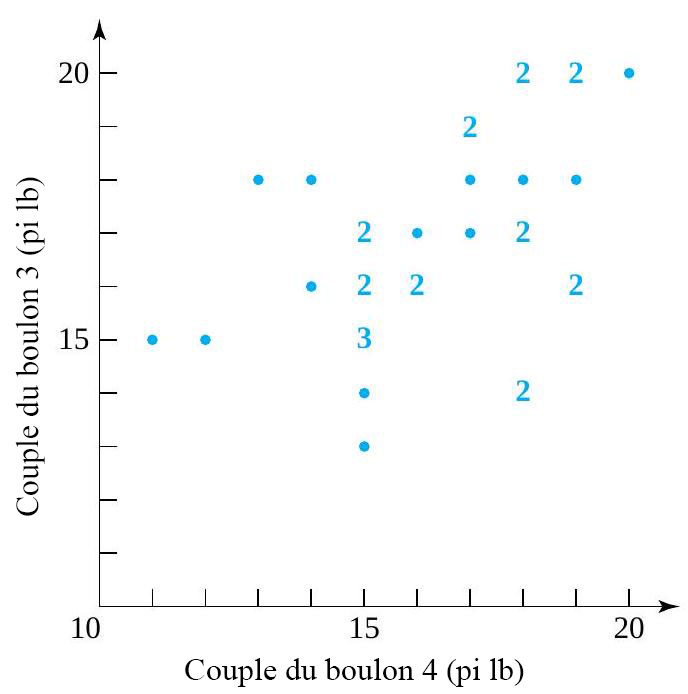
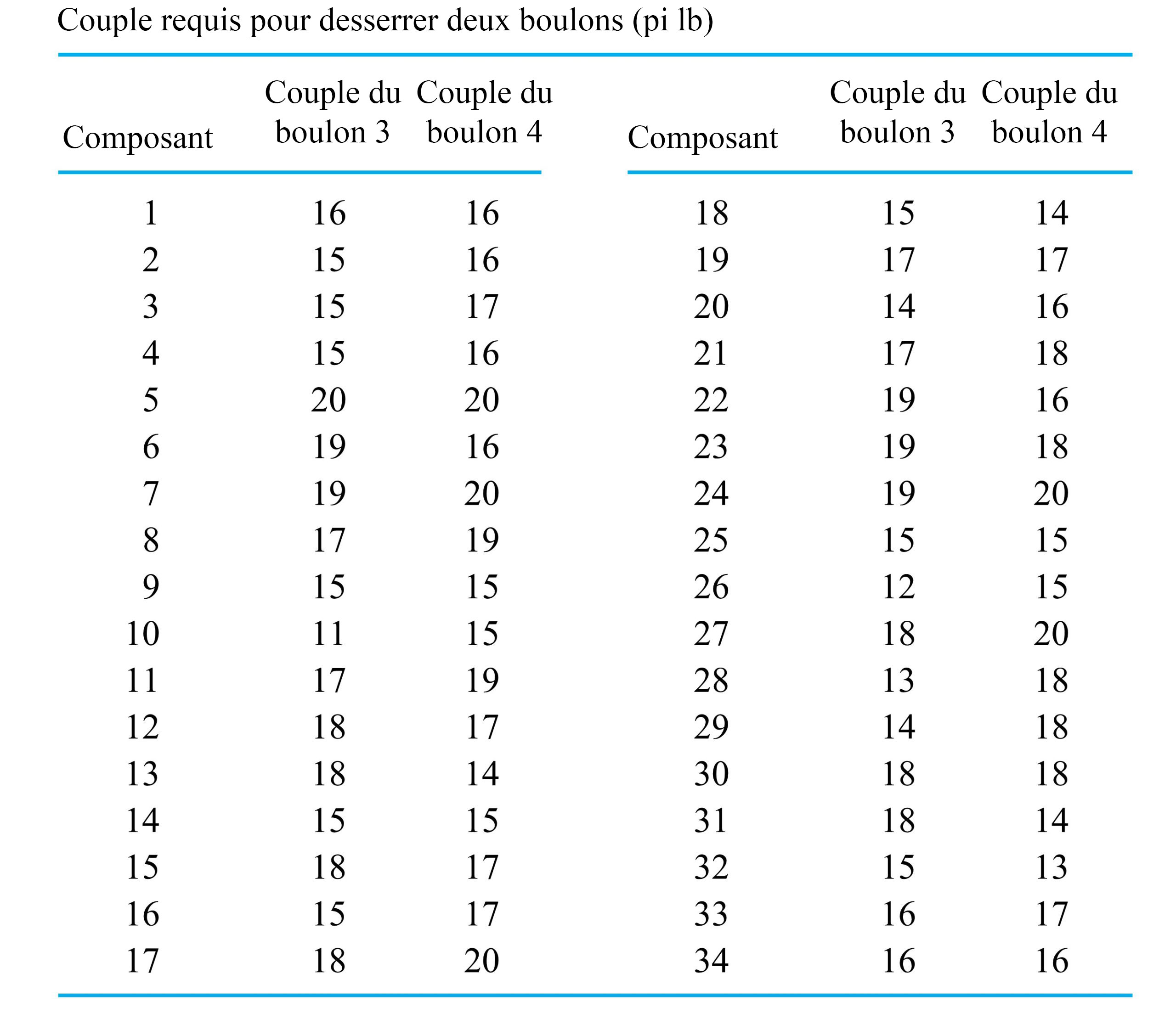
 ) requis pour les boulons numéros 3 et 4, respectivement, sur 34 composants différents. La figure 2.1.4.1 illustre un diagramme de dispersion des données à deux variables du tableau 2.1.4.1. Dans cette figure, s’il y avait plus d’un point au même endroit, on a indiqué le nombre de points à cet endroit.
) requis pour les boulons numéros 3 et 4, respectivement, sur 34 composants différents. La figure 2.1.4.1 illustre un diagramme de dispersion des données à deux variables du tableau 2.1.4.1. Dans cette figure, s’il y avait plus d’un point au même endroit, on a indiqué le nombre de points à cet endroit.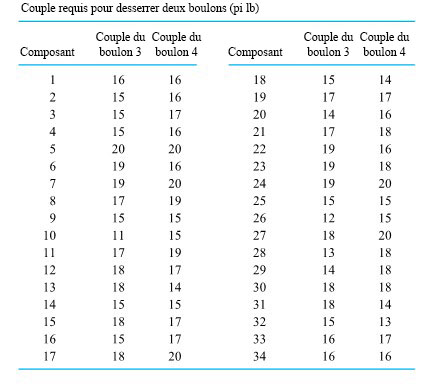
 des personnes qui ont passé l’examen ont obtenu une moins bonne note, et
des personnes qui ont passé l’examen ont obtenu une moins bonne note, et  ont obtenu une meilleure note. Ce concept est également utile pour décrire des données d’ingénierie. Toutefois, comme il est souvent plus pratique de travailler en termes de fractions entre 0 et 1 plutôt qu’en termes de pourcentages entre 0 et 100, on utilisera une terminologie légèrement différente : on parlera de « quantiles » plutôt que de rang centiles. Après avoir soigneusement défini les quantiles d’un ensemble de données, on les utilise pour créer divers outils utiles de statistiques descriptives : diagrammes quantile, diagrammes en boîte, diagrammes
ont obtenu une meilleure note. Ce concept est également utile pour décrire des données d’ingénierie. Toutefois, comme il est souvent plus pratique de travailler en termes de fractions entre 0 et 1 plutôt qu’en termes de pourcentages entre 0 et 100, on utilisera une terminologie légèrement différente : on parlera de « quantiles » plutôt que de rang centiles. Après avoir soigneusement défini les quantiles d’un ensemble de données, on les utilise pour créer divers outils utiles de statistiques descriptives : diagrammes quantile, diagrammes en boîte, diagrammes  , et diagrammes normaux (un type de diagramme
, et diagrammes normaux (un type de diagramme  compris entre 0 et 1 , le quantile
compris entre 0 et 1 , le quantile  , à droite. Toutefois, en raison du caractère discret des ensembles finis de données, il est nécessaire d’indiquer exactement ce que l’on veut dire par là. La définition 1 donne la convention qui sera utilisée dans ce texte.
, à droite. Toutefois, en raison du caractère discret des ensembles finis de données, il est nécessaire d’indiquer exactement ce que l’on veut dire par là. La définition 1 donne la convention qui sera utilisée dans ce texte. valeurs ordonnées
valeurs ordonnées  ,
, pour un entier positif
pour un entier positif  , le quantile
, le quantile  = Q\left(\frac{i - 0,5}{n}\right) = x_{i}")
 .)
.) et
et  qui n’est pas de la forme
qui n’est pas de la forme  entier, le quantile
entier, le quantile ") avec les valeurs
avec les valeurs ") .
. et
et  / n") . Pour trouver
. Pour trouver  / n") , ce qui donne
, ce qui donne
") e point de données ordonnées ».
e point de données ordonnées ». , il est facile de trouver les quantiles d’ordre
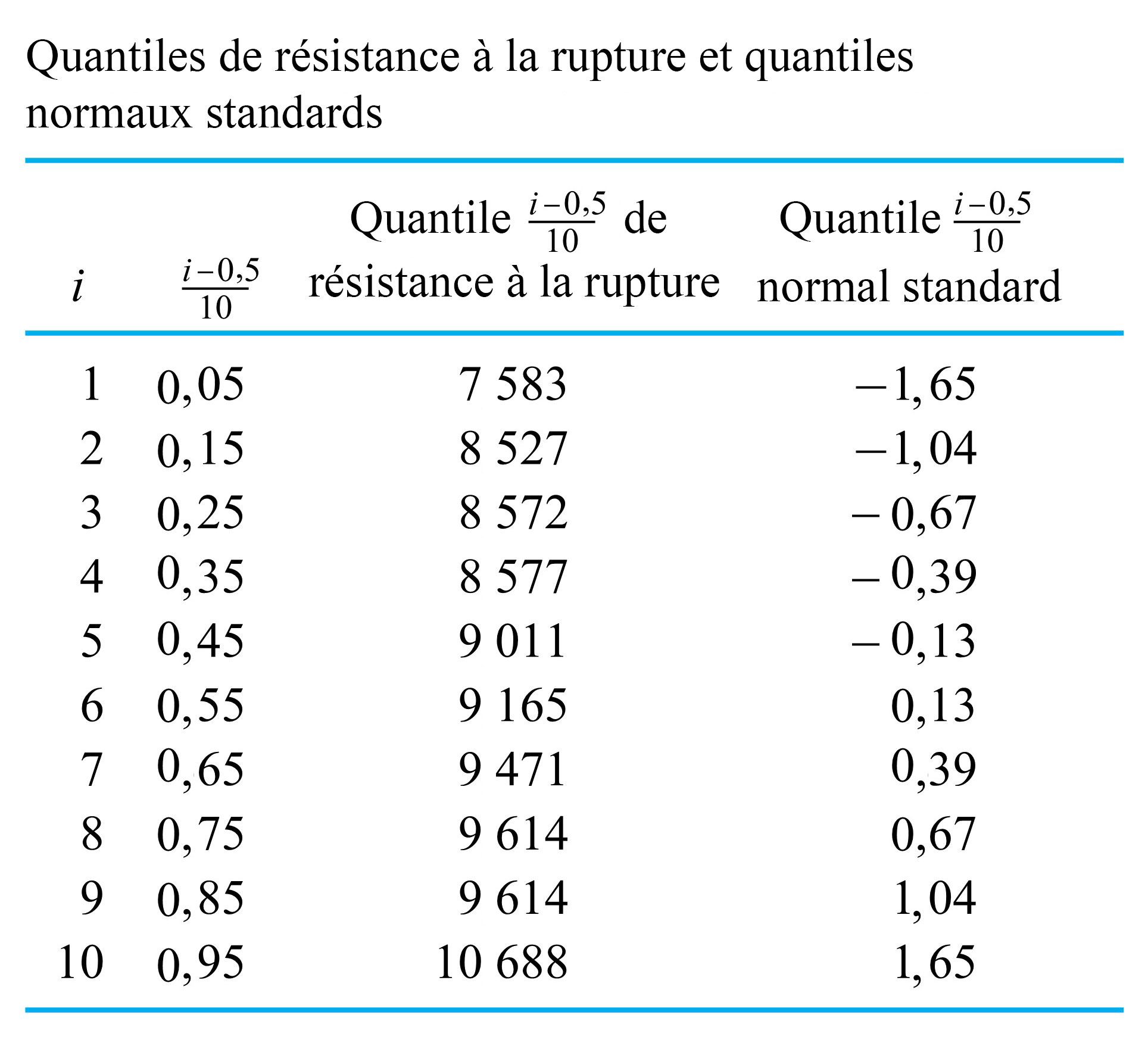
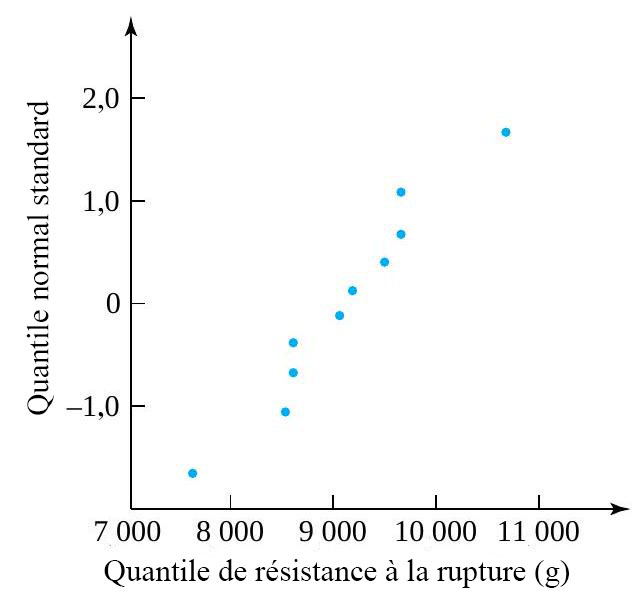
, il est facile de trouver les quantiles d’ordre  et 0,95 de la répartition de la force de rupture, comme illustré au tableau 2.1.5.2.
et 0,95 de la répartition de la force de rupture, comme illustré au tableau 2.1.5.2.
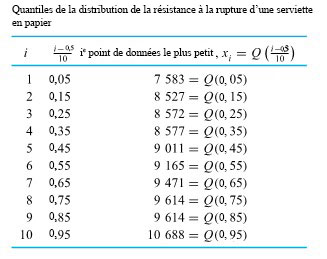
 points de données, chacun d’eux compte pour
points de données, chacun d’eux compte pour  de l’ensemble de données. Appliquons la convention (1) de la définition 3.1.5.1 pour trouver le quantile d’ordre 0,35 (par exemple). Les trois points de données les plus petits et la moitié du quatrième plus petit sont considérés comme se trouvant à gauche du nombre souhaité, et les six points de données les plus grands et la moitié du septième plus grand sont considérés comme se trouvant à droite. Ainsi, le quatrième point de données le plus petit doit être le quantile d’ordre 0,35, comme le montre le tableau 2.1.5.2.
de l’ensemble de données. Appliquons la convention (1) de la définition 3.1.5.1 pour trouver le quantile d’ordre 0,35 (par exemple). Les trois points de données les plus petits et la moitié du quatrième plus petit sont considérés comme se trouvant à gauche du nombre souhaité, et les six points de données les plus grands et la moitié du septième plus grand sont considérés comme se trouvant à droite. Ainsi, le quatrième point de données le plus petit doit être le quantile d’ordre 0,35, comme le montre le tableau 2.1.5.2. unité à mi-chemin entre 0,45 et 0,55, l’interpolation linéaire donne :
unité à mi-chemin entre 0,45 et 0,55, l’interpolation linéaire donne : = (1 - 0,5) Q(0,45) + 0,5 Q(0,55) = 0,5(9,011) + 0,5(9,165) = 9,088 \mathrm{~g}")
 unité à mi-chemin entre 0,85 et 0,93, l’interpolation linéaire donne :
unité à mi-chemin entre 0,85 et 0,93, l’interpolation linéaire donne : = (1 - 0,8) Q(0,85) +0,8 Q(0,95) = 0,2(9,614) + 0,8(10,688) = 10,473.2 \mathrm{~g}")
") est la médiane de la distribution.
est la médiane de la distribution.") et
et ") sont respectivement le premier et le troisième quartiles d’une distribution.
sont respectivement le premier et le troisième quartiles d’une distribution.") précédemment calculée, pour la distribution de la force de rupture, on a :
précédemment calculée, pour la distribution de la force de rupture, on a : = 9,088 \mathrm{~g} \\\text {Premier quartile } & = Q(0,25) = 8,572 \mathrm{~g} \\\text {Troisième quartile} & = Q(0,75) = 9,614 \mathrm{~g}\end{aligned}")
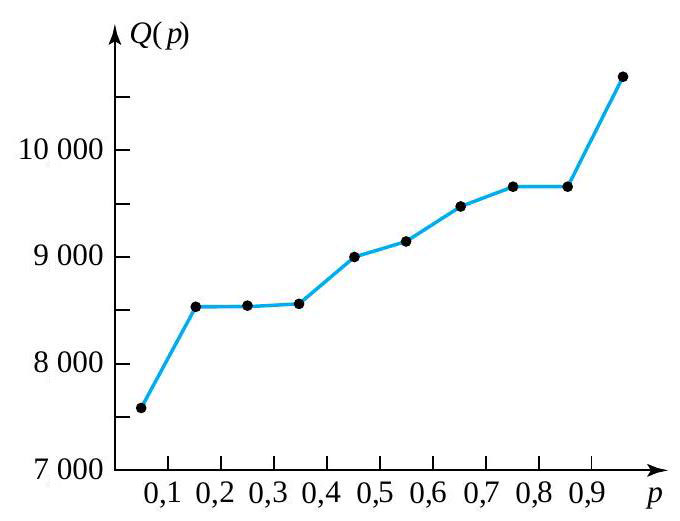
") puis en reliant les points consécutifs par des segments de droite.
puis en reliant les points consécutifs par des segments de droite.
 - Q(0,25)")

") et le plus grand point des données située dans un intervalle de 1,5 EI de
et le plus grand point des données située dans un intervalle de 1,5 EI de ![[Q(0,25) - 1,5 E I, Q(0,75) + 1,5 E I]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/826032d6cf208e4dadb71f9671c43480.png "[Q(0,25) - 1,5 E I, Q(0,75) + 1,5 E I]") . Ceux qui ne le sont pas sont ajoutés individuellement, ce qui indique qu’il s’agit de valeurs aberrantes ou inhabituelles.
. Ceux qui ne le sont pas sont ajoutés individuellement, ce qui indique qu’il s’agit de valeurs aberrantes ou inhabituelles. & = 8,572 \mathrm{~g} \\Q(0,5) & = 9,088 \mathrm{~g} \\Q(0,75) & = 9,614 \mathrm{~g}\end{aligned}")
 - Q(0,25) = 9,614 - 8,572 = 1,042 \mathrm{~g}")

 + 1.5 E I = 9,614 + 1,563=11,177 \mathrm{~g}")
 - 1,5 E I = 8,572 - 1,563 = 7,009 \mathrm{~g}")
 to
to  , le diagramme en boîtes ressemble donc à la figure 2.1.6.2.
, le diagramme en boîtes ressemble donc à la figure 2.1.6.2.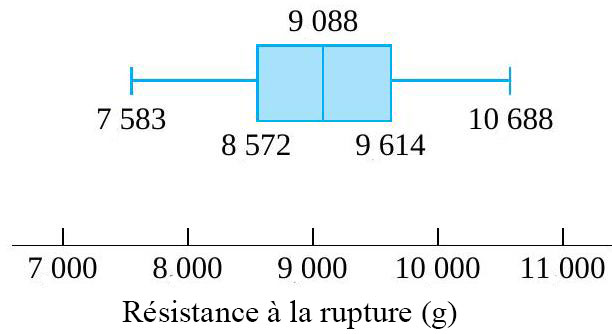
 du milieu de la distribution, et les moustaches. Certains éléments de la forme de la distribution sont indiqués par la symétrie (ou l’asymétrie) de la boîte et des moustaches. En outre, un espace entre l’extrémité d’une moustache et un point individuel rappelle qu’il n’y a aucune autre valeur dans cet intervalle.
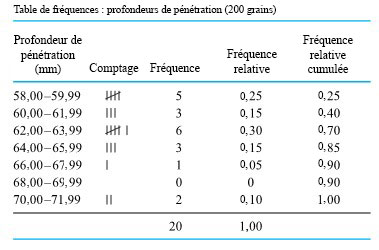
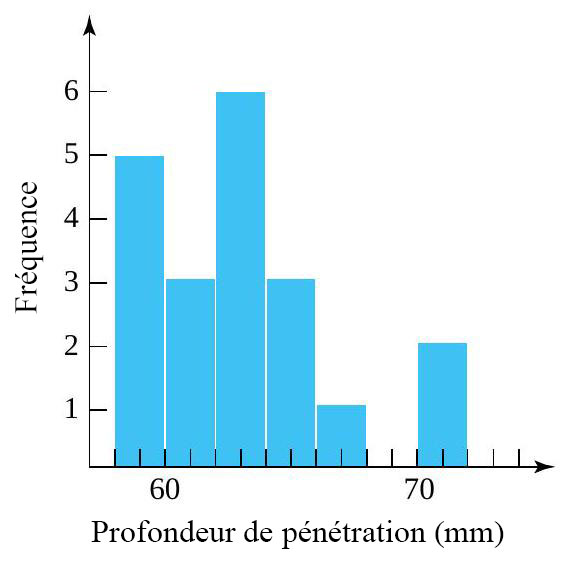
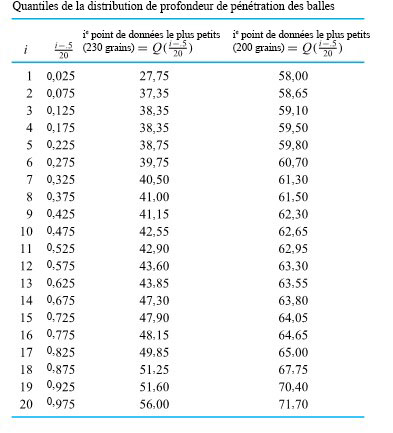
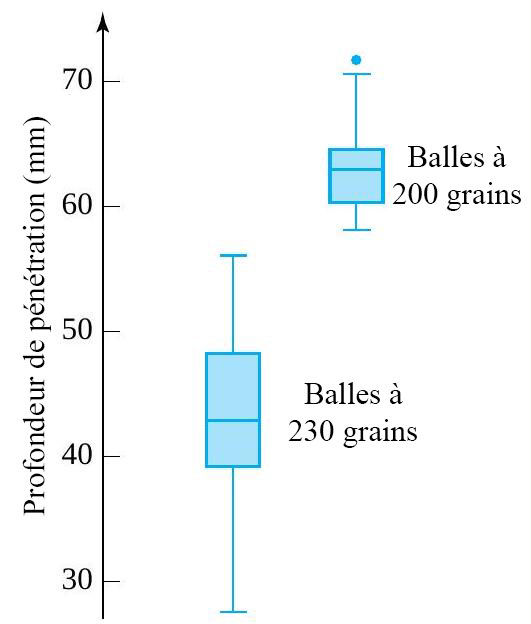
du milieu de la distribution, et les moustaches. Certains éléments de la forme de la distribution sont indiqués par la symétrie (ou l’asymétrie) de la boîte et des moustaches. En outre, un espace entre l’extrémité d’une moustache et un point individuel rappelle qu’il n’y a aucune autre valeur dans cet intervalle. des deux distributions de profondeur de pénétration des balles présentées à la section précédente. Pour les profondeurs de pénétration des balles de 230 grains, l’interpolation donne
des deux distributions de profondeur de pénétration des balles présentées à la section précédente. Pour les profondeurs de pénétration des balles de 230 grains, l’interpolation donne & = 0,5 Q(0,225)+0,5 Q(0,275) = 0,5(38,75) + 0,5(39,75) = 39,25 \mathrm{~mm} \\Q(0,5) & = 0,5 Q(0,475) + 0,5 Q(0,525) = 0,5(42,55) + 0,5(42,90) = 42,725 \mathrm{~mm} \\Q(0,75) & = 0,5 Q(0,725)+0,5 Q(0,775) = 0,5(47,90) + 0,5(48,15) = 48,025 \mathrm{~mm}\end{aligned}")
 + 1,5 E I & = 61,188 \mathrm{~mm} \\Q(0,25) - 1,5 E I & = 26,087 \mathrm{~mm}\end{aligned}")
 & = 60,25 \mathrm{~mm} \\Q(,5) & = 62,80 \mathrm{~mm} \\Q(0,75) & = 64,35 \mathrm{~mm} \\Q(0,75) + 1,5 E I & = 70,50 \mathrm{~mm} \\Q(0,25) - 1,5 E I & = 54,10 \mathrm{~mm}\end{aligned}")
 .
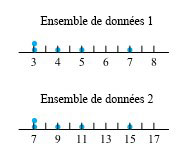
. e plus petite valeur de l’ensemble de données 1
e plus petite valeur de l’ensemble de données 1+1")
 et
et  représenter les fonctions de quantiles des deux ensembles de données, on voit clairement à la figure 2.1.7.1 que
représenter les fonctions de quantiles des deux ensembles de données, on voit clairement à la figure 2.1.7.1 que = 2 Q_(p) + 1")


, \quad Q_\left(\frac{i - 0,5}\right)\right)")
 ) devrait être exactement linéaire. La figure 2.1.7.2 illustre cela – en fait la figure 2.1.7.2 est un diagramme
) devrait être exactement linéaire. La figure 2.1.7.2 illustre cela – en fait la figure 2.1.7.2 est un diagramme , Q_(p)\right)") pour les valeurs appropriées de
pour les valeurs appropriées de  . Lorsque les ensembles de données sont de taille inégale, les valeurs de
. Lorsque les ensembles de données sont de taille inégale, les valeurs de  et
et  (pour les données des balles à 230 grains) est disproportionné par rapport à l’écart entre 63,55 et
(pour les données des balles à 230 grains) est disproportionné par rapport à l’écart entre 63,55 et  (pour les données des balles à 200 grains). Cela laisse supposer qu’il existe une différence physique fondamentale dans les mécanismes ayant causé la dispersion des données de profondeur des balles à 230 grains. Les statistiques peuvent révéler ce genre d’indice, mais pour expliquer les causes, il faut faire appel à des spécialistes de la balistique ou des matériaux.
(pour les données des balles à 200 grains). Cela laisse supposer qu’il existe une différence physique fondamentale dans les mécanismes ayant causé la dispersion des données de profondeur des balles à 230 grains. Les statistiques peuvent révéler ce genre d’indice, mais pour expliquer les causes, il faut faire appel à des spécialistes de la balistique ou des matériaux.") , il existe également une différence importante dans la forme des extrémités inférieures des deux distributions. Pour remettre ce point en ligne avec le reste des points tracés, il faudrait le déplacer vers la droite (augmenter la plus petite donnée des balles à 230 grains) ou vers le bas (diminuer la plus petite observation des balles à 200 grains). En d’autres termes, par rapport à la distribution des balles à 200 grains, la distribution des balles à 230 grains présente une longue queue inférieure. (Ou, autrement dit, par rapport à la distribution des balles à 230 grains, la distribution des balles à 200 grains a une queue inférieure courte.) À noter que la différence de forme était déjà évidente dans le diagramme en boîte de la figure précédente. Encore une fois, il faudrait un spécialiste pour expliquer cette différence dans les formes de distribution.
, il existe également une différence importante dans la forme des extrémités inférieures des deux distributions. Pour remettre ce point en ligne avec le reste des points tracés, il faudrait le déplacer vers la droite (augmenter la plus petite donnée des balles à 230 grains) ou vers le bas (diminuer la plus petite observation des balles à 200 grains). En d’autres termes, par rapport à la distribution des balles à 200 grains, la distribution des balles à 230 grains présente une longue queue inférieure. (Ou, autrement dit, par rapport à la distribution des balles à 230 grains, la distribution des balles à 200 grains a une queue inférieure courte.) À noter que la différence de forme était déjà évidente dans le diagramme en boîte de la figure précédente. Encore une fois, il faudrait un spécialiste pour expliquer cette différence dans les formes de distribution.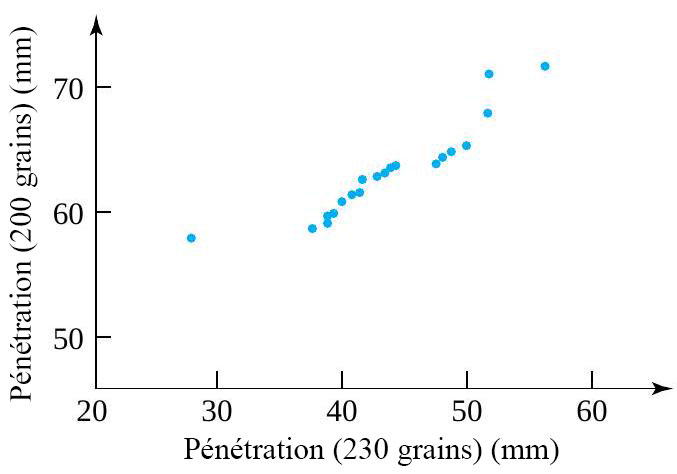
\right)")
 , on repère la ligne correspondant au premier chiffre après la décimale et la colonne correspondant au deuxième chiffre après la décimale. (Par exemple,
, on repère la ligne correspondant au premier chiffre après la décimale et la colonne correspondant au deuxième chiffre après la décimale. (Par exemple,  = -0,33") .) Pour approximer les valeurs du tableau 2.1.7.2, on peut utiliser la relation suivante :
.) Pour approximer les valeurs du tableau 2.1.7.2, on peut utiliser la relation suivante : \approx 4,9\left(p^{0,14} - (1 - p)^{0,14}\right)")
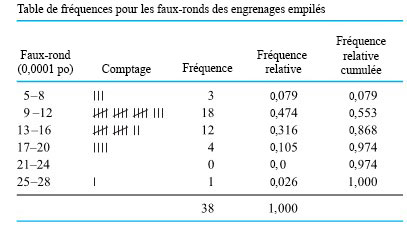
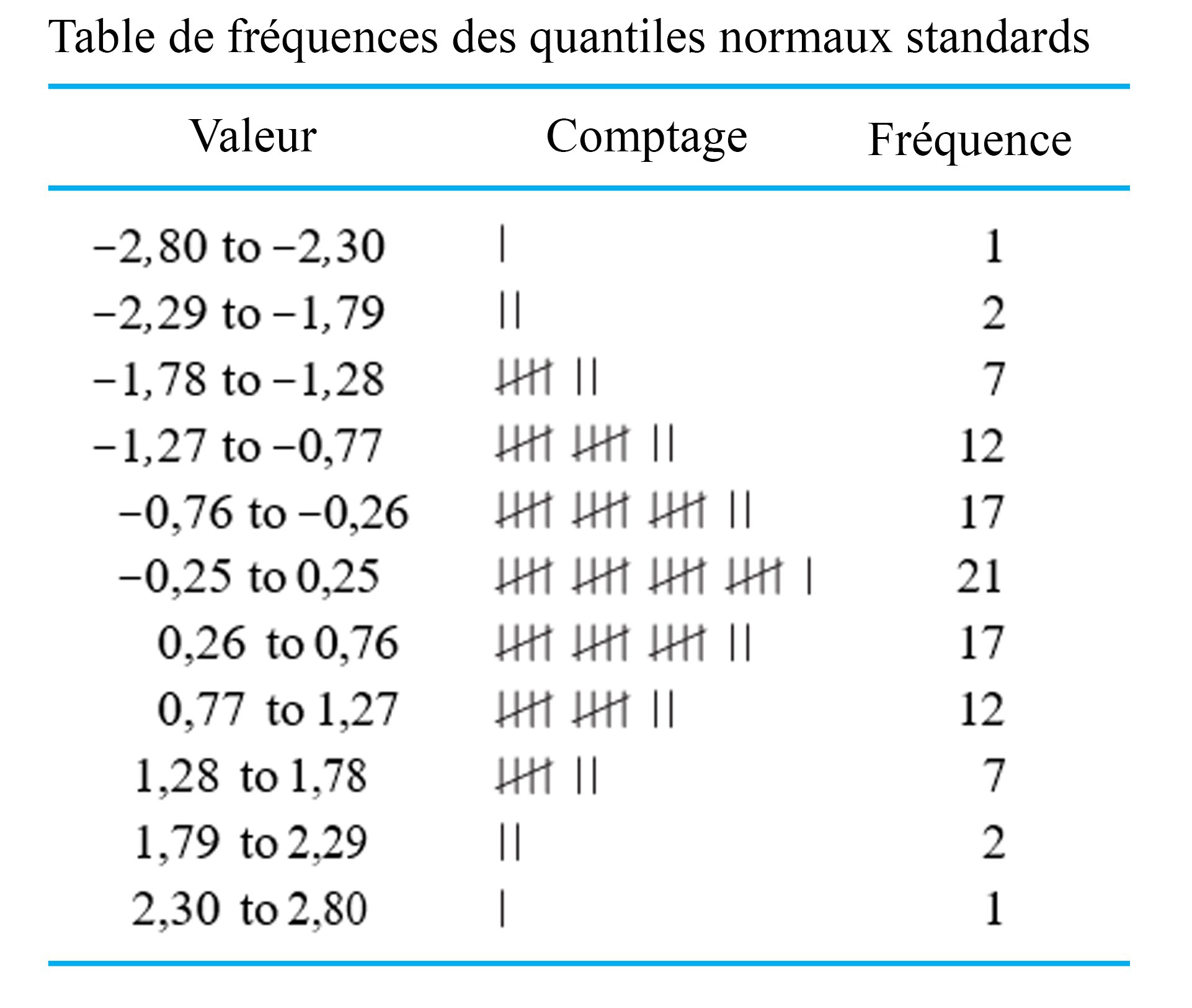
 . Le tableau 2.1.7.3 présente une table de fréquences pour ces 99 points de données. La colonne Comptage du tableau 2.1.7.3 montre clairement la forme de cloche.
. Le tableau 2.1.7.3 présente une table de fréquences pour ces 99 points de données. La colonne Comptage du tableau 2.1.7.3 montre clairement la forme de cloche.
![Q-Q[/latex]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/e8180ab99492aaee8d689a75d59cbc88.png "permet d’insister sur le lien entre les graphiques de probabilités et les graphiques <img src="https://atu0g9ctah.execute-api.ca-central-1.amazonaws.com/latest/latex?latex=Q-Q&fg=000000&font=TeX&svg=1" alt="Q-Q" title="Q-Q" class="latex mathjax" /> empiriques.")

 et si la valeur 2 est remplacée par
et si la valeur 2 est remplacée par  .
. , correspond à
, correspond à
 .
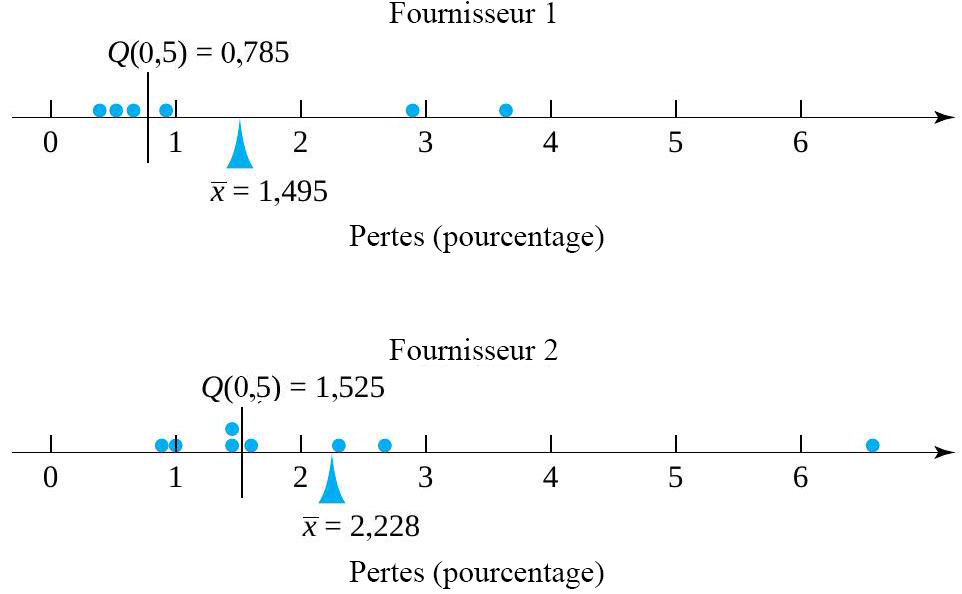
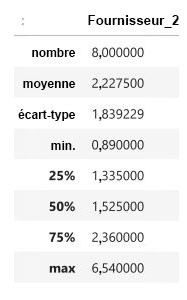
. = 0,5(0,65) + 0,5(0,92) = 0,785 \% \text { de pertes }")
 = 1,495 \% \text { de pertes }")
 = 0,5(1,47) + 0,5(1,58) = 1,525 \% \text { de pertes }")
 \\ & = 2,228 \% \text { de pertes }\end{aligned}")
 est
est
 = 18") ». Étant donné que l’étendue ne dépend que des valeurs du plus petit point et du plus grand point d’un ensemble de données, elle est nécessairement très sensible aux valeurs extrêmes (ou aberrantes). Parce qu’elle est facile à calculer, elle a longtemps été populaire dans les milieux industriels, notamment en tant qu’outil de contrôle statistique de la qualité.
». Étant donné que l’étendue ne dépend que des valeurs du plus petit point et du plus grand point d’un ensemble de données, elle est nécessairement très sensible aux valeurs extrêmes (ou aberrantes). Parce qu’elle est facile à calculer, elle a longtemps été populaire dans les milieux industriels, notamment en tant qu’outil de contrôle statistique de la qualité. est
est^{2 }")
 , est la racine carrée positive de la variance de l’échantillon.
, est la racine carrée positive de la variance de l’échantillon. par
par  est la distance au carré moyenne des points de données par rapport à la valeur centrale
est la distance au carré moyenne des points de données par rapport à la valeur centrale  = 0,52 \\& Q(0,75) = 2,89\end{aligned}")


^+(0,52-1,495)^+(0,65-1,495)^+(0,92-1,495)^\right. \\& \left.+(2,89-1,495)^+(3,62-1,495)^\right) \\= & 1,945(\% \text { de pertes })^\end{aligned}")



^+(0,99-2,228)^+(1,45-2,228)^+(1,47-2,228)^\right. \\& \left.+(1,58-2,228)^+(2,27-2,228)^+(2,63-2,228)^+(6,54-2,228)^\right) \\= & 3,383(\% \text { de pertes })^\end{aligned}")

 et
et ") pour représenter la moyenne de la population et de noter :
pour représenter la moyenne de la population et de noter :
 plutôt que
plutôt que ") ) pour représenter la variance de la population et pour définir:
) pour représenter la variance de la population et pour définir:^2")
 correspond donc à l’écart-type de la population,
correspond donc à l’écart-type de la population,  .
.

 ou
ou  qui doivent être comparées. Les diagrammes en barres et les diagrammes simples à deux variables peuvent être d’une grande aide pour résumer ces résultats.
qui doivent être comparées. Les diagrammes en barres et les diagrammes simples à deux variables peuvent être d’une grande aide pour résumer ces résultats.") , car les catégories A à E constituent un ensemble de catégories exhaustives et mutuellement exclusives, de sorte que la somme des
, car les catégories A à E constituent un ensemble de catégories exhaustives et mutuellement exclusives, de sorte que la somme des 
 , celle des défauts modérément graves, mais ni graves ni très graves. Ce diagramme à barres présente le comportement d’une variable catégorique.
, celle des défauts modérément graves, mais ni graves ni très graves. Ce diagramme à barres présente le comportement d’une variable catégorique.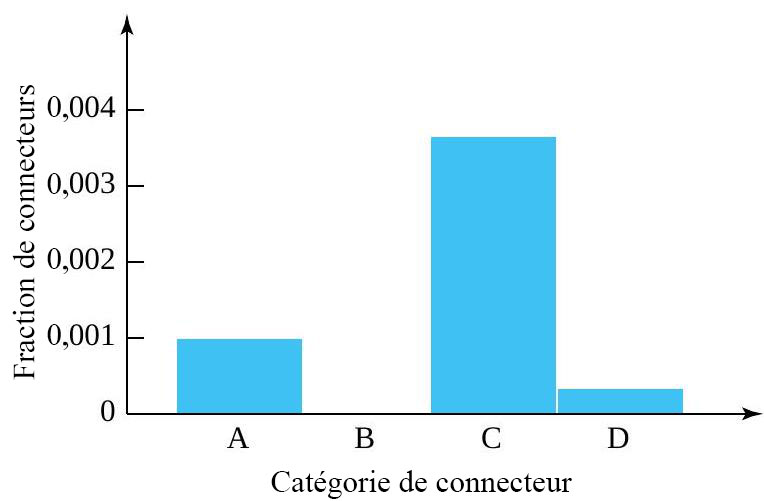
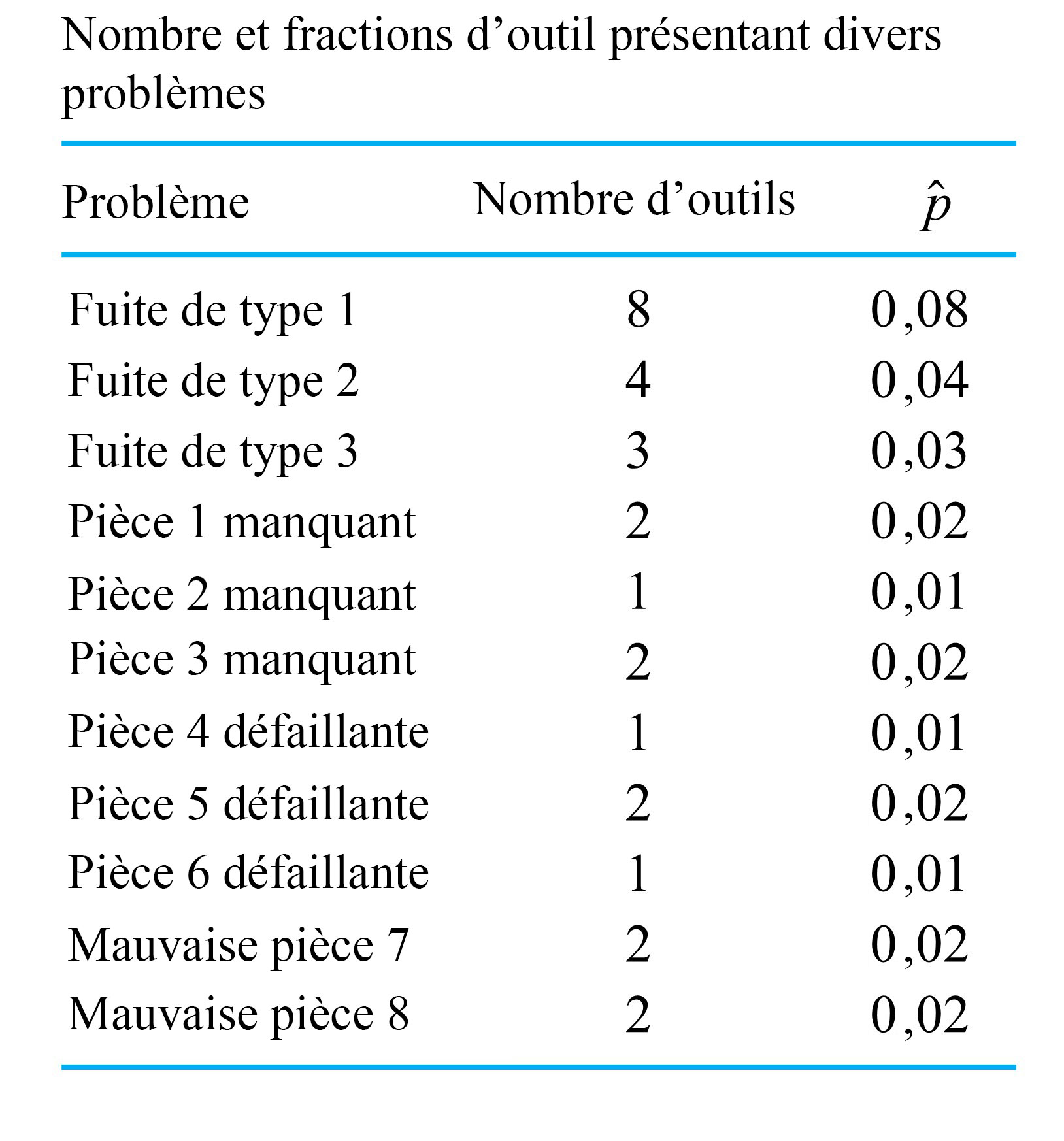
 , donc la proportion d’outils ne présentant pas le type de fuite 1 est
, donc la proportion d’outils ne présentant pas le type de fuite 1 est  . Le total des valeurs
. Le total des valeurs 

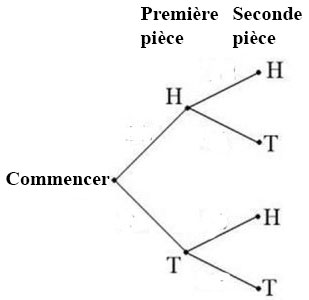
 où P = pile et F = face sont les résultats. L’espace échantillon correspondant à lancer une fois deux pièces de monnaie s’exprime comme suit : S = {(PP),(PF),(FP),(FF)}. Nous utiliserons également des lettres majuscules pour désigner un événement, comme A et B. Par exemple, on peut définir l’événement A comme le fait d’obtenir pile sur la première pièce, et l’événement B, comme le fait d’obtenir pile sur la deuxième pièce. Cela se traduirait par
où P = pile et F = face sont les résultats. L’espace échantillon correspondant à lancer une fois deux pièces de monnaie s’exprime comme suit : S = {(PP),(PF),(FP),(FF)}. Nous utiliserons également des lettres majuscules pour désigner un événement, comme A et B. Par exemple, on peut définir l’événement A comme le fait d’obtenir pile sur la première pièce, et l’événement B, comme le fait d’obtenir pile sur la deuxième pièce. Cela se traduirait par  et
et  . Les diagrammes sont utiles pour représenter ensemble les opérations de plusieurs événements.
. Les diagrammes sont utiles pour représenter ensemble les opérations de plusieurs événements. n’est ni dans
n’est ni dans  ni dans
ni dans  . Le diagramme de Venn est alors représenté comme suit :
. Le diagramme de Venn est alors représenté comme suit :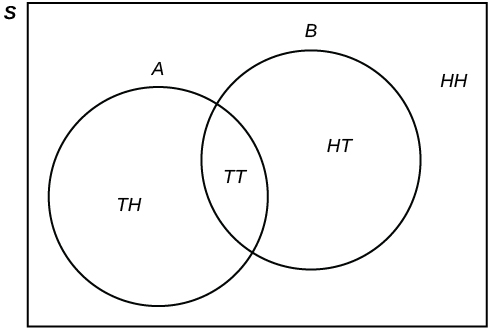
 et
et  . Par conséquent,
. Par conséquent,  =
=  =
=  =
=  .
.  =
=  =
=  .
.
 . Les événements marginaux sont ceux qui figurent en marge du tableau et qui se produisent pour un seul événement, sans tenir compte des autres événements du tableau. Dans cet exemple, le tableau contient un événement marginal A auquel sont associés les événements conjoints
. Les événements marginaux sont ceux qui figurent en marge du tableau et qui se produisent pour un seul événement, sans tenir compte des autres événements du tableau. Dans cet exemple, le tableau contient un événement marginal A auquel sont associés les événements conjoints 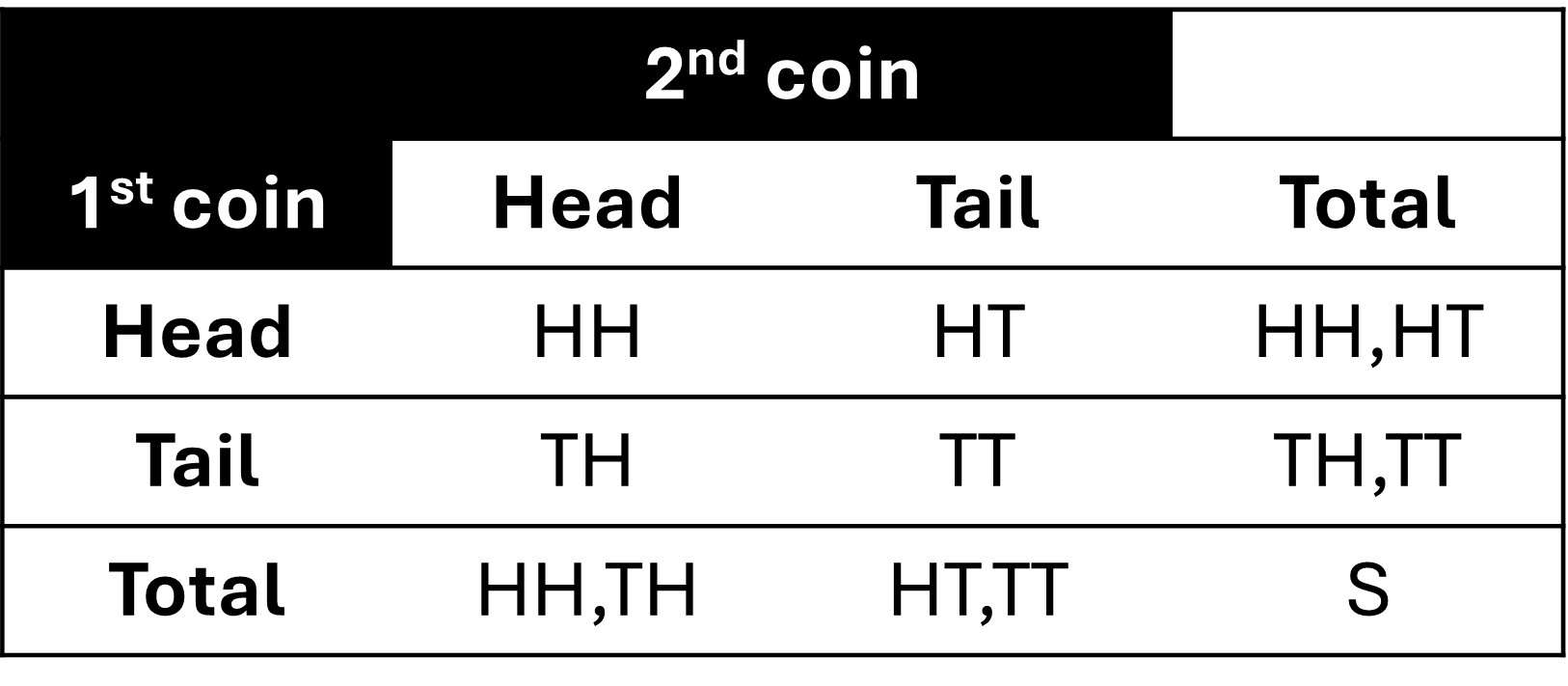
 .
. .
. .
. .
. est l’ensemble des résultats qui se trouvent à la fois dans
est l’ensemble des résultats qui se trouvent à la fois dans  est l’ensemble des résultats qui ne sont dans
est l’ensemble des résultats qui ne sont dans  . Par conséquent,
. Par conséquent,  est l’ensemble de résultats qui ne sont pas dans
est l’ensemble de résultats qui ne sont pas dans  , où m est le nombre de résultats d’occurrences de l’événement A, et n le nombre total de résultats de l’expérience. L’approche fréquentiste affirme qu’au fur et à mesure que le nombre d’essais augmente, la variation de la fréquence relative diminue. La probabilité est donc la valeur limite des fréquences relatives correspondantes. On peut déterminer la fréquence relative soit en réalisant des expériences réelles et en trouvant une probabilité empirique (ou estimée), soit en reconnaissant le modèle théorique de l’expérience et en adoptant une probabilité théorique basée sur les événements de l’espace échantillon.
, où m est le nombre de résultats d’occurrences de l’événement A, et n le nombre total de résultats de l’expérience. L’approche fréquentiste affirme qu’au fur et à mesure que le nombre d’essais augmente, la variation de la fréquence relative diminue. La probabilité est donc la valeur limite des fréquences relatives correspondantes. On peut déterminer la fréquence relative soit en réalisant des expériences réelles et en trouvant une probabilité empirique (ou estimée), soit en reconnaissant le modèle théorique de l’expérience et en adoptant une probabilité théorique basée sur les événements de l’espace échantillon.
 = 0,5.
= 0,5.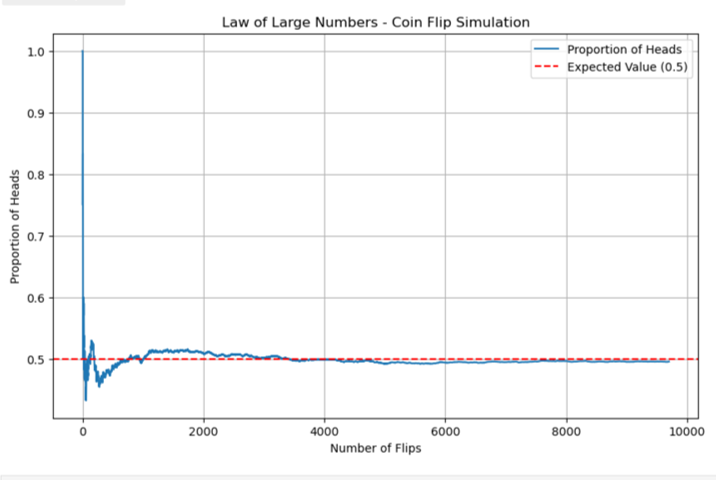
") et correspond à un nombre compris entre zéro et un (inclusivement) qui décrit la proportion de fois où l’on s’attend à ce que l’événement se produise sur le long terme. P(A) = 0 signifie que l’événement A ne peut jamais se produire. P(A) = 1 signifie que l’événement A se produit toujours. P(A) = 0.5 signifie que l’événement A a la même probabilité de se produire ou de ne pas se produire. Par exemple, si vous tirez à pile ou face de manière répétée (20, 2 000 ou 20 000 fois), la fréquence relative de faces tends vers 0,5 (soit la probabilité d’obtenir face).
et correspond à un nombre compris entre zéro et un (inclusivement) qui décrit la proportion de fois où l’on s’attend à ce que l’événement se produise sur le long terme. P(A) = 0 signifie que l’événement A ne peut jamais se produire. P(A) = 1 signifie que l’événement A se produit toujours. P(A) = 0.5 signifie que l’événement A a la même probabilité de se produire ou de ne pas se produire. Par exemple, si vous tirez à pile ou face de manière répétée (20, 2 000 ou 20 000 fois), la fréquence relative de faces tends vers 0,5 (soit la probabilité d’obtenir face). est de 1 et la probabilité de l’ensemble vide est de 0. Autrement dit, P(S) = 1 et P(∅) = 0.
est de 1 et la probabilité de l’ensemble vide est de 0. Autrement dit, P(S) = 1 et P(∅) = 0. = \sum_{n= 1}^\infty P(A_n)")
 = \frac{P(A \cap B)}{P(B)}")
") » signifie « probabilité de A, étant donné B ».
» signifie « probabilité de A, étant donné B ». = P(A)P(B)") .
. = P(A)") .
. = P(B)") .
. sont mutuellement indépendants si pour tout sous-ensemble
sont mutuellement indépendants si pour tout sous-ensemble  :
: = P(A_{i_1}) \cdot P(A_{i_2}) \cdot \ldots \cdot P(A_{i_k})")
 cartes bien mélangées. Il se compose de quatre couleurs : le trèfle, le carreau, le cœur et le pique. Chaque couleur comporte
cartes bien mélangées. Il se compose de quatre couleurs : le trèfle, le carreau, le cœur et le pique. Chaque couleur comporte  cartes :
cartes : ,
,  (valet),
(valet),  (dame),
(dame),  (roi) de cette couleur.
(roi) de cette couleur. cartes restantes du jeu. Il s’agit du 3 de carreau. On met cette carte de côté, puis on choisit une troisième carte parmi dans les
cartes restantes du jeu. Il s’agit du 3 de carreau. On met cette carte de côté, puis on choisit une troisième carte parmi dans les  cartes restantes du jeu. La troisième carte est un
cartes restantes du jeu. La troisième carte est un 

![{\displaystyle [0,1]\subseteq \mathbb {R} }](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/511efe69c491a34ed7846e6fe78029c8.png "{\displaystyle [0,1]\subseteq \mathbb {R} }") associée à chacune des valeurs possibles de la variable aléatoire. Les variable aléatoires sont exprimées sous la forme de lettres latines majuscules, souvent celles de la fin de l’alphabet, comme
associée à chacune des valeurs possibles de la variable aléatoire. Les variable aléatoires sont exprimées sous la forme de lettres latines majuscules, souvent celles de la fin de l’alphabet, comme  .
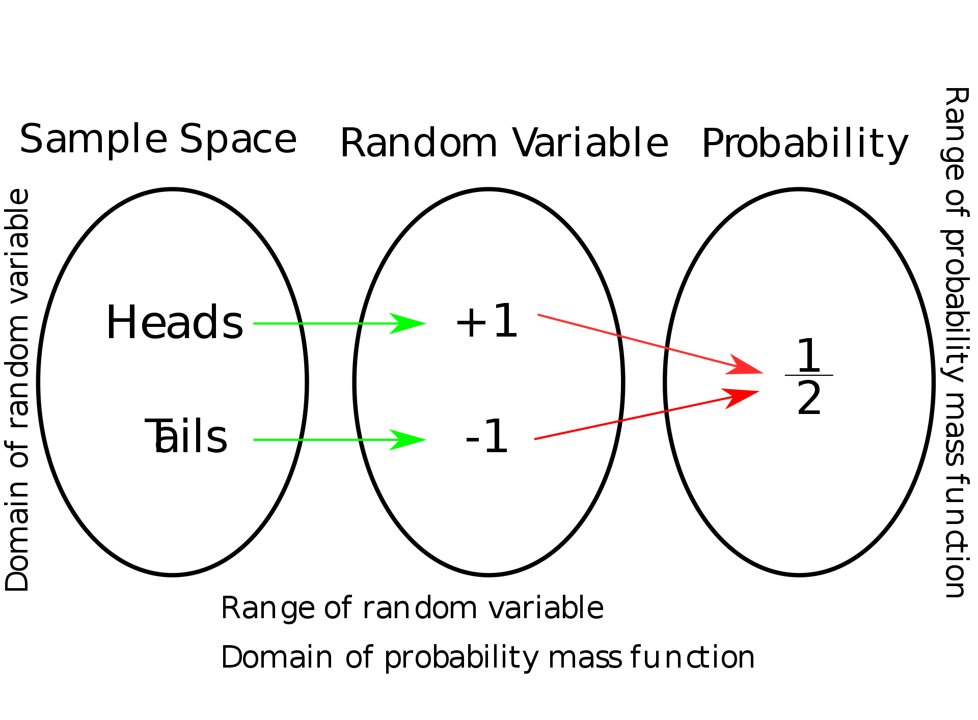
. une valeur mesurable de l’espace
une valeur mesurable de l’espace  , où 1 correspond à P et -1 correspond à F, en utilisant la variable aléatoire
, où 1 correspond à P et -1 correspond à F, en utilisant la variable aléatoire  =
=  = +1, qu’on note
= +1, qu’on note ") .
.
") pour un événement.
pour un événement.") .
.![{\displaystyle F\colon \mathbb {R} \rightarrow [0,1]}](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/77202eb9c5f3bc68098624bfd57bc61a.png "{\displaystyle F\colon \mathbb {R} \rightarrow [0,1]}") telle que
telle que =0}") et
et =1}") . Toute fonction possédant ces quatre propriétés est une FDC : pour chaque fonction de ce type, on peut définir une variable aléatoire qui a cette fonction pour fonction de distribution cumulative.
. Toute fonction possédant ces quatre propriétés est une FDC : pour chaque fonction de ce type, on peut définir une variable aléatoire qui a cette fonction pour fonction de distribution cumulative.![F(x)=P[X \leq x]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/02661d769255dee69404659ee6e5a9c0.png "F(x)=P[X \leq x]")

 ,
, ,…, est une fonction non-négative f(x) telle que f (
,…, est une fonction non-négative f(x) telle que f ( ) donne la probabilité que X prenne la valeur
) donne la probabilité que X prenne la valeur 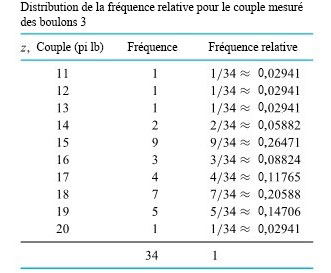
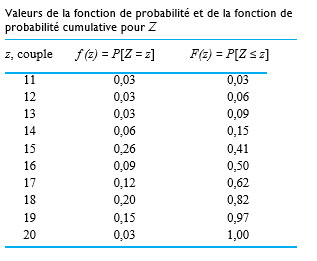
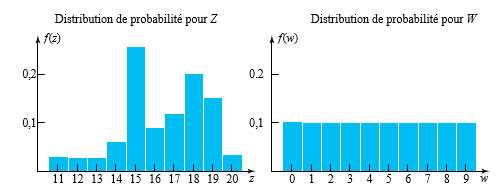
 le prochain couple mesuré pour le boulon 3 (arrondi à l’entier le plus proche), que nous traiterons comme une variable aléatoire discrète. Il faut maintenant trouver une fonction de probabilité plausible pour Z. Les fréquences relatives des mesures de couple enregistrées sur le boulon 3 permettent d’établir la distribution des fréquences relative :
le prochain couple mesuré pour le boulon 3 (arrondi à l’entier le plus proche), que nous traiterons comme une variable aléatoire discrète. Il faut maintenant trouver une fonction de probabilité plausible pour Z. Les fréquences relatives des mesures de couple enregistrées sur le boulon 3 permettent d’établir la distribution des fréquences relative :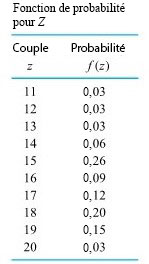
 la valeur de couple sélectionnée.
la valeur de couple sélectionnée.= \begin{cases}0,1 & \text { pour } w=0,1,2, \ldots, 9 \\ 0 & \text { sinon }\end{cases}")
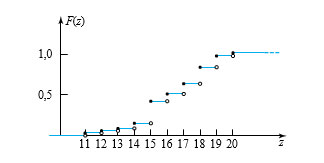
![F(16,3)=P[Z \leq 16,3]=P[Z \leq 16]=F(16)=0,50](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/9c1af41b6e51559dd079a4a47f1aafb9.png "F(16,3)=P[Z \leq 16,3]=P[Z \leq 16]=F(16)=0,50")
![F(32)=P[Z \leq 32]=1,00](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/c83689afaf4bfd6d03d0cabb8e1a9906.png "F(32)=P[Z \leq 32]=1,00")
")
=\sum_z z f(z)")
)^2 f(x) \quad\left(=\sum x^2 f(x)-(E(X))^2\right)")
}") . On utilise souvent la notation
. On utilise souvent la notation  à la place de Var(X), et
à la place de Var(X), et }=\sqrt{4,6275}") = 2,15 ft lb
= 2,15 ft lb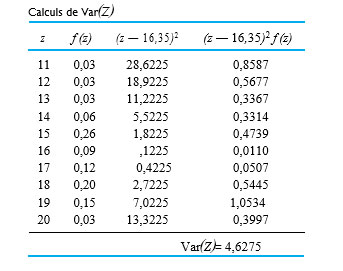
") .
.
=\sum w^2 f(w)-(E(W))^2=28,5-(4,5)^2=8,25")
} = 2,87")
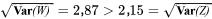 2,15=\sqrt{\operatorname{Var}(Z)} » title= »\sqrt{\operatorname{Var}(W)}=2,87>2,15=\sqrt{\operatorname{Var}(Z)} » class= »latex mathjax »>
2,15=\sqrt{\operatorname{Var}(Z)} » title= »\sqrt{\operatorname{Var}(W)}=2,87>2,15=\sqrt{\operatorname{Var}(Z)} » class= »latex mathjax »>= \begin{cases}\frac{n !}{x !(n-x) !} p^{x}(1-p)^{n-x} & \text { pour } x=0,1, \ldots, n \\ 0 & \text { sinon }\end{cases}")
") pour chaque essai produisant un échec. Le terme
pour chaque essai produisant un échec. Le terme  !") est un décompte du nombre de combinaisons dans lesquelles il est possible de voir
est un décompte du nombre de combinaisons dans lesquelles il est possible de voir  nomiale trouve son origine dans le fait que les valeurs
nomiale trouve son origine dans le fait que les valeurs , f(1), f(2), \ldots, f(n)") sont les termes du développement de
sont les termes du développement de)^{n}")
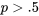 0,5" title="p>0,5" class="latex mathjax">, l’histogramme résultant est asymétrique à gauche. L’asymétrie augmente à mesure que
0,5" title="p>0,5" class="latex mathjax">, l’histogramme résultant est asymétrique à gauche. L’asymétrie augmente à mesure que 
 soit une probabilité crédible qu’un arbre soit réusinable. Supposons en outre qu’on inspecte
soit une probabilité crédible qu’un arbre soit réusinable. Supposons en outre qu’on inspecte 
![\begin{aligned}P[\text { au moins deux arbres réusinables] } & =P[U \geq 2] \\& =f(2)+f(3)+\cdots+f(10) \\& =1-(f(0)+f(1)) \\& =1-\left(\frac{10 !}{0 ! 10 !}(0,2)^{0}(0,8)^{10 }+\frac{10 !}{1 ! 9 !}(0,2)^{1 }(0,8)^{9 }\right) \\&=0,62\end{aligned}](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/6e6263a4d29e02e515efc04bf606f376.png) \begin{aligned}P[\text { au moins deux arbres réusinables] } & =P[U \geq 2] \\& =f(2)+f(3)+\cdots+f(10) \\& =1-(f(0)+f(1)) \\& =1-\left(\frac{10 !}{0 ! 10 !}(0,2)^{0}(0,8)^{10 }+\frac{10 !}{1 ! 9 !}(0,2)^{1 }(0,8)^{9 }\right) \\&=0,62\end{aligned}
\begin{aligned}P[\text { au moins deux arbres réusinables] } & =P[U \geq 2] \\& =f(2)+f(3)+\cdots+f(10) \\& =1-(f(0)+f(1)) \\& =1-\left(\frac{10 !}{0 ! 10 !}(0,2)^{0}(0,8)^{10 }+\frac{10 !}{1 ! 9 !}(0,2)^{1 }(0,8)^{9 }\right) \\&=0,62\end{aligned}") doit être égale à 1.)
doit être égale à 1.) , et le nombre 0,62 est alors peu pertinent. (L’hypothèse de l’indépendance des essais serait inappropriée dans cette situation.)
, et le nombre 0,62 est alors peu pertinent. (L’hypothèse de l’indépendance des essais serait inappropriée dans cette situation.)
") .
. .
.
 est obtenue comme suit. Les valeurs possibles pour
est obtenue comme suit. Les valeurs possibles pour ![\begin{aligned}f(0)= & P[V=0] \\= & P[\text {la première pastille sélectionnée est non conforme et } \\& \text { la deuxième pastille est également non conforme}] \\f(2)= & P[V=2] \\= & P[\text {la première pastille sélectionnée est conforme et } \\& \text { la deuxième pastille sélectionnée est également conforme}] \\f(1)= & 1-(f(0)+f(2))\end{aligned}](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/dddd7bf74b1653017202d626851885f8.png "\begin{aligned}f(0)= & P[V=0] \\= & P[\text {la première pastille sélectionnée est non conforme et } \\& \text { la deuxième pastille est également non conforme}] \\f(2)= & P[V=2] \\= & P[\text {la première pastille sélectionnée est conforme et } \\& \text { la deuxième pastille sélectionnée est également conforme}] \\f(1)= & 1-(f(0)+f(2))\end{aligned}")
") vaut
vaut=\frac{34 }{100 } \cdot \frac{33 }{99 }=0,1133")
=\frac{66 }{100 } \cdot \frac{65 }{99 }=0,4333")
=1-(0,1133+0,4333)=1-0,5467=0,4533")
 à
à  . Néanmoins, à des fins pratiques,
. Néanmoins, à des fins pratiques,  . Pour s’en convaincre, il suffit de noter que
. Pour s’en convaincre, il suffit de noter que^{2 }(0,66)^{0}=0,1156 \approx f(0) \\& \frac{2 !}{1 ! 1 !}(0,34)^{1 }(0,66)^{1 }=0,4488 \approx f(1) \\& \frac{2 !}{2 ! 0 !}(0,34)^{0}(0,66)^{2 }=0,4356 \approx f(2)\end{aligned}")
 et que p n’est pas trop extrême, la distribution binomiale est une description correcte d’une variable issue d’un échantillonnage aléatoire simple.
et que p n’est pas trop extrême, la distribution binomiale est une description correcte d’une variable issue d’un échantillonnage aléatoire simple.=\sum_{x=0}^{n} x \frac{n !}{x !(n-x) !} p^{x}(1-p)^{n-x}=n p")
^ \frac{n !}{x !(n-x) !} p^{x}(1-p)^{n-x}=n p(1-p)")
(0,2)=2 \text { arbres } \\\sqrt{\operatorname{Var} U} & =\sqrt{10(0,2)(0,8)}=1,26 \text { arbres }\end{aligned}")
")
= \begin{cases}\frac{e^{-\lambda} \lambda^{x}}{x !} & \text { pour } x=0,1,2, \ldots \\ 0 & \text { sinon }\end{cases}")
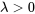 0″ title= »\lambda>0″ class= »latex mathjax »>.
0″ title= »\lambda>0″ class= »latex mathjax »>. . On obtient alors la distribution binomiale
. On obtient alors la distribution binomiale ") . En fait, si
. En fait, si ") se rapproche de celle donnée dans la définition 3.2.6.1. On peut donc considérer que la distribution de Poisson pour les dénombrements résulte d’un mécanisme qui présente de nombreuses possibilités d’occurrences (à très faible probabilité) ou de non-occurrences indépendantes dans un intervalle de temps ou d’espace donné.
se rapproche de celle donnée dans la définition 3.2.6.1. On peut donc considérer que la distribution de Poisson pour les dénombrements résulte d’un mécanisme qui présente de nombreuses possibilités d’occurrences (à très faible probabilité) ou de non-occurrences indépendantes dans un intervalle de temps ou d’espace donné.
 , et l’histogramme de probabilité atteint un sommet près de
, et l’histogramme de probabilité atteint un sommet près de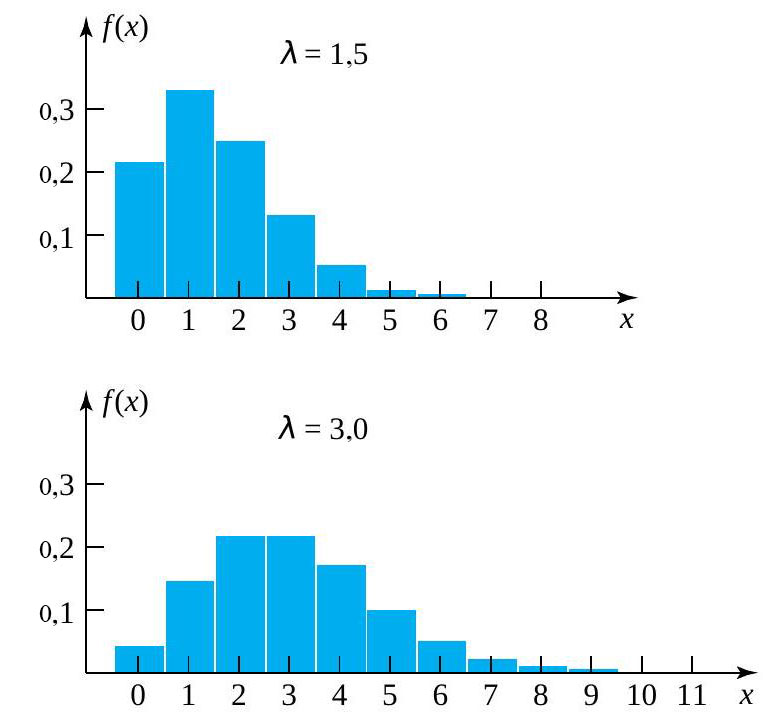
=\sum_{x=0}^{\infty} x \frac{e^{-\lambda} \lambda^{x}}{x !}=\lambda")
^ \frac{e^{-\lambda} \lambda^{x}}{x !}=\lambda")

 .
.
= \begin{cases}\frac{e^{-3.87}(3.87)^{s}}{s !} & \text { pour } s=0,1,2, \ldots \\ 0 & \text { sinon }\end{cases}")
 [au moins 4 particules sont enregistrées]
[au moins 4 particules sont enregistrées]![=P[S \geq 4]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/32e72bc46069c5e865b1358f0cb30ac6.png "=P[S \geq 4]")
+f(5)+f(6)+\cdots")
+f(1)+f(2)+f(3))")
^{0}}{0 !}+\frac{e^{-3,87}(3,87)^}{1 !}+\frac{e^{-3,87}(3,87)^}{2 !}+\frac{e^{-3,87}(3,87)^}{3 !}\right)")


 ,
, =12,5 \text { étudiant.e.s }")
 & =\lambda=12,5 \text { étudiant.e.s } \\\sqrt{\operatorname{Var}(M)} & =\sqrt{\lambda}=\sqrt{12,5 }=3,54 \text { étudiant.e.s }\end{aligned}")
![\begin{aligned}P[10 \leq M \leq 15]= & f(10)+f(11)+f(12)+f(13)+f(14)+f(15) \\= & \frac{e^{-12,5}(12,5)^}{10 !}+\frac{e^{-12,5}(12,5)^}{11 !}+\frac{e^{-12,5}(12,5)^}{12 !} \\& +\frac{e^{-12,5}(12,5)^}{13 !}+\frac{e^{-12,5}(12,5)^}{14 !}+\frac{e^{-12,5}(12,5)^}{15 !} \\= & .60\end{aligned}](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/0fb614c04715fc8cdf4a57a37d5d8dc9.png "\begin{aligned}P[10 \leq M \leq 15]= & f(10)+f(11)+f(12)+f(13)+f(14)+f(15) \\= & \frac{e^{-12,5}(12,5)^}{10 !}+\frac{e^{-12,5}(12,5)^}{11 !}+\frac{e^{-12,5}(12,5)^}{12 !} \\& +\frac{e^{-12,5}(12,5)^}{13 !}+\frac{e^{-12,5}(12,5)^}{14 !}+\frac{e^{-12,5}(12,5)^}{15 !} \\= & .60\end{aligned}")
 dx = 1")
 dx")
") pour représenter la courbe.
pour représenter la courbe.  f(x) dx lorsque dx tend vers zéro. (En mécanique,
f(x) dx lorsque dx tend vers zéro. (En mécanique,  X
X f(t) dt
f(t) dt F(x) = f(x)
F(x) = f(x)
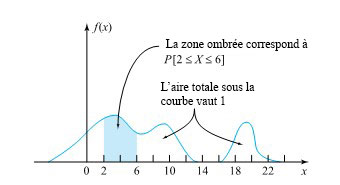
 et
et  . P(c<x<d) est l’aire sous la courbe, entre
. P(c<x<d) est l’aire sous la courbe, entre =0") . La probabilité que
. La probabilité que  et
et 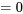 La probabilité étant égale à l’aire, la probabilité est donc également nulle.
La probabilité étant égale à l’aire, la probabilité est donc également nulle.") , car la probabilité est égale à l’aire.
, car la probabilité est égale à l’aire.=\int_{-\infty}^{\infty} x f(x) d x") .
.=\int_{-\infty}^{\infty}(x-E X)^2 f(x) d x \quad\left(=\int_{-\infty}^{\infty} x^2 f(x) d x-(E X)^2\right)")
 à la place de Var(X), et le symbole σ est utilisé à la place de
à la place de Var(X), et le symbole σ est utilisé à la place de =\frac{ 1}{\sqrt{2 \pi \sigma^2}} e^{-(x-\mu)^2 / 2 \sigma^2}")
=\int_{-\infty}^{\infty} x \frac{ 1}{\sqrt{2 \pi \sigma^2}} e^{-(x-\mu)^2 / 2 \sigma^2} d x=\mu")
} =\int_{-\infty}^{\infty}(x-\mu)^2 \frac{ 1}{\sqrt{2 \pi \sigma^2}} e^{-(x-\mu)^2 / 2 \sigma^2} d x=\sigma^2")
 (on se rappelle que l’écart-type =
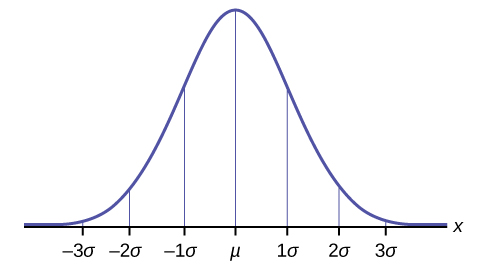
(on se rappelle que l’écart-type =  = σ). La figure 4.1.3.1 illustre la notation de la distribution normale standard et indique que la forme de la distribution dépend de ces paramètres. Comme l’aire sous la courbe doit être égale à 1, un changement dans l’écart-type σ entraîne une modification de la forme de la courbe; la courbe devient plus large ou plus étroite selon si σ augmente ou diminue, respectivement. Une modification de μ entraîne une translation du graphique vers la gauche ou la droite. En vertu de ces deux paramètres, il existe un nombre infini de distributions de probabilités normales.
= σ). La figure 4.1.3.1 illustre la notation de la distribution normale standard et indique que la forme de la distribution dépend de ces paramètres. Comme l’aire sous la courbe doit être égale à 1, un changement dans l’écart-type σ entraîne une modification de la forme de la courbe; la courbe devient plus large ou plus étroite selon si σ augmente ou diminue, respectivement. Une modification de μ entraîne une translation du graphique vers la gauche ou la droite. En vertu de ces deux paramètres, il existe un nombre infini de distributions de probabilités normales.
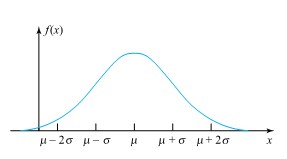
![P[a \leq X \leq b]=\int_a^b \frac{ 1}{\sqrt{2 \pi \sigma^2}} e^{-(x-\mu)^2 / 2 \sigma^2} d x=\int_{(a-\mu) / \sigma}^{(b-\mu) / \sigma} \frac{ 1}{\sqrt{2 \pi}} e^{-z^2 / 2} d z](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/7d7d2902c84523e28fb1268b52141fbd.png "P[a \leq X \leq b]=\int_a^b \frac{ 1}{\sqrt{2 \pi \sigma^2}} e^{-(x-\mu)^2 / 2 \sigma^2} d x=\int_{(a-\mu) / \sigma}^{(b-\mu) / \sigma} \frac{ 1}{\sqrt{2 \pi}} e^{-z^2 / 2} d z")

 / \sigma}^{(b-\mu) / \sigma} \frac{ 1}{\sqrt{2 \pi}} e^{-z^2 / 2} d z")
") et une valeur x associée à X on obtient la cote Z comme suit :
et une valeur x associée à X on obtient la cote Z comme suit :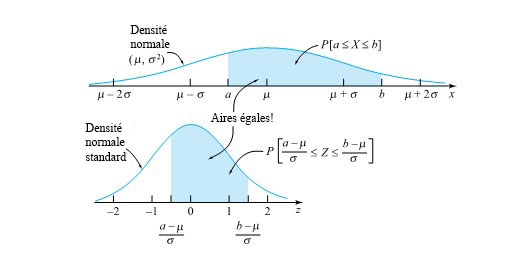
=F(z)=\int_{-\infty}^z \frac{1 }{\sqrt{2 \pi}} e^{-t^2 / 2} d t")
") est utilisé pour représenter la fonction de probabilité normale réduite cumulative, au lieu de la lettre F, plus générique.
est utilisé pour représenter la fonction de probabilité normale réduite cumulative, au lieu de la lettre F, plus générique.") , la fonction quantile normale réduite, on a :
, la fonction quantile normale réduite, on a :\right) & =p \\ Q_z(\Phi(z)) & =z \end{array}\right\}")
") sont des fonctions inverses. (En fait, la relation
sont des fonctions inverses. (En fait, la relation n’est pas une propriété particulière de la distribution normale réduite; cette identité tient
n’est pas une propriété particulière de la distribution normale réduite; cette identité tient-\Phi(0,57)")
 = 0,025 que z se trouve dans la queue droite de la distribution normale
= 0,025 que z se trouve dans la queue droite de la distribution normale=0,975") . En repérant 0,975 dans le corps de la table, on constate que z = 1,96.
. En repérant 0,975 dans le corps de la table, on constate que z = 1,96.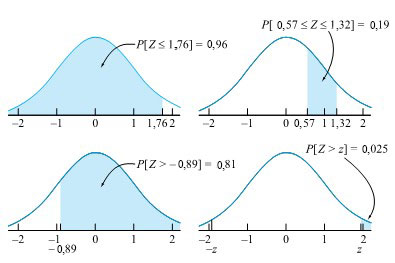

 = 134,0 et w
= 134,0 et w = 136,0 :
= 136,0 :

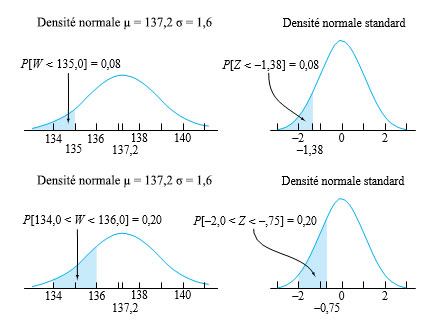
=-2,33")

") , qui calcule la probabilité que
, qui calcule la probabilité que (simultanément). Autrement dit,
(simultanément). Autrement dit,![f(x, y)=P[X=x \text { et } Y=y]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/0b98ddcec1358e23f0edde7603a4572b.png "f(x, y)=P[X=x \text { et } Y=y]")
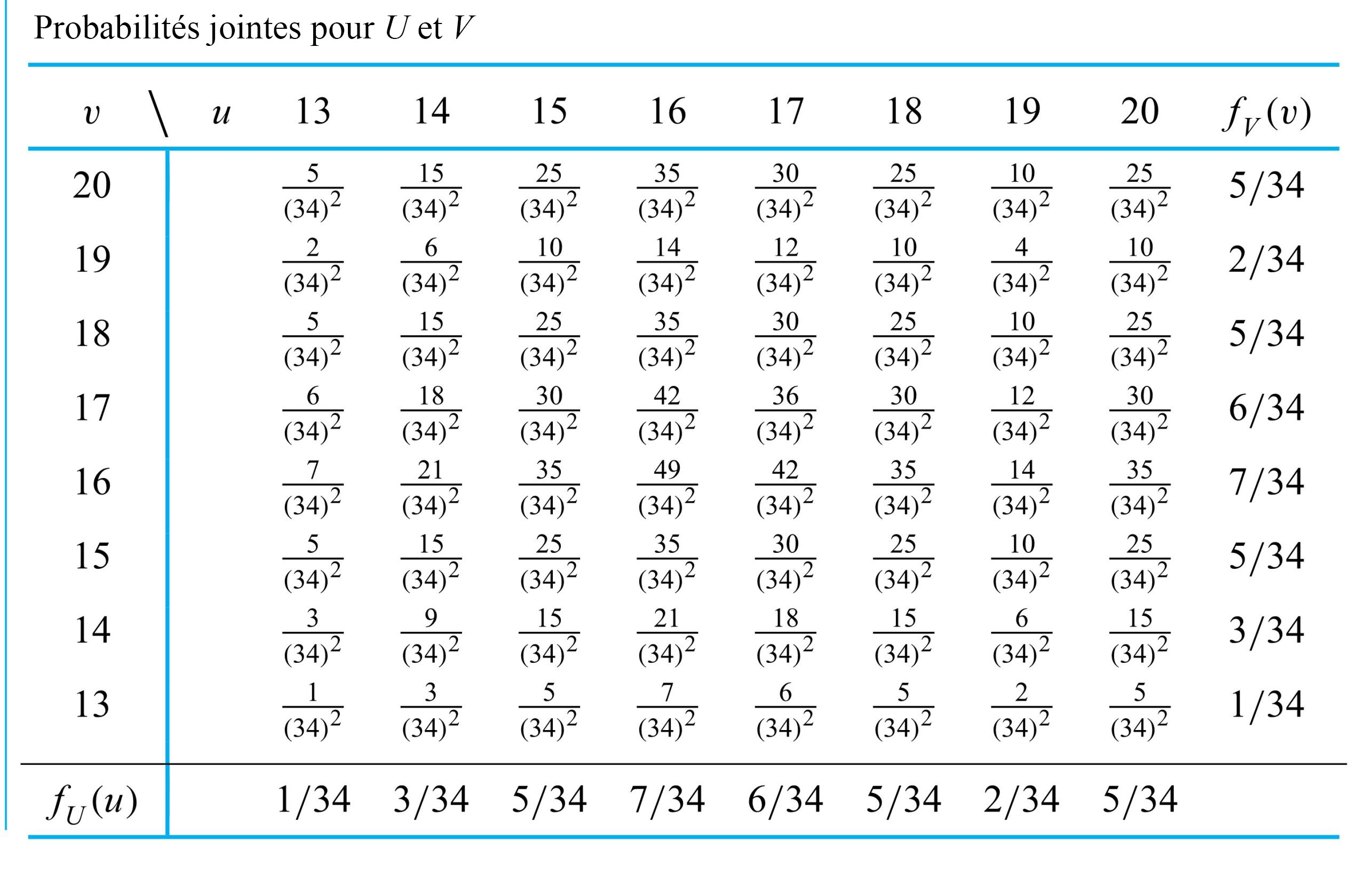
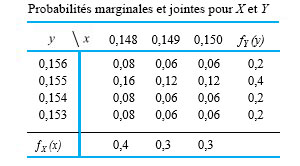
 le prochain couple enregistré pour le boulon 3
le prochain couple enregistré pour le boulon 3 le prochain couple enregistré pour le boulon 4
le prochain couple enregistré pour le boulon 4 et
et ![Y=18]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/7b60878193a2a3ebd3d9c6686c22d985.png "Y=18]") pourrait être
pourrait être  , la fréquence relative de cette paire dans l’ensemble de données. De même, les valeurs
, la fréquence relative de cette paire dans l’ensemble de données. De même, les valeurs![\begin{aligned}& P[X=18 \text { et } Y=17]=\frac{2 }{ 34} \\& P[X=14 \text { et } Y=9]=0\end{aligned}](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/f043af9dc4c47fbf28ee933f1241c4d0.png "\begin{aligned}& P[X=18 \text { et } Y=17]=\frac{2 }{ 34} \\& P[X=14 \text { et } Y=9]=0\end{aligned}")
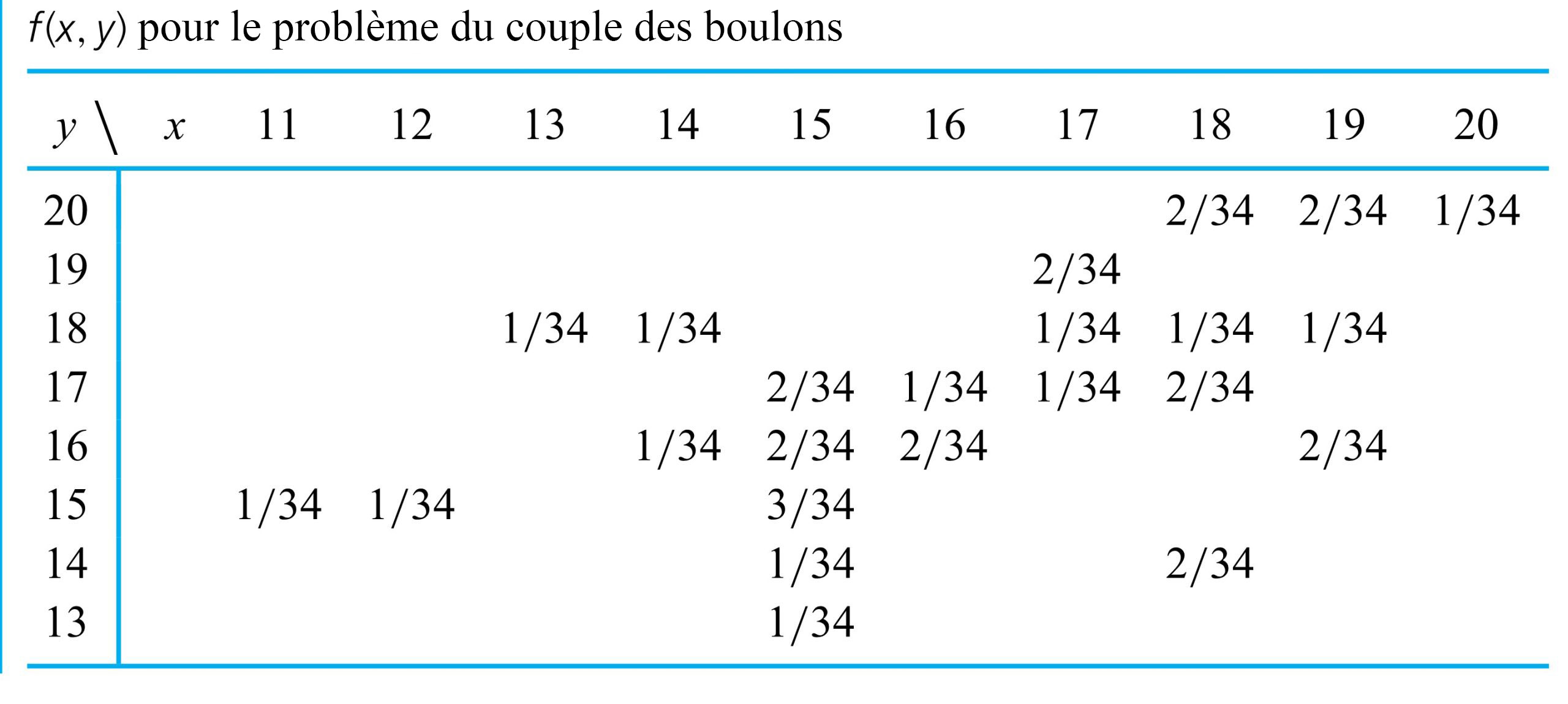
![[0,1]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/344478f605e0a63e4fb539fbfc216ad1.png "[0,1]") , et leur somme vaut 1. Pour obtenir la probabilité d’une configuration d’intérêt
, et leur somme vaut 1. Pour obtenir la probabilité d’une configuration d’intérêt ![\begin{aligned}& P[X\geq Y], \\& P[|X-Y|\leq 1], \\& \text { et } P[X=17]\end{aligned}](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/3a431cdee21c01d58bfeb2e20efe60e4.png "\begin{aligned}& P[X\geq Y], \\& P[|X-Y|\leq 1], \\& \text { et } P[X=17]\end{aligned}")
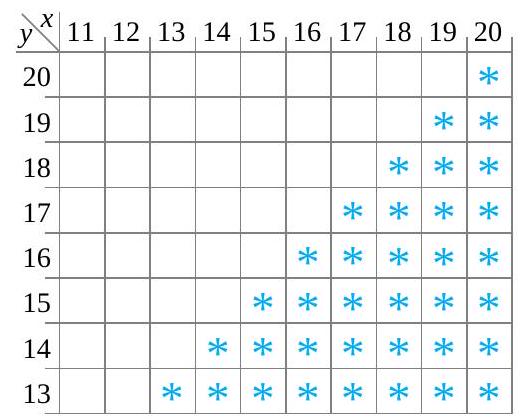
![P[X \geq Y]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/af46a0fb553ac0a80758e888cfaa850b.png "P[X \geq Y]") , la probabilité que le couple du boulon 3 soit au moins aussi important que le couple du boulon 4. La figure 4.2.1.1 indique par des astérisques les combinaisons possibles de
, la probabilité que le couple du boulon 3 soit au moins aussi important que le couple du boulon 4. La figure 4.2.1.1 indique par des astérisques les combinaisons possibles de ![\begin{aligned}P[X \geq Y]= & f(15,13)+f(15,14)+f(15,15)+f(16,16) \\& +f(17,17)+f(18,14)+f(18,17)+f(18,18) \\& +f(19,16)+f(19,18)+f(20,20) \\= & \frac{ 1}{ 34}+\frac{ 1}{ 34}+\frac{ 3}{ 34}+\frac{ 2}{ 34}+\cdots+\frac{ 1}{ 34}=\frac{ 17}{ 34}\end{aligned}](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/e8700d378546578de7dab9beaf219426.png "\begin{aligned}P[X \geq Y]= & f(15,13)+f(15,14)+f(15,15)+f(16,16) \\& +f(17,17)+f(18,14)+f(18,17)+f(18,18) \\& +f(19,16)+f(19,18)+f(20,20) \\= & \frac{ 1}{ 34}+\frac{ 1}{ 34}+\frac{ 3}{ 34}+\frac{ 2}{ 34}+\cdots+\frac{ 1}{ 34}=\frac{ 17}{ 34}\end{aligned}")
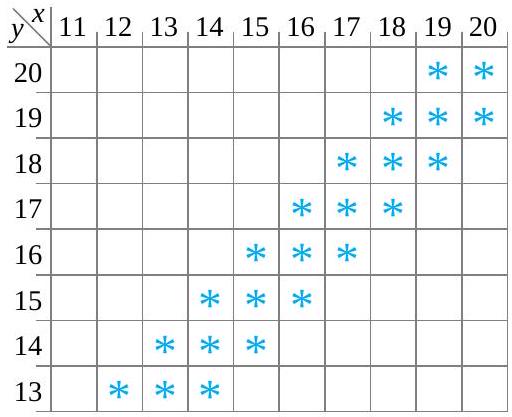
![P[|X-Y| \leq 1]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/e863f7444d8179376e25d920e88fbd40.png "P[|X-Y| \leq 1]") -la probabilité que les couples des boulons 3 et 4 se situent à
-la probabilité que les couples des boulons 3 et 4 se situent à  l’un de l’autre. La figure 4.2.1.2 illustre les combinaisons de
l’un de l’autre. La figure 4.2.1.2 illustre les combinaisons de ![\begin{aligned}P[|X-Y| \leq 1]= & f(15,14)+f(15,15)+f(15,16)+f(16,16) \\& +f(16,17)+f(17,17)+f(17,18)+f(18,17) \\& +f(18,18)+f(19,18)+f(19,20)+f(20,20)=\frac{ 18}{ 34}\end{aligned}](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/65e181c2f20553b81748bdc1a694cbcd.png "\begin{aligned}P[|X-Y| \leq 1]= & f(15,14)+f(15,15)+f(15,16)+f(16,16) \\& +f(16,17)+f(17,17)+f(17,18)+f(18,17) \\& +f(18,18)+f(19,18)+f(19,20)+f(20,20)=\frac{ 18}{ 34}\end{aligned}")

 .
.![P[X=17]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/0912a53b69eb7eb10e46c1f59352e883.png "P[X=17]") , la probabilité que le couple mesuré sur le boulon 3 soit
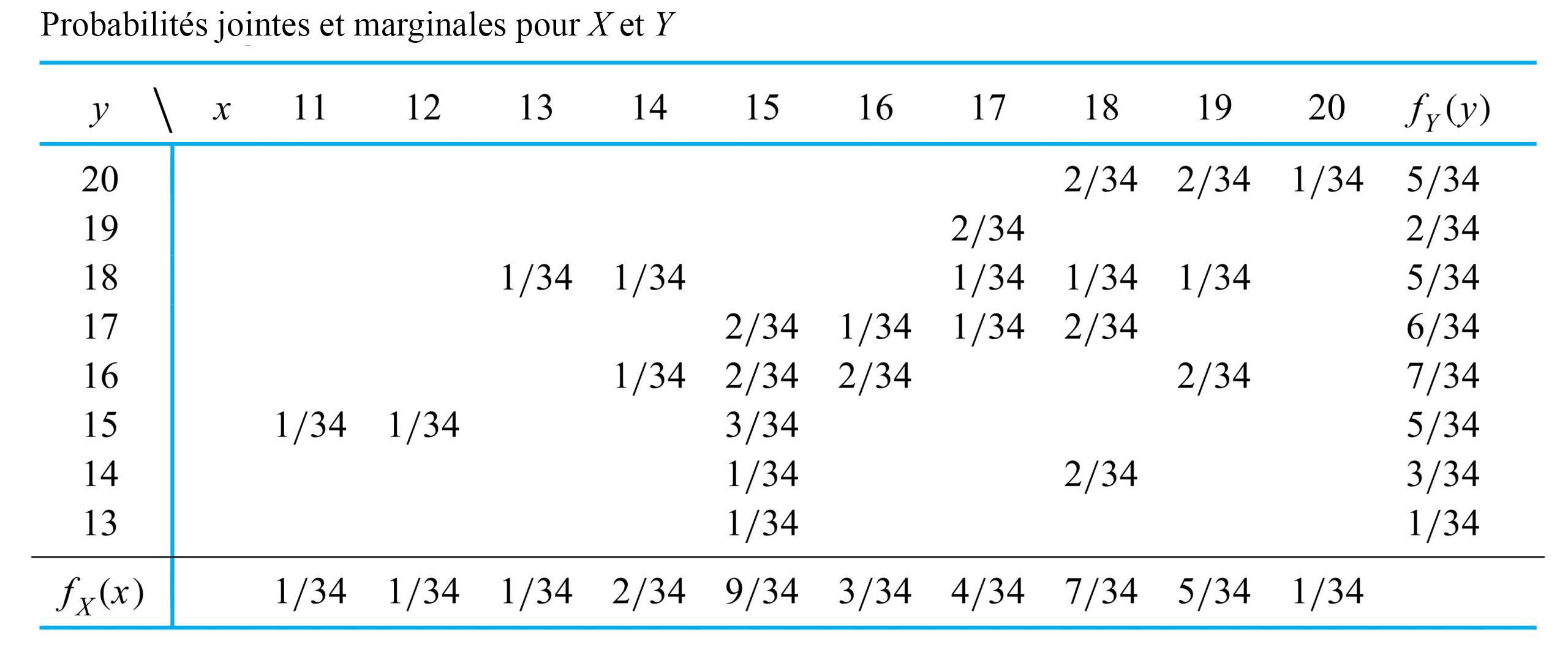
, la probabilité que le couple mesuré sur le boulon 3 soit  , s’obtient en additionnant la colonne
, s’obtient en additionnant la colonne  dans le tableau 4.2.1.1. Autrement dit,
dans le tableau 4.2.1.1. Autrement dit,![\begin{aligned} P[X=17] & =f(17,17)+f(17,18)+f(17,19) \\ & =\frac{ 1}{ 34}+\frac{ 1}{ 34}+\frac{ 2}{ 34} \\ & =\frac{ 4}{ 34} \end{aligned}](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/152ecf42295f0efb7bc4bd56de294bf7.png "\begin{aligned} P[X=17] & =f(17,17)+f(17,18)+f(17,19) \\ & =\frac{ 1}{ 34}+\frac{ 1}{ 34}+\frac{ 2}{ 34} \\ & =\frac{ 4}{ 34} \end{aligned}")
") . On peut également additionner les lignes du même tableau pour obtenir les valeurs de la fonction de probabilité de
. On peut également additionner les lignes du même tableau pour obtenir les valeurs de la fonction de probabilité de ") . On peut alors inscrire ces sommes dans les marges du tableau à double entrée, d’où l’appellation « distributions marginales ». L’encadré qui suit définit la terminologie utilisée dans le cas d’un problème à deux variables discrètes.
. On peut alors inscrire ces sommes dans les marges du tableau à double entrée, d’où l’appellation « distributions marginales ». L’encadré qui suit définit la terminologie utilisée dans le cas d’un problème à deux variables discrètes.=\sum_{y} f(x, y)")
=\sum_{x} f(x, y)")
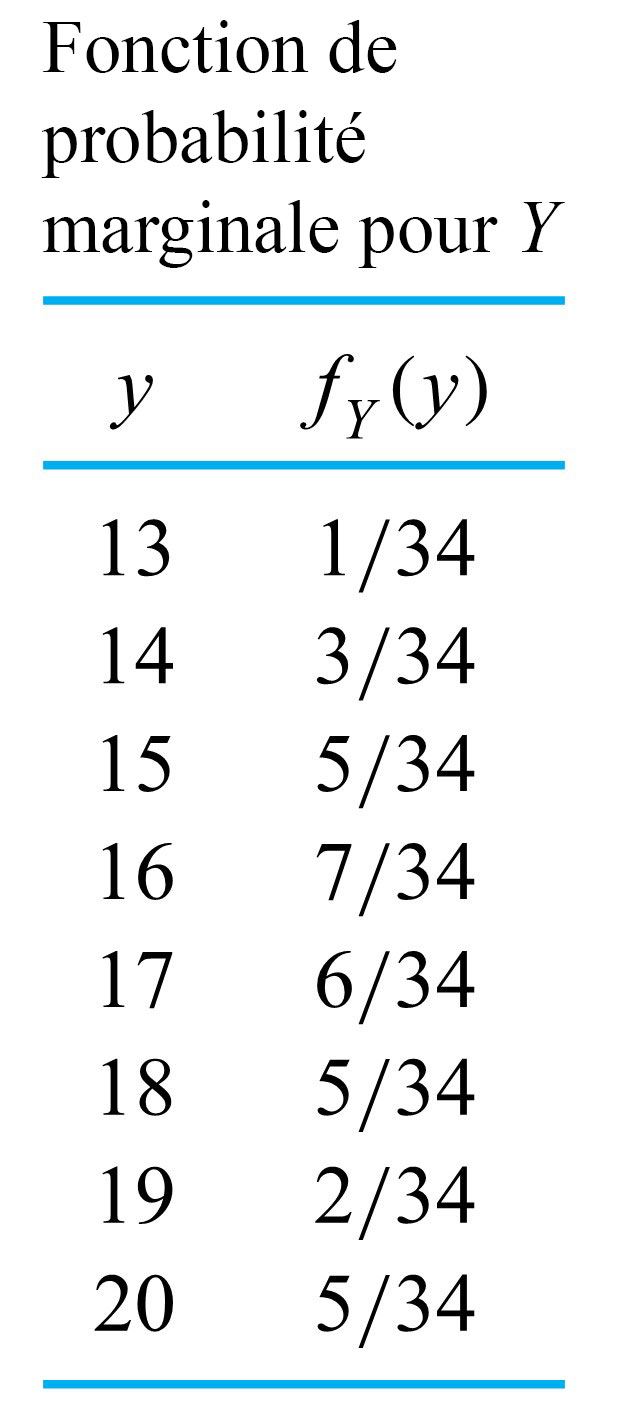
") et
et ") sont connues, y a-t-il alors une seule option pour
sont connues, y a-t-il alors une seule option pour 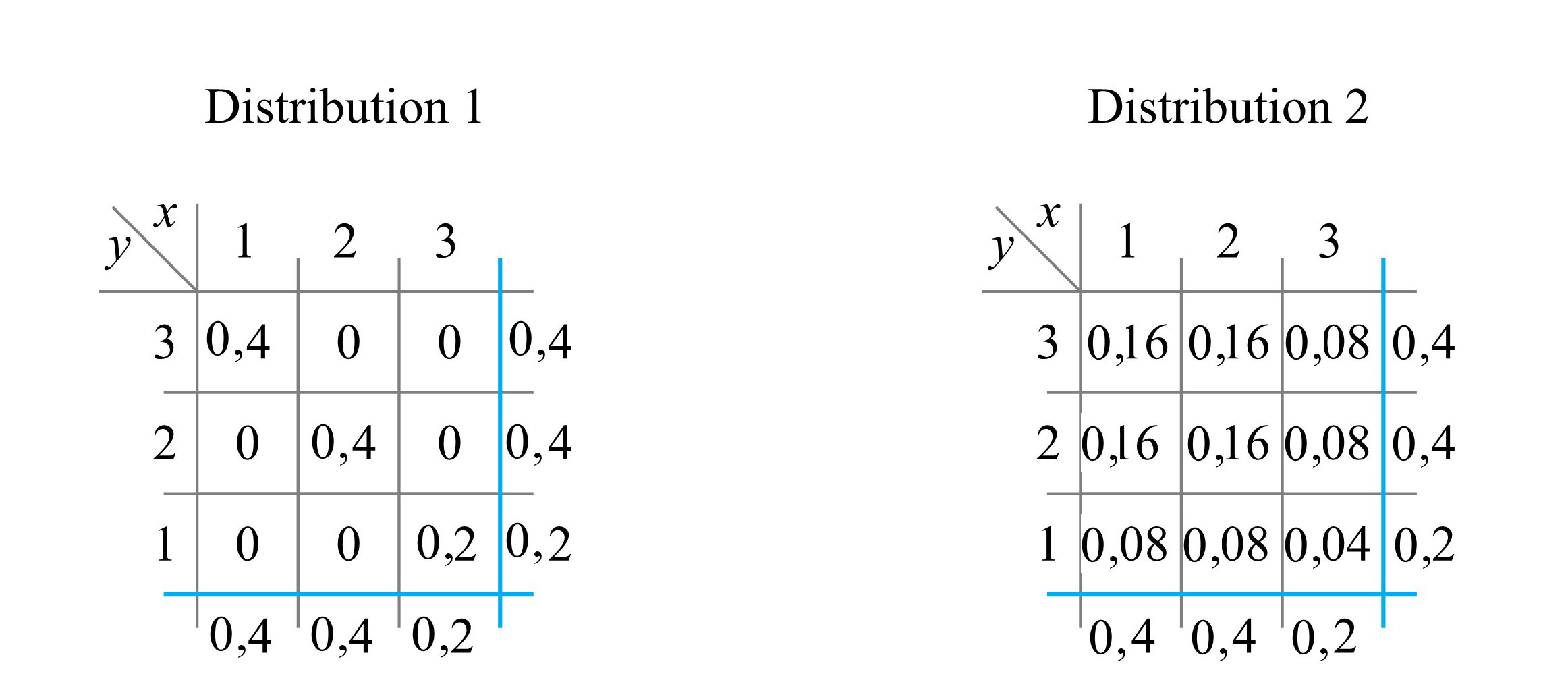
") , un technicien qui vient de desserrer le boulon 3 et qui a mesuré le couple à la valeur
, un technicien qui vient de desserrer le boulon 3 et qui a mesuré le couple à la valeur  devrait avoir des attentes pour le couple du boulon 4
devrait avoir des attentes pour le couple du boulon 4 ") quelque peu différentes, à la lumière de la distribution marginale du tableau 4.2.1.3. Après tout, si on reprend les données du tableau 4.2.2.1, la distribution de la fréquence relative des couples des boulons 4 pour les composants dont le couple du boulon 3 est de
quelque peu différentes, à la lumière de la distribution marginale du tableau 4.2.1.3. Après tout, si on reprend les données du tableau 4.2.2.1, la distribution de la fréquence relative des couples des boulons 4 pour les composants dont le couple du boulon 3 est de  devrait modifier la distribution de probabilité de
devrait modifier la distribution de probabilité de 
 est la fonction de
est la fonction de =\frac{f(x, y)}{\sum_{x} f(x, y)}")
 étant donné que
étant donné que  est la fonction de
est la fonction de =\frac{f(x, y)}{\sum_{y} f(x, y)")
=\frac{f(x, y)}{f_{Y}(y)}")
=\frac{f(x, y)}{f_{X}(x)}")
=\right.")
") ) pour les renormaliser (faire en sorte qu’elles totalisent 1). De même, l’équation 4.2.2.3 indique que si l’on considère uniquement la colonne
) pour les renormaliser (faire en sorte qu’elles totalisent 1). De même, l’équation 4.2.2.3 indique que si l’on considère uniquement la colonne  , la distribution conditionnelle appropriée pour
, la distribution conditionnelle appropriée pour =\frac{f(15, y)}{f_{X}(15)}")
 . Ainsi, en divisant les valeurs dans la colonne
. Ainsi, en divisant les valeurs dans la colonne 
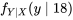 f_{Y \mid X}(y \mid 18) :
f_{Y \mid X}(y \mid 18) :=\frac{f(18, y)}{f_{X}(18)}")
 , présentée dans le tableau 4.2.2.3. Les tableaux 4.2.2.2 et 4.2.4.3 confirment que les distributions conditionnelles de
, présentée dans le tableau 4.2.2.3. Les tableaux 4.2.2.2 et 4.2.4.3 confirment que les distributions conditionnelles de 
") . Dans cette situation, l’équation 4.2.2.2 donne :
. Dans cette situation, l’équation 4.2.2.2 donne :=\frac{f(x, 20)}{f_{Y}(20)}")
 du tableau 4.2.1.2 divisées par la valeur marginale de
du tableau 4.2.1.2 divisées par la valeur marginale de ") est répertoriée dans le tableau 4.2.2.4.
est répertoriée dans le tableau 4.2.2.4.
 .
.  fournit des informations à propos de
fournit des informations à propos de 

 et tout
et tout =f_{U}(u)")
=f_{V}(v)")
}{f_{V}(v)}=f_{U}(u)")
=f_{U}(u) f_{V}(v)")

=f_{X}(x) f_{Y}(y) \quad \text { pour toute paire } (x, y)")
 , il faut clairement que
, il faut clairement que![f(13,13)=P[U=13 \text { et } V=13]=0](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/105fe4b3d7cbdef4eeb0ae8e8ae09cd5.png "f(13,13)=P[U=13 \text { et } V=13]=0")
=\frac{ 1}{(34)^2}")
=0")
=f_{V}(13)=\frac")
 papiers, en suivant la fréquence relative du tableau 4.2.2.6. Ainsi, même si l’échantillonnage est effectué sans remplacement, les probabilités développées précédemment pour
papiers, en suivant la fréquence relative du tableau 4.2.2.6. Ainsi, même si l’échantillonnage est effectué sans remplacement, les probabilités développées précédemment pour =\frac{ 99}{3 399}")
=\frac{f(u, v)}{f_{U}(u)}")
=f_{V \mid U}(v \mid u) f_{U}(u)")
=\frac{99 }{3 399} \cdot \frac{ 1}{34 }")

 \approx \frac{ 1}{ 34} \cdot \frac{ 1}{ 34}")
 est beaucoup plus grande que la taille de l’échantillon
est beaucoup plus grande que la taille de l’échantillon  ont toutes la même distribution marginale et sont indépendantes, on dit qu’elles sont indépendantes et identiquement distribuées (iid).
ont toutes la même distribution marginale et sont indépendantes, on dit qu’elles sont indépendantes et identiquement distribuées (iid). et une fonction
et une fonction ") . L’objectif est de prédire le comportement de la variable aléatoire
. L’objectif est de prédire le comportement de la variable aléatoire")


 sont
sont  ,
,  constantes. La variable aléatoire
constantes. La variable aléatoire  a alors une moyenne de
a alors une moyenne de=a_{0}+a_ E(X)+a_ E(Y)+\cdots+a_{n} E(Z)")
=a_1^2 \operatorname{Var(X)} +a_2^2 \operatorname{Var(Y)} +\cdots+a_{n}^2 \operatorname{Var(Z)}")
 , et les autres
, et les autres  .
. , et
, et =0,1489 & \text { et } & \operatorname{Var(X)}=6,9 \times 10^{-7} \\E(Y)=0,1546 & \text { et } & \operatorname{Var(Y)}=1,04 \times 10^{-6}\end{array}")
 X+1 Y")
 & =-1 E(X)+1 E(Y)=-0,1489+0,1546=0,0057 \text{ po} \\\operatorname{Var(U)} & =(-1)^2 6,9 \times 10^{-7}+(1)^2 1,04 \times 10^{-6}=1,73 \times 10^{-6} \text{ po}^2 \end{aligned}")
}}=0,0013 \text { po }")
") et de
et de }") , ce n’est pas nécessaire de passer par l’étape intermédiaire consistant à obtenir la distribution de
, ce n’est pas nécessaire de passer par l’étape intermédiaire consistant à obtenir la distribution de  . Autrement dit, lorsque les variables aléatoires
. Autrement dit, lorsque les variables aléatoires 
 et
et =\frac{ 1}{n} E(X_1)+\frac{ 1}{n} E (X_2)+\cdots+\frac{ 1}{n} E (X_{n})=n\left(\frac{ 1}{n} \mu\right)=\mu")
 » title= »\begin{aligned}\operatorname{Var( \bar{X} )} & =\left(\frac{ 1}{n}\right)^2 \operatorname{Var(X_1)} +\left(\frac{ 1}{n}\right)^2 \operatorname{Var(X_2)} +\cdots+\left(\frac{ 1}{n}\right)^2 \operatorname{Var(X_{n})} \\& =n\left(\frac{ 1}{n}\right)^2 \sigma^2=\frac{\sigma^2}{n}\end{aligned}
» title= »\begin{aligned}\operatorname{Var( \bar{X} )} & =\left(\frac{ 1}{n}\right)^2 \operatorname{Var(X_1)} +\left(\frac{ 1}{n}\right)^2 \operatorname{Var(X_2)} +\cdots+\left(\frac{ 1}{n}\right)^2 \operatorname{Var(X_{n})} \\& =n\left(\frac{ 1}{n}\right)^2 \sigma^2=\frac{\sigma^2}{n}\end{aligned} ayant la distribution de probabilité centrée sur la moyenne de la population
ayant la distribution de probabilité centrée sur la moyenne de la population ![\bar{X}[/latex] dans le cadre d’un échantillonnage aléatoire avec remplacement, sont également des descriptions approximatives du comportement de <img src="https://atu0g9ctah.execute-api.ca-central-1.amazonaws.com/latest/latex?latex=&fg=000000&font=TeX&svg=1" alt="" title="" class="latex mathjax" />\bar{X}](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/8b4b6ad5b0b43eec0928cf7d1713308a.png "\bar{X}[/latex] dans le cadre d’un échantillonnage aléatoire avec remplacement, sont également des descriptions approximatives du comportement de <img src="https://atu0g9ctah.execute-api.ca-central-1.amazonaws.com/latest/latex?latex=&fg=000000&font=TeX&svg=1" alt="" title="" class="latex mathjax" />\bar{X}") dans le cadre d’une échantillonnage aléatoire simple dans des contextes énumératifs. (Rappelons la discussion sur l’indépendance approximative des observations résultant d’un échantillonnage aléatoire simple dans une grande population.)
dans le cadre d’une échantillonnage aléatoire simple dans des contextes énumératifs. (Rappelons la discussion sur l’indépendance approximative des observations résultant d’un échantillonnage aléatoire simple dans une grande population.) .)
.) le dernier chiffre du numéro de série observé lundi prochain à 9 h.
le dernier chiffre du numéro de série observé lundi prochain à 9 h. le dernier chiffre du numéro de série observé le lundi suivant à 9 h.
le dernier chiffre du numéro de série observé le lundi suivant à 9 h. sont indépendantes, chacune avec la fonction de probabilité marginale :
sont indépendantes, chacune avec la fonction de probabilité marginale := \begin{cases}0,1 & \text { si } w=0,1,2, \ldots, 9 \\ 0 & \text { sinon }\end{cases}")
") a la fonction de probabilité donnée au tableau 4.2.4.1 et illustrée à la figure 4.2.4.2.
a la fonction de probabilité donnée au tableau 4.2.4.1 et illustrée à la figure 4.2.4.2.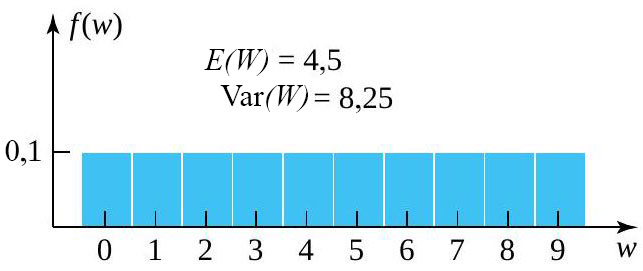

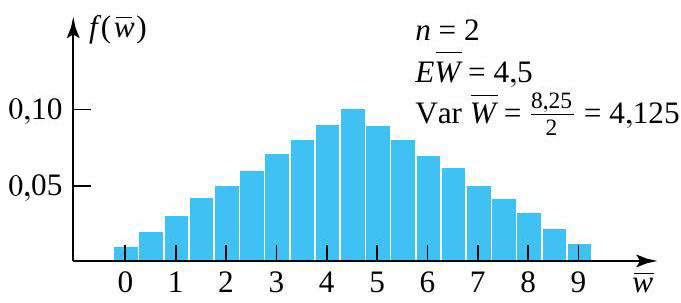
 , avec
, avec 
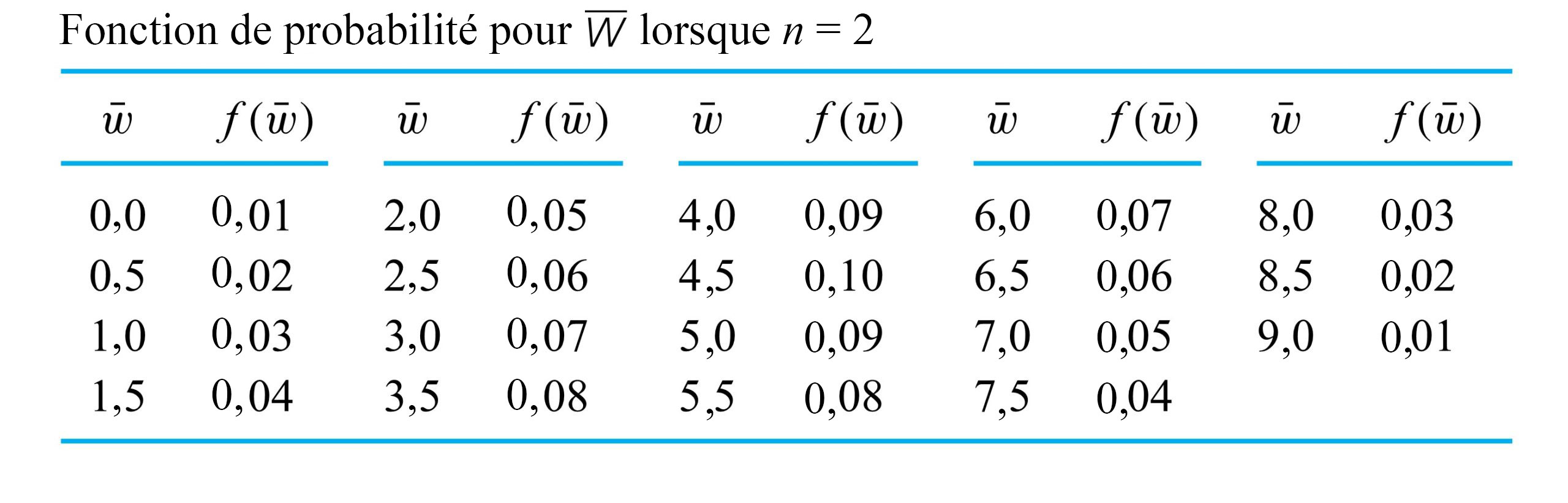
 et une taille d’échantillon de
et une taille d’échantillon de  commence à prendre une forme de cloche – à tout le moins, plus que la distribution sous-jacente. La raison en est claire. Plus on s’éloigne de la moyenne ou de la valeur centrale de
commence à prendre une forme de cloche – à tout le moins, plus que la distribution sous-jacente. La raison en est claire. Plus on s’éloigne de la moyenne ou de la valeur centrale de  et
et  qui peuvent produire une valeur donnée de
qui peuvent produire une valeur donnée de  . Par exemple, pour que
. Par exemple, pour que  , il faut que
, il faut que  et
et  – autrement dit, il faut non pas une, mais deux valeurs extrêmes. En revanche, il existe 10 combinaisons différentes de
– autrement dit, il faut non pas une, mais deux valeurs extrêmes. En revanche, il existe 10 combinaisons différentes de  .
. (avec une distribution marginale qui a été simulée et chaque ensemble pondéré pour produire 1 000 valeurs simulées de
(avec une distribution marginale qui a été simulée et chaque ensemble pondéré pour produire 1 000 valeurs simulées de  . Remarquez le caractère en forme de cloche du graphique. (La moyenne simulée de
. Remarquez le caractère en forme de cloche du graphique. (La moyenne simulée de =E(W)") , alors que la variance de
, alors que la variance de }=8,25 / 8") , en étroite concordance avec les formules.)
, en étroite concordance avec les formules.)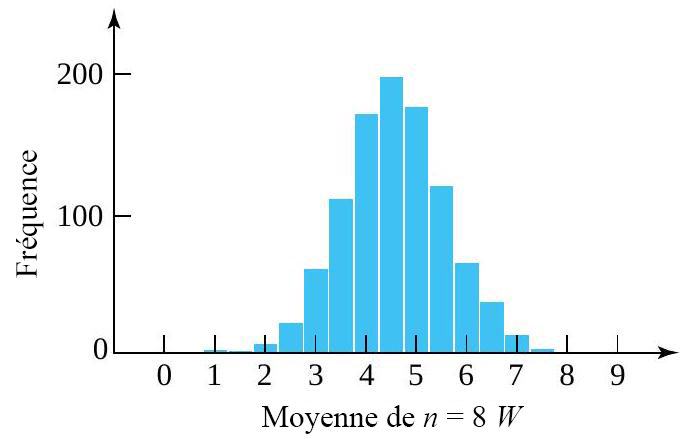
 .
. est généralement suffisant pour que
est généralement suffisant pour que  durées de service excessives pour obtenir :
durées de service excessives pour obtenir : le temps moyen de l’échantillon (au-dessus du seuil de
le temps moyen de l’échantillon (au-dessus du seuil de  ) nécessaire pour réaliser les 100 prochaines ventes de timbres.
) nécessaire pour réaliser les 100 prochaines ventes de timbres.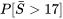 17] » title= »P[\bar{S}>17] » class= »latex mathjax »>.
17] » title= »P[\bar{S}>17] » class= »latex mathjax »>. est plausible pour les temps de service excessifs individuels
est plausible pour les temps de service excessifs individuels =\alpha=16,5 \text{ sec }")
}}=\sqrt{\frac{\alpha^2}{ 100}}=1,65 \text{ sec}")
 , selon nos équations. En outre, en tenant compte du fait que
, selon nos équations. En outre, en tenant compte du fait que 
 et
et ![P[\bar{S}>17]](https://atu0g9ctah.execute-api.ca-central-1.amazonaws.com/latest/latex?latex=P%5B%5Cbar%7BS%7D%3E17%5D&fg=000000&font=TeX&svg=1 "P[\bar{S}>17]") .
. avant de consulter la table normale standard. Dans ce cas, la moyenne et l’écart-type à utiliser sont (respectivement)
avant de consulter la table normale standard. Dans ce cas, la moyenne et l’écart-type à utiliser sont (respectivement)  et
et  . Les cotes
. Les cotes 
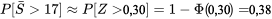 17] \approx P[Z>0,30]=1-\Phi(0,30)=0,38″ title= »P[\bar{S}>17] \approx P[Z>0,30]=1-\Phi(0,30)=0,38″ class= »latex mathjax »>
17] \approx P[Z>0,30]=1-\Phi(0,30)=0,38″ title= »P[\bar{S}>17] \approx P[Z>0,30]=1-\Phi(0,30)=0,38″ class= »latex mathjax »>}{\sqrt{\operatorname{Var(\bar{X})}}}=\frac{\bar{x}-\mu}{\frac{\sigma}{\sqrt{n}}}")
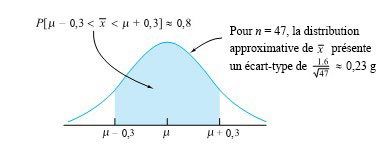
")
 0,3 g
0,3 g
 \frac{0,7 \times 10^{-4}}{\sqrt{ 32}}")



 < z
< z


 . Soit
. Soit
^2")

(5,1)}{ 1}\right)^2 \approx 100")

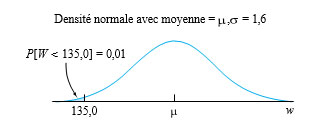
+(1-\Phi(2,5))=0,01")
 .
.
 . Elle est de la même forme que l’hypothèse nulle correspondante, à l’exception du signe d’égalité qui est remplacé par ≠, > ou <.
. Elle est de la même forme que l’hypothèse nulle correspondante, à l’exception du signe d’égalité qui est remplacé par ≠, > ou <.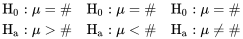 \# & \mathrm{H}_{\mathrm{a}}: \mu\# & \mathrm{H}_{\mathrm{a}}: \mu
\# & \mathrm{H}_{\mathrm{a}}: \mu\# & \mathrm{H}_{\mathrm{a}}: \mu

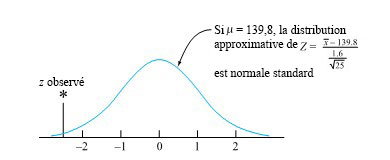
 . En utilisant la forme 5.1.2.4, la distribution de référence sera toujours la même, à savoir la distribution normale réduite.
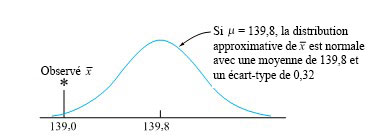
. En utilisant la forme 5.1.2.4, la distribution de référence sera toujours la même, à savoir la distribution normale réduite. 139,8 g.
139,8 g.

![\begin{aligned} & P[\text { une variable normale réduite } \leq-2,5] \\ & \quad+P[\text { une variable normale réduite } \geq 2,5] \\ & \quad=P[\mid \text { une variable normale réduite } \mid \geq 2,5] \\ & \quad=0,01 \end{aligned}](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/1ea01517eb8ce96743c075f3c7345cb8.png "\begin{aligned} & P[\text { une variable normale réduite } \leq-2,5] \\ & \quad+P[\text { une variable normale réduite } \geq 2,5] \\ & \quad=P[\mid \text { une variable normale réduite } \mid \geq 2,5] \\ & \quad=0,01 \end{aligned}")




 .
.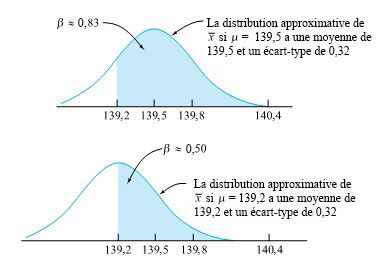
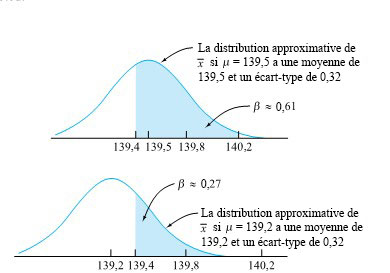

 et la réalité, mais aussi de la taille de l’échantillon. Avec un échantillon de taille suffisante, tout écart par rapport à H0 peut être considéré comme « hautement significatif », qu’il ait une importance pratique ou non.
et la réalité, mais aussi de la taille de l’échantillon. Avec un échantillon de taille suffisante, tout écart par rapport à H0 peut être considéré comme « hautement significatif », qu’il ait une importance pratique ou non.

=0,16")

=0,02")

 .
.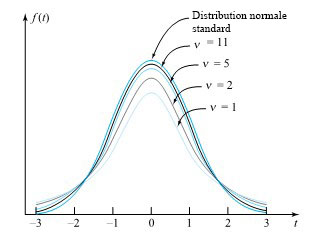
 degrés de liberté et la distribution normale standard sont impossibles à distinguer.
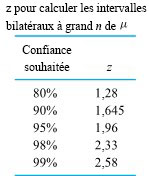
degrés de liberté et la distribution normale standard sont impossibles à distinguer.") . On utilise plutôt des tables (ou des logiciels statistiques) pour évaluer les quantiles communs de la distribution t et ainsi obtenir des limites approximatives sur les types de probabilités nécessaires pour les tests d’hypothèse. La table A1.3 de l’annexe 1 des tables statistiques représente un tableau typique de quantiles t. Les colonnes représentent les probabilités cumulatives et les lignes, les valeurs du paramètre des degrés de liberté,
. On utilise plutôt des tables (ou des logiciels statistiques) pour évaluer les quantiles communs de la distribution t et ainsi obtenir des limites approximatives sur les types de probabilités nécessaires pour les tests d’hypothèse. La table A1.3 de l’annexe 1 des tables statistiques représente un tableau typique de quantiles t. Les colonnes représentent les probabilités cumulatives et les lignes, les valeurs du paramètre des degrés de liberté,  . Autrement dit,
. Autrement dit,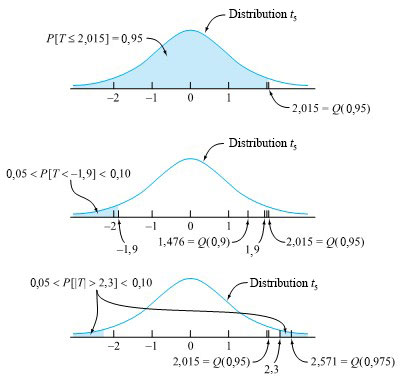


 attribue une probabilité correspondant au niveau de confiance souhaité à l’intervalle compris entre -t et t. De même, l’hypothèse nulle
attribue une probabilité correspondant au niveau de confiance souhaité à l’intervalle compris entre -t et t. De même, l’hypothèse nulle

 ? » Comme il n’y a que de n = 10 observations, la méthode pour les grands échantillons vue au module 5.1 ne s’applique pas. Seule la méthode indiquée par l’expression 5.2.1.5 peut potentiellement être utilisée, et pour qu’elle convienne, les durées de vie doivent être distribuées normalement.
? » Comme il n’y a que de n = 10 observations, la méthode pour les grands échantillons vue au module 5.1 ne s’applique pas. Seule la méthode indiquée par l’expression 5.2.1.5 peut potentiellement être utilisée, et pour qu’elle convienne, les durées de vie doivent être distribuées normalement.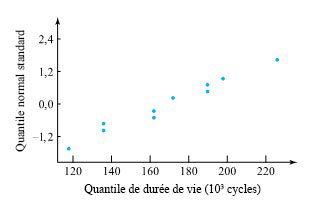
 et on choisit t > 0 de sorte que
et on choisit t > 0 de sorte que![P[-t< \text{une variable aléatoire } t_9 < t] = 0,90](https://atu0g9ctah.execute-api.ca-central-1.amazonaws.com/latest/latex?latex=P%5B-t%3C%20%5Ctext%7Bune%20variable%20al%C3%A9atoire%20%7D%20t_9%20%3C%20t%5D%20%3D%200%2C90&fg=000000&font=TeX&svg=1 "P[-t< \text{une variable aléatoire } t_9 < t] = 0,90")



 et
et  pour représenter les moyennes distributionnelles sous-jacentes correspondant aux première et deuxième conditions et
pour représenter les moyennes distributionnelles sous-jacentes correspondant aux première et deuxième conditions et  et
et  pour représenter les moyennes de l’échantillon correspondantes. Or, si les deux mécanismes de génération de données correspondent essentiellement et conceptuellement à un échantillonnage avec remplacement à partir de deux distributions, la partie 4 indique que
pour représenter les moyennes de l’échantillon correspondantes. Or, si les deux mécanismes de génération de données correspondent essentiellement et conceptuellement à un échantillonnage avec remplacement à partir de deux distributions, la partie 4 indique que  , et que
, et que . La différence entre les moyennes des échantillons
. La différence entre les moyennes des échantillons =\mu_1-\mu_2")
=\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}")
 et
et  sont grands (de sorte que
sont grands (de sorte que }{\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}}")
 ni
ni  . Heureusement, si
. Heureusement, si }{\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}}")



 = 8,34 g,
= 8,34 g,  = 9,31 g, le modèle de test d’hypothèse en cinq étapes conduit au récapitulatif suivant :
= 9,31 g, le modèle de test d’hypothèse en cinq étapes conduit au récapitulatif suivant :
 0″ title= »\mathrm{H}_{\mathrm{a}}: \mu_1-\mu_2>0″ class= »latex mathjax »>
0″ title= »\mathrm{H}_{\mathrm{a}}: \mu_1-\mu_2>0″ class= »latex mathjax »>
^2}{ 24}+\frac{(9,31)^2}{ 24}}}=18,3")
-1,645 \sqrt{\frac{(8,34)^2}{ 24}+\frac{(9,31)^2}{ 24}}")

")
")

 et
et  , la variance pondérée de l’échantillon,
, la variance pondérée de l’échantillon,  s_1^2+\left(n_2-1\right) s_2^2}{\left(n_1-1\right)+\left(n_2-1\right)}=\frac{\left(n_1-1\right) s_1^2+\left(n_2-1\right) s_2^2}{n_1+n_2-2}")
 est égal à la racine carrée de
est égal à la racine carrée de  cycles et
cycles et (42,9)^2+(10-1)(33,1)^2}{(10-1)+(10-1)}=1 468 \cdot 10^3 \text { cycles}^2")

}{\sigma \sqrt{\frac{ 1}{n_1}+\frac{1 }{n_2}}}")
-\left(\mu_1-\mu_2\right)}{s_{\mathrm{P}} \sqrt{\frac{ 1}{n_1}+\frac{ 1}{n_2}}}")
 suivant des distributions normales avec
suivant des distributions normales avec 
 attribue à l’intervalle entre -t et t correspond à la confiance souhaitée. Dans les mêmes conditions, l’hypothèse
attribue à l’intervalle entre -t et t correspond à la confiance souhaitée. Dans les mêmes conditions, l’hypothèse
 condition 1 et la contrainte de
condition 1 et la contrainte de  0 . » title= »\mathrm{H}_{\mathrm{a}}: \mu_1-\mu_2>0 . » class= »latex mathjax »>
0 . » title= »\mathrm{H}_{\mathrm{a}}: \mu_1-\mu_2>0 . » class= »latex mathjax »>

![P[\text{une variable aléatoire } t_{ 18} \geq 2,7]](https://atu0g9ctah.execute-api.ca-central-1.amazonaws.com/latest/latex?latex=P%5B%5Ctext%7Bune%20variable%20al%C3%A9atoire%20%7D%20t_%7B%2018%7D%20%5Cgeq%202%2C7%5D&fg=000000&font=TeX&svg=1 "P[\text{une variable aléatoire } t_{ 18} \geq 2,7]") se situe entre 0,01 et 0,005, ce qui constitue une preuve solide que la contrainte faible est associée à une durée de vie plus élevée en moyenne.
se situe entre 0,01 et 0,005, ce qui constitue une preuve solide que la contrainte faible est associée à une durée de vie plus élevée en moyenne. . Les bornes de l’intervalle de confiance pour \
. Les bornes de l’intervalle de confiance pour \ \pm 2,101(38,3) \sqrt{\frac{ 1}{ 10}+\frac{ 1}{ 10}}}")


^2}{\frac{s_1^4}{\left(n_1-1\right) n_1^2}+\frac{s_2^4}{\left(n_2-1\right) n_2^2}}")
 est telle que la distribution
est telle que la distribution 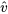 avec
avec  et
et 
^2}{ 10}+\frac{(33,1)^2}{ 10}\right)^2}{\frac{(57,9)^4}{9(100)}+\frac{(33,1)^4}{9(100)}}=14,3")
 est donc 2,145. Les bornes à 95 % de l’expression 5.3.3.8 pour la différence (
est donc 2,145. Les bornes à 95 % de l’expression 5.3.3.8 pour la différence (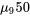 }) sont donc les suivantes :
}) sont donc les suivantes :^2}{ 10}+\frac{(33,1)^2}{ 10}}")


 de Fisher-Snedecor avec paramètres de degrés de liberté du numérateur et du dénominateur
de Fisher-Snedecor avec paramètres de degrés de liberté du numérateur et du dénominateur  et
et  désigne une distribution de probabilité continue ayant pour densité de probabilité
désigne une distribution de probabilité continue ayant pour densité de probabilité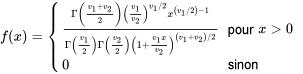 0 \\ 0 & \text { sinon }\end{cases} » title= »f(x)= \begin{cases}\frac{\Gamma\left(\frac{v_1+v_2}\right)\left(\frac{v_1}{v_2}\right)^{v_1 / 2} x^{\left(v_1 / 2\right)-1}}{\Gamma\left(\frac{v_1}\right) \Gamma\left(\frac{v_2}\right)\left(1+\frac{v_1 x}{v_2}\right)^{\left(v_1+v_2\right) / 2}} & \text { pour } x>0 \\ 0 & \text { sinon }\end{cases} » class= »latex mathjax »>
0 \\ 0 & \text { sinon }\end{cases} » title= »f(x)= \begin{cases}\frac{\Gamma\left(\frac{v_1+v_2}\right)\left(\frac{v_1}{v_2}\right)^{v_1 / 2} x^{\left(v_1 / 2\right)-1}}{\Gamma\left(\frac{v_1}\right) \Gamma\left(\frac{v_2}\right)\left(1+\frac{v_1 x}{v_2}\right)^{\left(v_1+v_2\right) / 2}} & \text { pour } x>0 \\ 0 & \text { sinon }\end{cases} » class= »latex mathjax »> .
. (le degré de liberté du numérateur) et
(le degré de liberté du numérateur) et  (le degré de liberté du dénominateur). Les valeurs de
(le degré de liberté du dénominateur). Les valeurs de  et
et  permet de déterminer les quantiles pour de faibles
permet de déterminer les quantiles pour de faibles  la fonction quantile
la fonction quantile  la fonction quantile pour la distribution
la fonction quantile pour la distribution =\frac{Q_{v_, v_}(1-p)}")
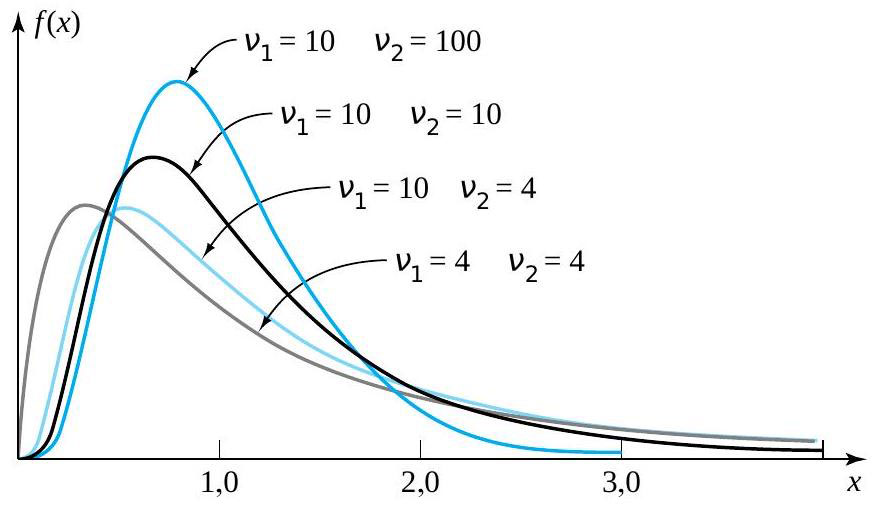
 . Cherchons les quantiles .95 et .01 de la distribution de
. Cherchons les quantiles .95 et .01 de la distribution de 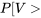 » title= »P[V> » class= »latex mathjax »> 4,0] et <img src= »https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/109e3ebc4e9893167fd000040c2f0f7b.png » alt= »P[V<0,3] » title= »P[V.
» title= »P[V> » class= »latex mathjax »> 4,0] et <img src= »https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/109e3ebc4e9893167fd000040c2f0f7b.png » alt= »P[V<0,3] » title= »P[V. , colonne
, colonne  , ligne
, ligne  , on trouve dans un premier temps le nombre 5,41. Autrement dit,
, on trouve dans un premier temps le nombre 5,41. Autrement dit, =5,41") , ce qui équivaut à dire que <img src= »https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/e87e037cb2d9dc42f354bdabcc0770e6.png » alt= »P[V<5,41]=0,95″ title= »P[V.
, ce qui équivaut à dire que <img src= »https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/e87e037cb2d9dc42f354bdabcc0770e6.png » alt= »P[V<5,41]=0,95″ title= »P[V. de la distribution
de la distribution =\frac{Q_{5,3}(0,99)}")
 et la ligne
et la ligne  de la table de quantiles
de la table de quantiles  , on obtient :
, on obtient :=\frac=0,,04")
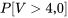 4,0] » title= »P[V>4,0] » class= »latex mathjax »>, on constate (en utilisant la colonne [/latex]v_{1}=3[/latex] et la ligne
4,0] » title= »P[V>4,0] » class= »latex mathjax »>, on constate (en utilisant la colonne [/latex]v_{1}=3[/latex] et la ligne  ), dans la distribution
), dans la distribution  , puis utiliser l’expression (5.2.4.2). En utilisant les colonnes
, puis utiliser l’expression (5.2.4.2). En utilisant les colonnes  et
et  des distributions sous-jacentes. Autrement dit, lorsque
des distributions sous-jacentes. Autrement dit, lorsque  et <img src= »https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/4271702ef47127321ec8a369ddc787e9.png » alt= »s_^
et <img src= »https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/4271702ef47127321ec8a369ddc787e9.png » alt= »s_^ . (
. (  degrés de liberté associés et figure dans le numérateur de cette expression, tandis que
degrés de liberté associés et figure dans le numérateur de cette expression, tandis que  a
a  degrés de liberté associés et figure dans le dénominateur, motivant le langage introduit à la définition 5.2.4.1)
degrés de liberté associés et figure dans le dénominateur, motivant le langage introduit à la définition 5.2.4.1) . Il est par exemple possible de choisir L et U, les bons quantiles F, de sorte que la probabilité que la variable (5.2.4.3) se situe entre L et U corresponde au niveau de confiance souhaité. (L et U sont typiquement choisis de manière à « répartir le manque de confiance » entre les queues
. Il est par exemple possible de choisir L et U, les bons quantiles F, de sorte que la probabilité que la variable (5.2.4.3) se situe entre L et U corresponde au niveau de confiance souhaité. (L et U sont typiquement choisis de manière à « répartir le manque de confiance » entre les queues  <U
<U


 dans les encadrés (5.2.4.5) et (5.2.4.6) correspond à une hypothèse nulle où les variances sont égales. C’est le seul choix communément utilisé en pratique.)
dans les encadrés (5.2.4.5) et (5.2.4.6) correspond à une hypothèse nulle où les variances sont égales. C’est le seul choix communément utilisé en pratique.)
 < # et
< # et 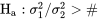 \#" title="\mathrm{H}_{\mathrm{a}}: \sigma_1^2 / \sigma_2^2>\#" class="latex mathjax"> sont (respectivement) les queues de distribution
\#" title="\mathrm{H}_{\mathrm{a}}: \sigma_1^2 / \sigma_2^2>\#" class="latex mathjax"> sont (respectivement) les queues de distribution  , la convention standard est de reporter deux fois la probabilité
, la convention standard est de reporter deux fois la probabilité 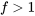 1" title="f>1" class="latex mathjax">, et de reporter deux fois la probabilité
1" title="f>1" class="latex mathjax">, et de reporter deux fois la probabilité  étudiée si
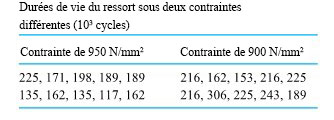
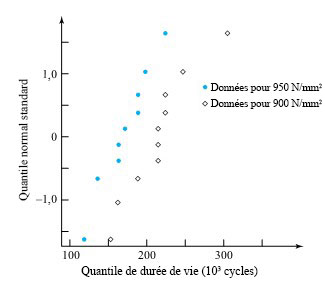
étudiée si  . Une partie de leurs données figurent dans le tableau 5.2.4.1, où sont représentées les mesures de dureté de Rockwell pour dix échantillons provenant d’un lot d’acier à traitement thermique et cinq échantillons provenant d’un lot d’acier laminé à froid.
. Une partie de leurs données figurent dans le tableau 5.2.4.1, où sont représentées les mesures de dureté de Rockwell pour dix échantillons provenant d’un lot d’acier à traitement thermique et cinq échantillons provenant d’un lot d’acier laminé à froid.

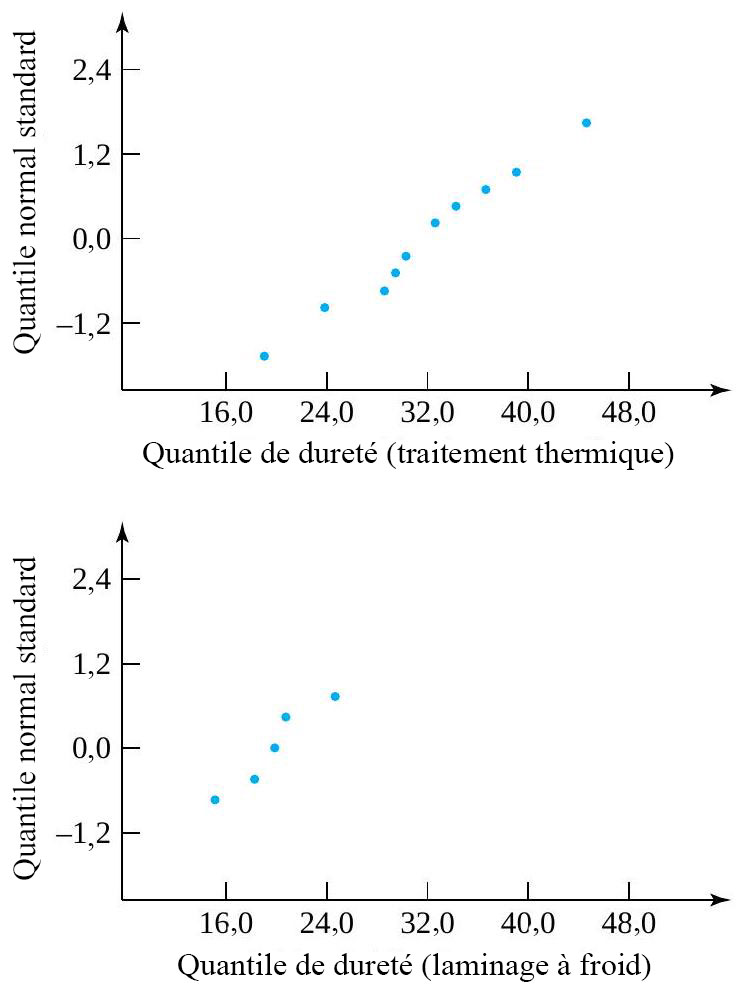
 et
et  ; un test d’hypothèse d’égalité des variances en cinq étapes reposant sur la variable (5.2.4.6) se présente comme suit :
; un test d’hypothèse d’égalité des variances en cinq étapes reposant sur la variable (5.2.4.6) se présente comme suit :![]\mathrm{H}_{0}: \frac{\sigma_^}{\sigma_^}=1](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/48b5d327892768d2dc3bab2f2eb7f65a.png "]\mathrm{H}_{0}: \frac{\sigma_^}{\sigma_^}=1")


 , et
, et  sera infirmée si la valeur observée de f est soit grande, soit petite.
sera infirmée si la valeur observée de f est soit grande, soit petite.^}{(3,52)^}=4,6")
![2 P\left[\text { une variable aléatoire } F_{9,4} \text { } \geq 4,6\right]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/0536231e06063adb1b166b4daff68e4f.png "2 P\left[\text { une variable aléatoire } F_{9,4} \text { } \geq 4,6\right]")
 . Comme le quantile 0,95 de la distribution
. Comme le quantile 0,95 de la distribution  vaut 3,63, le quantile .05 de la distribution
vaut 3,63, le quantile .05 de la distribution  . Ainsi, l’intervalle de confiance de 90 % pour le rapport d’écarts-types
. Ainsi, l’intervalle de confiance de 90 % pour le rapport d’écarts-types ^}{6,0(3,52)^}} \text { et } \sqrt{\frac{(7,52)^}{(1 / 3,63)(3,52)^}}")
 /
/ était de l’ordre de 1,5. Selon leurs calculs, il faudrait tout au plus deux ans pour que l’entreprise récupère les coûts requis pour équiper tous les massicots de freins automatiques.
était de l’ordre de 1,5. Selon leurs calculs, il faudrait tout au plus deux ans pour que l’entreprise récupère les coûts requis pour équiper tous les massicots de freins automatiques.
 , si n (le nombre de données appariées) est élevé, les bornes de l’intervalle de confiance pour la différence moyenne sous-jacente
, si n (le nombre de données appariées) est élevé, les bornes de l’intervalle de confiance pour la différence moyenne sous-jacente  sont
sont
 est l’écart-type de l’échantillon d1, d2, …,
est l’écart-type de l’échantillon d1, d2, …,



 =−0,0008 po et
=−0,0008 po et  = 0,0023 po. Effectuons un test d’hypothèse en cinq étapes pour voir s’il est plausible d’affirmer que l’écart est constant :
= 0,0023 po. Effectuons un test d’hypothèse en cinq étapes pour voir s’il est plausible d’affirmer que l’écart est constant :

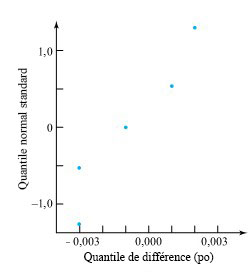
 | ≥0,78], ce qui, d’après le tableau A1.2, est supérieur à 2(0,10) = 0,2. Les données ne se montrent pas en faveur d’une différence systématique entre les mesures des bords avant et arrière.
| ≥0,78], ce qui, d’après le tableau A1.2, est supérieur à 2(0,10) = 0,2. Les données ne se montrent pas en faveur d’une différence systématique entre les mesures des bords avant et arrière.
 =−0,0008, n’est que le résultat de la variabilité d’échantillonnage.
=−0,0008, n’est que le résultat de la variabilité d’échantillonnage.

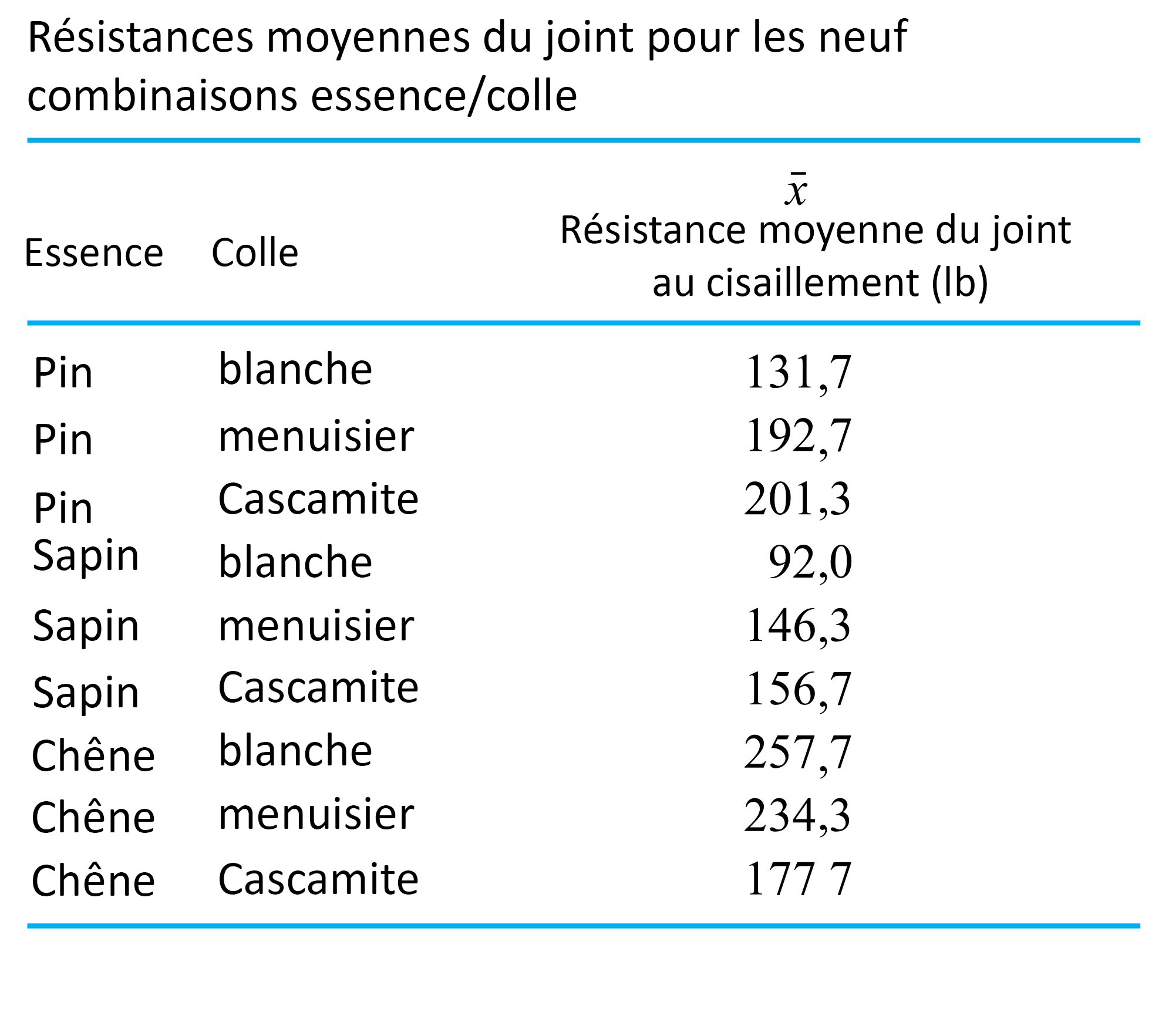
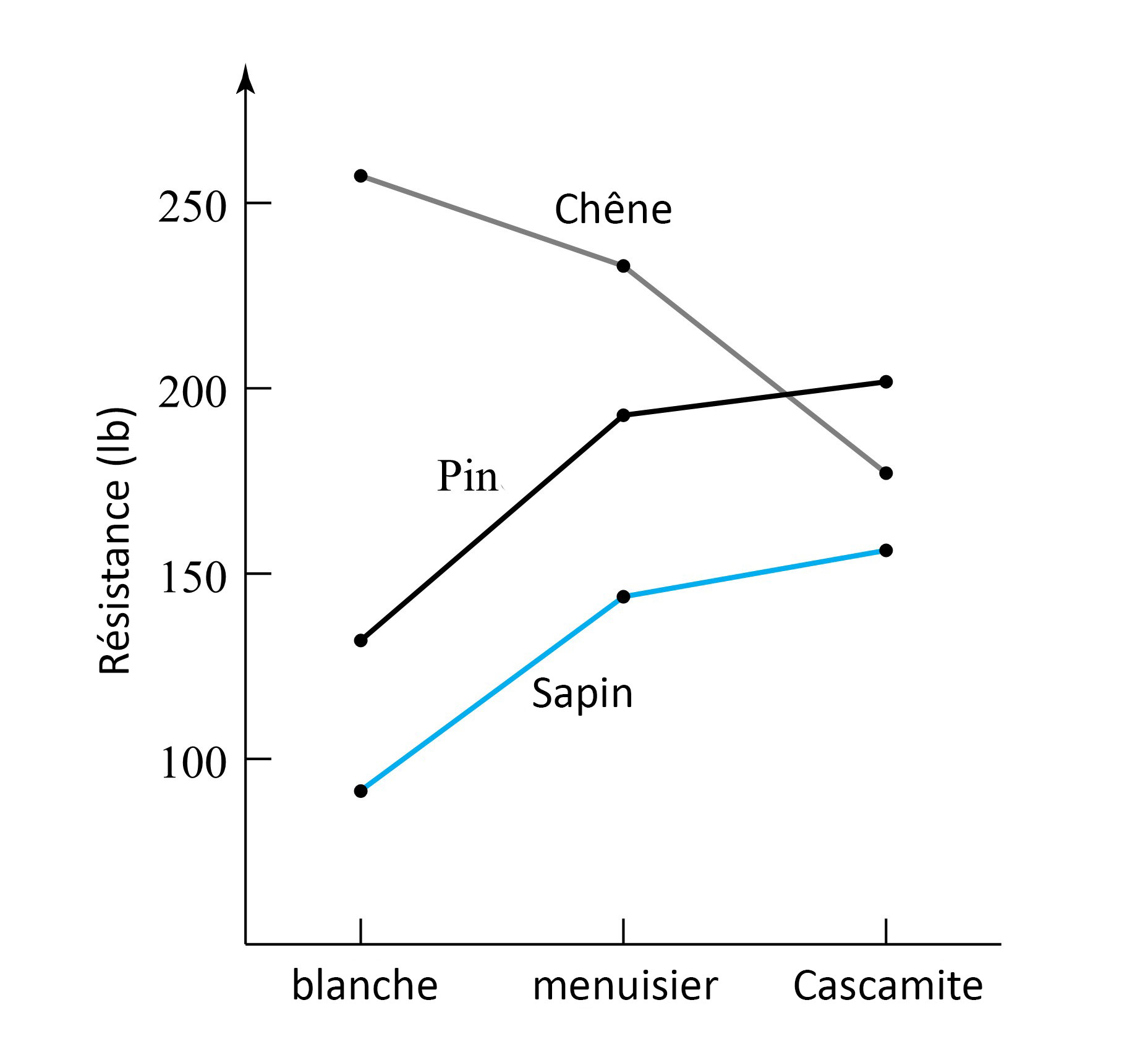
 revient à établir un diagramme de dispersion de la résistance à la compression en fonction du numéro de la formule. Ce diagramme est présenté à la figure 6.1.1.1. Ce qui ressort globalement de la figure 6.1.1.1, c’est que les moyennes de résistance à la compression sont nettement différentes d’une formule à l’autre, mais que leurs variabilités sont à peu près comparables.
revient à établir un diagramme de dispersion de la résistance à la compression en fonction du numéro de la formule. Ce diagramme est présenté à la figure 6.1.1.1. Ce qui ressort globalement de la figure 6.1.1.1, c’est que les moyennes de résistance à la compression sont nettement différentes d’une formule à l’autre, mais que leurs variabilités sont à peu près comparables.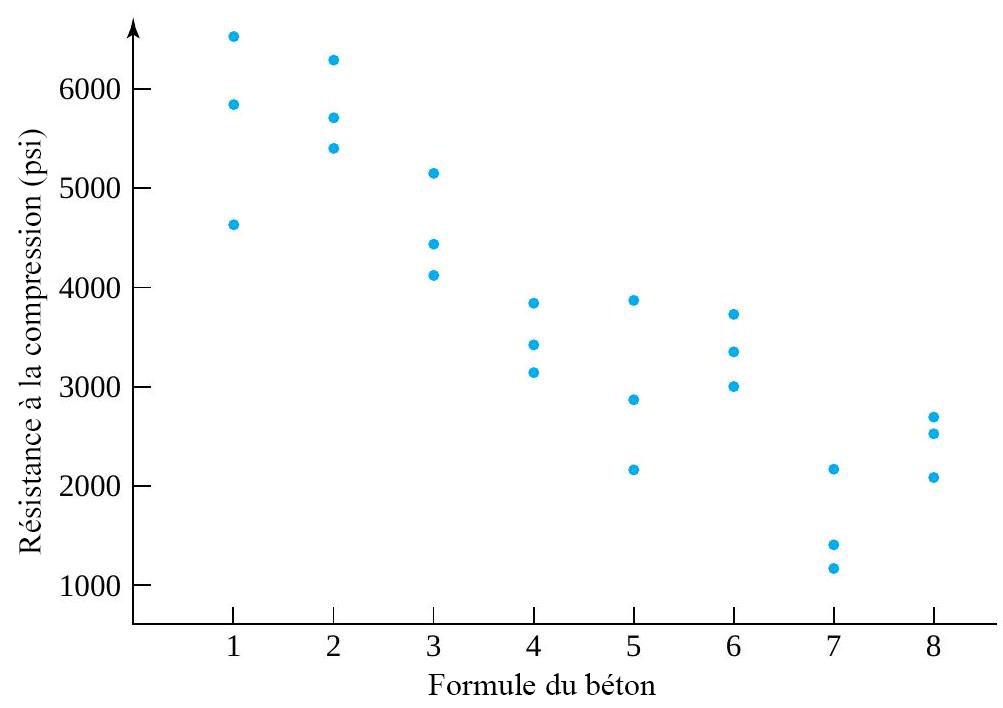
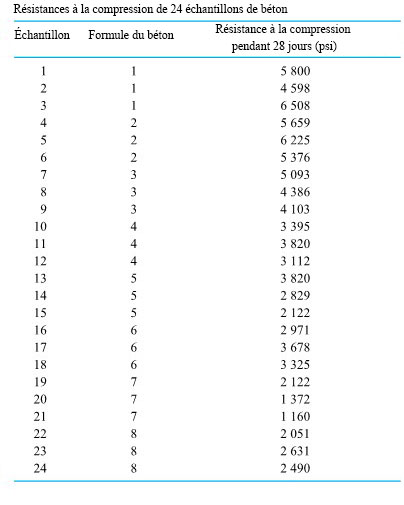
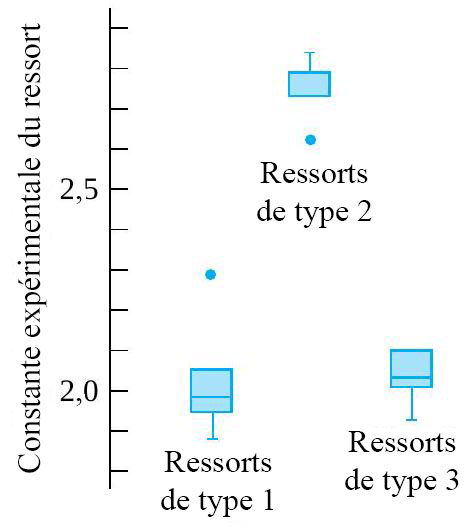
 ressorts de type 1 (conception 4 po avec constante de ressort théorique de 1,86),
ressorts de type 1 (conception 4 po avec constante de ressort théorique de 1,86),  ressorts de type 2 (conception 6 po avec constante de ressort théorique de 2,63) et
ressorts de type 2 (conception 6 po avec constante de ressort théorique de 2,63) et  ressorts de type 3 (conception 4 po avec constante de ressort théorique de 2,12), en utilisant une charge de
ressorts de type 3 (conception 4 po avec constante de ressort théorique de 2,12), en utilisant une charge de  . Les valeurs expérimentales figurent dans le tableau 6.1.1.2.
. Les valeurs expérimentales figurent dans le tableau 6.1.1.2. , mais qu’aucune différence entre les deux types de ressorts 4 po n’est évidente. Évidemment, les informations du tableau 6.1.1.2 peuvent également être présentées sous forme de diagramme de dispersion côte à côte, comme dans la figure 6.1.1.3.
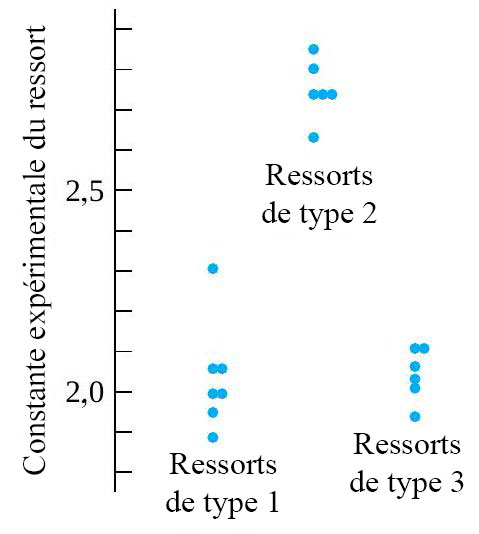
, mais qu’aucune différence entre les deux types de ressorts 4 po n’est évidente. Évidemment, les informations du tableau 6.1.1.2 peuvent également être présentées sous forme de diagramme de dispersion côte à côte, comme dans la figure 6.1.1.3.
 échantillons, de tailles respectives
échantillons, de tailles respectives  sont indépendants et suivent des distributions normales, avec une variance commune de
sont indépendants et suivent des distributions normales, avec une variance commune de  de ce modèle à un facteur (contrairement aux modèles à plusieurs facteurs) a amené des méthodes d’inférence pratiques pour
de ce modèle à un facteur (contrairement aux modèles à plusieurs facteurs) a amené des méthodes d’inférence pratiques pour  , cette version générale permettra d’utiliser de nombreuses méthodes d’inférence pratiques pour les études utilisant
, cette version générale permettra d’utiliser de nombreuses méthodes d’inférence pratiques pour les études utilisant 


 est la
est la  ,
,  sont des variables aléatoires normales indépendantes de moyenne 0 et de variance
sont des variables aléatoires normales indépendantes de moyenne 0 et de variance  et la variance
et la variance 







 réponse déterministe + bruit
réponse déterministe + bruit ") sont censées représenter approximativement la part déterministe de la réponse du système
sont censées représenter approximativement la part déterministe de la réponse du système ") .
.") sont donc censés représenter approximativement le bruit correspondant dans la réponse
sont donc censés représenter approximativement le bruit correspondant dans la réponse ") .
. de l’équation 6.1.2.1 sont supposés être des variables aléatoires normales indépendantes et identiquement distribuées (iid)
de l’équation 6.1.2.1 sont supposés être des variables aléatoires normales indépendantes et identiquement distribuées (iid) ") laisse alors supposer que les
laisse alors supposer que les  devraient au moins à peu près ressembler à un échantillon aléatoire suivant une distribution normale.
devraient au moins à peu près ressembler à un échantillon aléatoire suivant une distribution normale. soit plus de trois fois plus grand que
soit plus de trois fois plus grand que  . Mais les échantillons sont si petits (
. Mais les échantillons sont si petits ( échantillons de taille 3 suivant une distribution normale) que ce n’est pas si inhabituel de voir un rapport de l’ordre de 3,2 entre le plus grand et le plus petit écart-type. À noter que d’après les tables
échantillons de taille 3 suivant une distribution normale) que ce n’est pas si inhabituel de voir un rapport de l’ordre de 3,2 entre le plus grand et le plus petit écart-type. À noter que d’après les tables ^ \approx 10,2") donnerait, pour les échantillons de taille 3, une valeur
donnerait, pour les échantillons de taille 3, une valeur  résidus. Le tableau 6.1.2.2 présente certains calculs nécessaires pour obtenir les résidus des données du tableau 6.1.1.1 (en utilisant les valeurs ajustées figurant dans le tableau 6.1.2.1 en tant que moyennes d’échantillons) sont présentés dans. Les figures 6.1.2.2 et 6.1.2.3 représentent respectivement un tracé de résidus en fonction de
résidus. Le tableau 6.1.2.2 présente certains calculs nécessaires pour obtenir les résidus des données du tableau 6.1.1.1 (en utilisant les valeurs ajustées figurant dans le tableau 6.1.2.1 en tant que moyennes d’échantillons) sont présentés dans. Les figures 6.1.2.2 et 6.1.2.3 représentent respectivement un tracé de résidus en fonction de  en fonction de
en fonction de ") et un tracé normal des 24 résidus.
et un tracé normal des 24 résidus.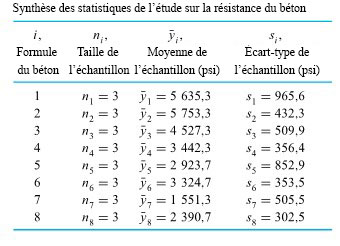
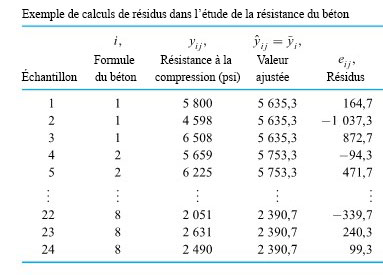
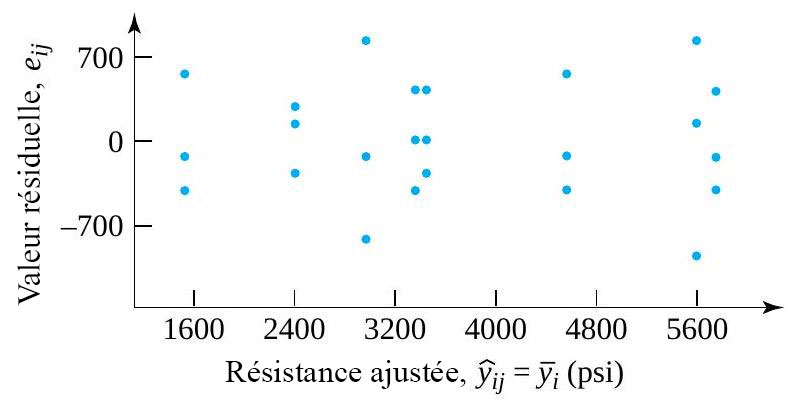
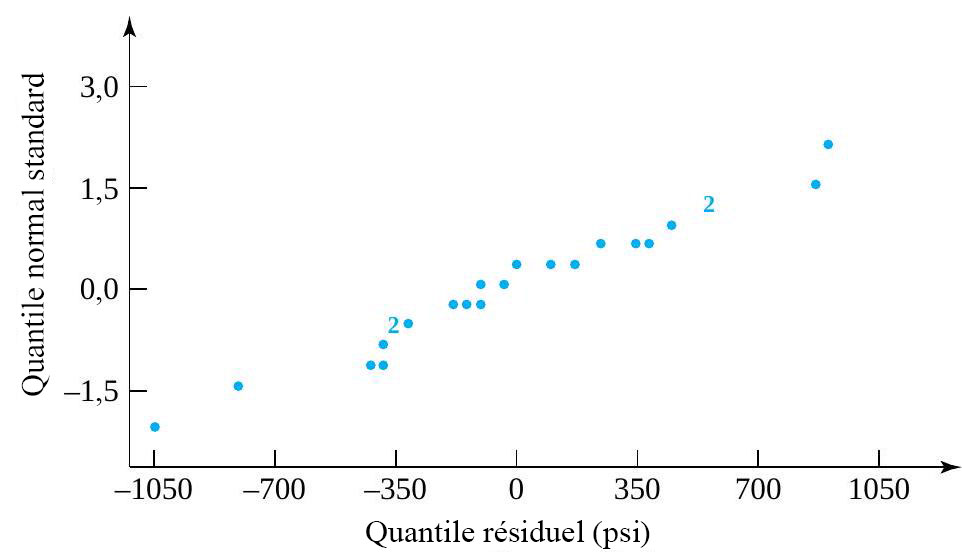
^=4,38\right)") ne suffit pas pour abandonner la description de modèle à un facteur des constantes de ressort. (On constate dans les tables
ne suffit pas pour abandonner la description de modèle à un facteur des constantes de ressort. (On constate dans les tables  et
et  . Par conséquent, même s’il y avait seulement deux échantillons et non trois, un rapport de variance de 4,38 donnerait une valeur
. Par conséquent, même s’il y avait seulement deux échantillons et non trois, un rapport de variance de 4,38 donnerait une valeur  sont suffisamment grandes pour qu’il soit pertinent d’observer les tracés normaux des données constantes des ressorts échantillon par échantillon. La figure 6.1.2.4 présente ces tracés, réalisés sur les mêmes axes. De plus, l’utilisation des valeurs ajustées
sont suffisamment grandes pour qu’il soit pertinent d’observer les tracés normaux des données constantes des ressorts échantillon par échantillon. La figure 6.1.2.4 présente ces tracés, réalisés sur les mêmes axes. De plus, l’utilisation des valeurs ajustées ") du tableau 6.1.2.3, dont les données originales proviennent du tableau 6.1.1.2, produit 19 résidus, comme l’illustre en partie le tableau 6.1.2.4. Les figures 6.1.2.5 et 6.1.2.6 montrent ensuite respectivement un tracé de résidus en fonction des réponses ajustées, et un tracé normal de l’ensemble des 19 résidus.
du tableau 6.1.2.3, dont les données originales proviennent du tableau 6.1.1.2, produit 19 résidus, comme l’illustre en partie le tableau 6.1.2.4. Les figures 6.1.2.5 et 6.1.2.6 montrent ensuite respectivement un tracé de résidus en fonction des réponses ajustées, et un tracé normal de l’ensemble des 19 résidus.
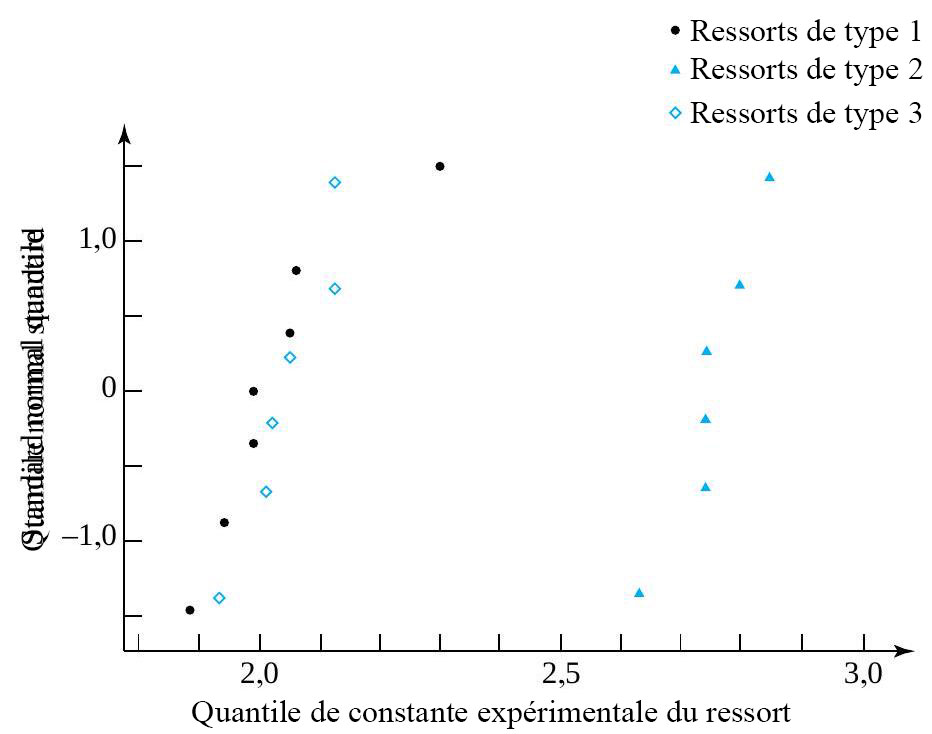
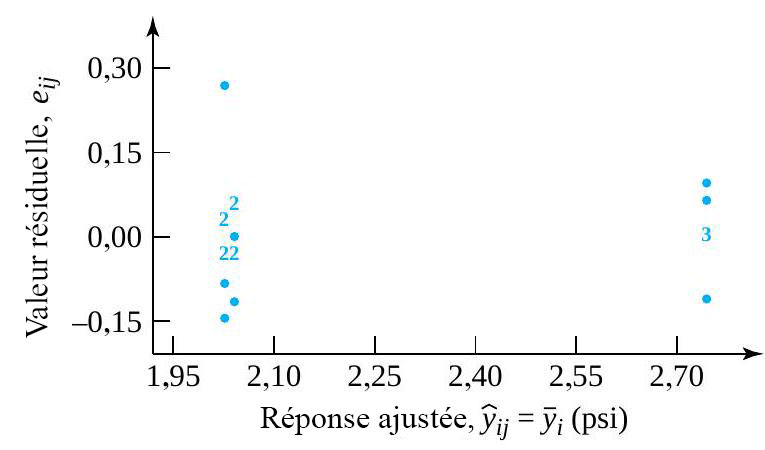
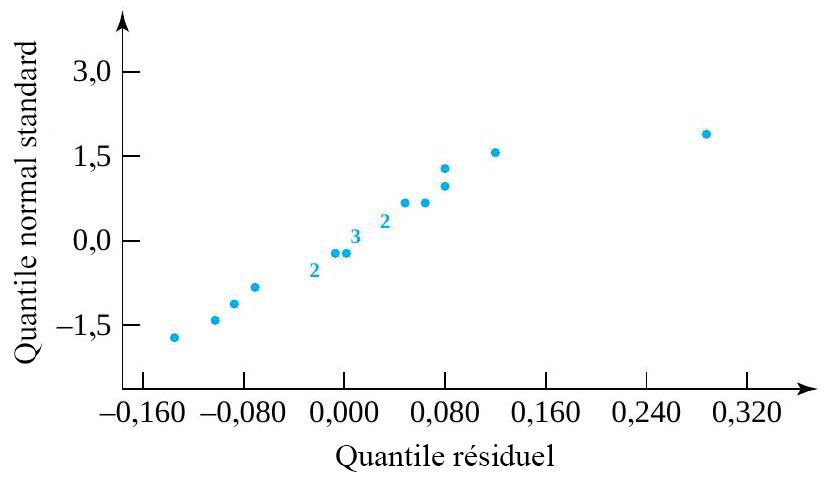
 . À l’image de ce qui a été fait dans le cas
. À l’image de ce qui a été fait dans le cas  , la variance pondérée,
, la variance pondérée,  est la moyenne pondérée des variances d’échantillons, où les coefficients de pondération équivalent aux tailles des échantillons moins 1 :
est la moyenne pondérée des variances d’échantillons, où les coefficients de pondération équivalent aux tailles des échantillons moins 1 :s_1^2+\left(n_2-1\right) s_2^2+\cdots+\left(n_{r}-1\right) s_{r}^2}{\left(n_1-1\right)+\left(n_2-1\right)+\cdots+\left(n_{r}-1\right)}")
 , correspond à la racine carrée de
, correspond à la racine carrée de  .
. avec deux échantillons,
avec deux échantillons,  ; c’est une sorte de compromis pratique pour cette valeur sur le plan mathématique.
; c’est une sorte de compromis pratique pour cette valeur sur le plan mathématique.
=\sum_{i=1}^{r} n_{i}-\sum_{i=1}^{r} 1=n-r")
^2")
\left(\frac{1 }{\left(n_{i}-1\right)} \sum_{j=1}^{n_{i}}\left(y_{i j}-\bar{y}_{i}\right)^2\right) & =\sum_{i=1}^{r} \sum_{j=1}^{n_{i}}\left(y_{i j}-\bar{y}_{i}\right)^2 \\& =\sum_{i=1}^{r} \sum_{j=1}^{n_{i}} e_{i j}^2\end{aligned}")

 .
. vaut 3, et les valeurs
vaut 3, et les valeurs ![\begin{aligned} s_{\mathrm{P}}^2 & =\frac{(3-1)(965,6)^2+(3-1)(432,3)^2+\cdots+(3-1)(302,5)^2}{(3-1)+(3-1)+\cdots+(3-1)} \\ & =\frac{2\left[(965,6)^2+(432,3)^2+\cdots+(302,5)^2\right]}{16 } \\ & =\frac{2 705 705}{8 } \\ & =338 213(\mathrm{psi})^2 \end{aligned}](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/23f6d727ecf83a1328d7d9195af31d01.png "\begin{aligned} s_{\mathrm{P}}^2 & =\frac{(3-1)(965,6)^2+(3-1)(432,3)^2+\cdots+(3-1)(302,5)^2}{(3-1)+(3-1)+\cdots+(3-1)} \\ & =\frac{2\left[(965,6)^2+(432,3)^2+\cdots+(302,5)^2\right]}{16 } \\ & =\frac{2 705 705}{8 } \\ & =338 213(\mathrm{psi})^2 \end{aligned}")


 s_{\mathrm{P}}^2}{\sigma^2}")
 . Ainsi, de la même façon que pour la dérivation de la partie 5, l’intervalle de confiance bilatéral pour
. Ainsi, de la même façon que pour la dérivation de la partie 5, l’intervalle de confiance bilatéral pour  a pour bornes
a pour bornes s_{\mathrm{P}}^2}{U} \text { et } \frac{(n-r) s_{\mathrm{P}}^2}{L}" title="\sigma^2") a pour bornes
a pour bornes](https://atu0g9ctah.execute-api.ca-central-1.amazonaws.com/latest/latex?latex=%5Cfrac%7B%28n-r%29%20s_%7B%5Cmathrm%7BP%7D%7D%5E2%7D%7BU%7D%20%5Ctext%20%7B%20et%20%7D%20%5Cfrac%7B%28n-r%29%20s_%7B%5Cmathrm%7BP%7D%7D%5E2%7D%7BL%7D%22%20class%3D%22latex%20mathjax%22%3E%3C%2Fdiv%3E%20%20%3Cdiv%3Eo%C3%B9%20%3Cimg%20class%3D%22latex%20mathjax%22%20title%3D%22L%22%20src%3D%22https%3A%2F%2Fecampusontario.pressbooks.pub%2Fapp%2Fuploads%2Fsites%2F4171%2F2024%2F03%2Fc351fc4eea42f12951c801665e19ef99.png%22%20alt%3D%22L%22%20%2F%3E%20et%20%3Cimg%20class%3D%22latex%20mathjax%22%20title%3D%22U%22%20src%3D%22https%3A%2F%2Fecampusontario.pressbooks.pub%2Fapp%2Fuploads%2Fsites%2F4171%2F2024%2F03%2F445f6a1cb478a086dc6d72f45bd683f1.png%22%20alt%3D%22U%22%20%2F%3E%20sont%20telles%20que%20la%20probabilit%C3%A9%20%3Cimg%20class%3D%22latex%20mathjax%22%20title%3D%22%5Cchi_%7Bn-r%7D%5E2%22%20src%3D%22https%3A%2F%2Fecampusontario.pressbooks.pub%2Fapp%2Fuploads%2Fsites%2F4171%2F2024%2F03%2Fb37c9112ea2be746634852fd7f84659c.png%22%20alt%3D%22%5Cchi_%7Bn-r%7D%5E2%22%20%2F%3E%20assign%C3%A9e%20%C3%A0%20l%E2%80%99intervalle%20%3Cimg%20class%3D%22latex%20mathjax%22%20title%3D%22%28L%2C%20U%29%22%20src%3D%22https%3A%2F%2Fecampusontario.pressbooks.pub%2Fapp%2Fuploads%2Fsites%2F4171%2F2024%2F03%2Fdfbe036423bf3c8382340d982a28d40d.png%22%20alt%3D%22%28L%2C%20U%29%22%20%2F%3E%20correspond%20au%20niveau%20de%20confiance%20souhait%C3%A9.%20Et%20bien%20s%C3%BBr%2C%20on%20peut%20obtenir%20un%20intervalle%20unilat%C3%A9ral%20en%20utilisant%20uniquement%20l%E2%80%99une%20des%20bornes%C2%A06.1.3.4%20et%20en%20choisissant%20une%20valeur%20%3Cimg%20class%3D%22latex%20mathjax%22%20title%3D%22U%22%20src%3D%22https%3A%2F%2Fecampusontario.pressbooks.pub%2Fapp%2Fuploads%2Fsites%2F4171%2F2024%2F03%2F445f6a1cb478a086dc6d72f45bd683f1.png%22%20alt%3D%22U%22%20%2F%3E%20ou%20%3Cimg%20class%3D%22latex%20mathjax%22%20title%3D%22L%22%20src%3D%22https%3A%2F%2Fecampusontario.pressbooks.pub%2Fapp%2Fuploads%2Fsites%2F4171%2F2024%2F03%2Fc351fc4eea42f12951c801665e19ef99.png%22%20alt%3D%22L%22%20%2F%3E%20telle%20que%20la%20probabilit%C3%A9%20%3Cimg%20class%3D%22latex%20mathjax%22%20title%3D%22%5Cchi_%7Bn-r%7D%5E2%22%20src%3D%22https%3A%2F%2Fecampusontario.pressbooks.pub%2Fapp%2Fuploads%2Fsites%2F4171%2F2024%2F03%2Fb37c9112ea2be746634852fd7f84659c.png%22%20alt%3D%22%5Cchi_%7Bn-r%7D%5E2%22%20%2F%3E%20assign%C3%A9e%20%C3%A0%20l%E2%80%99intervalle%20%5Blatex%5D%280%2C%20U%29&fg=000000&font=TeX&svg=1 "\frac{(n-r) s_{\mathrm{P}}^2}{U} \text { et } \frac{(n-r) s_{\mathrm{P}}^2}{L}" class="latex mathjax"></div> <div>où <img class="latex mathjax" title="L" src="https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/c351fc4eea42f12951c801665e19ef99.png" alt="L" /> et <img class="latex mathjax" title="U" src="https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/445f6a1cb478a086dc6d72f45bd683f1.png" alt="U" /> sont telles que la probabilité <img class="latex mathjax" title="\chi_{n-r}^2" src="https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/b37c9112ea2be746634852fd7f84659c.png" alt="\chi_{n-r}^2" /> assignée à l’intervalle <img class="latex mathjax" title="(L, U)" src="https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/dfbe036423bf3c8382340d982a28d40d.png" alt="(L, U)" /> correspond au niveau de confiance souhaité. Et bien sûr, on peut obtenir un intervalle unilatéral en utilisant uniquement l’une des bornes 6.1.3.4 et en choisissant une valeur <img class="latex mathjax" title="U" src="https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/445f6a1cb478a086dc6d72f45bd683f1.png" alt="U" /> ou <img class="latex mathjax" title="L" src="https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/c351fc4eea42f12951c801665e19ef99.png" alt="L" /> telle que la probabilité <img class="latex mathjax" title="\chi_{n-r}^2" src="https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/b37c9112ea2be746634852fd7f84659c.png" alt="\chi_{n-r}^2" /> assignée à l’intervalle [latex](0, U)") ou
ou ") correspond au niveau de confiance souhaité.
correspond au niveau de confiance souhaité. pour
pour  degrés de liberté sont associés à
degrés de liberté sont associés à  . On lit alors respectivement 7,962 et 26,296. Ainsi, l’intervalle de confiance pour
. On lit alors respectivement 7,962 et 26,296. Ainsi, l’intervalle de confiance pour ^2}{26,296} \text { et } \frac{16(581,6)^2}{7,962}")
^2}{26,296}} \text { et } \sqrt{\frac{16(581,6)^2}{7,962}}")


 . Par conséquent, l’intervalle de confiance bilatéral pour la
. Par conséquent, l’intervalle de confiance bilatéral pour la 
 et
et  à
à  , la variable
, la variable}{s_{\mathrm{P}} \sqrt{\frac{n_{i}}+\frac{n_{i^{\prime}}}}}")
 a pour bornes
a pour bornes
 .
.") (avec
(avec  0″ title= »t>0″ class= »latex mathjax »> ). L’avantage des formules 6.2.1.1 et 6.2.1.2 (lorsqu’on peut les appliquer), en comparaison avec les formules correspondantes de la partie 5, c’est que pour un niveau de confiance donné, elles ont tendance à produire des intervalles plus courts.
0″ title= »t>0″ class= »latex mathjax »> ). L’avantage des formules 6.2.1.1 et 6.2.1.2 (lorsqu’on peut les appliquer), en comparaison avec les formules correspondantes de la partie 5, c’est que pour un niveau de confiance donné, elles ont tendance à produire des intervalles plus courts. et
et  . Le quantile 0,95 de la distribution
. Le quantile 0,95 de la distribution  , à savoir 1,746, peut alors être utilisé dans les deux formules 6.2.1.1 et 6.2.1.2.
, à savoir 1,746, peut alors être utilisé dans les deux formules 6.2.1.1 et 6.2.1.2. valent 3, la partie ± de la formule 6.2.1.1 donne :
valent 3, la partie ± de la formule 6.2.1.1 donne :
 psi pourrait être rattachée à n’importe laquelle des moyennes d’échantillon du Tableau 6.2.1.1 comme estimation de la résistance moyenne de la formule correspondante. Par exemple, comme
psi pourrait être rattachée à n’importe laquelle des moyennes d’échantillon du Tableau 6.2.1.1 comme estimation de la résistance moyenne de la formule correspondante. Par exemple, comme  psi, l’intervalle de confiance bilatéral de
psi, l’intervalle de confiance bilatéral de  a pour bornes
a pour bornes

 \sqrt{\frac{ 1}{ 3}+\frac{ 1}{ 3}}=829,1 \mathrm{psi}")
 psi pourrait être rattachée à n’importe quelle différence entre les moyennes d’échantillons du tableau 6.2.1.1 comme estimation des résistances moyennes de la différence des formules correspondante. Par exemple, étant donné que
psi pourrait être rattachée à n’importe quelle différence entre les moyennes d’échantillons du tableau 6.2.1.1 comme estimation des résistances moyennes de la différence des formules correspondante. Par exemple, étant donné que  , l’intervalle de confiance bilatéral de
, l’intervalle de confiance bilatéral de  a pour bornes
a pour bornes \pm 829,1")

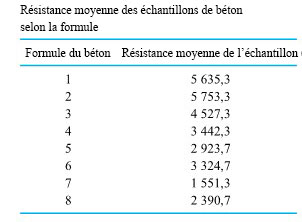
 et de
et de  reflète la baisse de l’incertitude associée à l’utilisation de
reflète la baisse de l’incertitude associée à l’utilisation de ")
 intervalles de confiance ont des niveaux de confiance associés
intervalles de confiance ont des niveaux de confiance associés  , le niveau de confiance simultané ou conjoint valable pour tous les
, le niveau de confiance simultané ou conjoint valable pour tous les  ) satisfait à
) satisfait à+\left(1-\gamma_2\right)+\cdots+\left(1-\gamma_{k}\right)\right)")
") conjointe des
conjointe des  présentent un niveau de confiance conjoint ou simultané d’au moins 95 %.)
présentent un niveau de confiance conjoint ou simultané d’au moins 95 %.)}{ 2}") paires de réponses moyennes
paires de réponses moyennes  . La section 6.2 affirme qu’estimer une différence unique entre les réponses de moyenne
. La section 6.2 affirme qu’estimer une différence unique entre les réponses de moyenne  et
et  et
et  et
et  et
et  , et
, et  et
et  ). Si on veut garantir un niveau de confiance simultané raisonnable pour toutes ces comparaisons en utilisant l’inégalité rudimentaire de Bonferroni, il faut un très haut niveau de confiance individuel pour les intervalles 6.2.3.1. Par exemple, avec 28 intervalles, il faut un niveau de confiance de
). Si on veut garantir un niveau de confiance simultané raisonnable pour toutes ces comparaisons en utilisant l’inégalité rudimentaire de Bonferroni, il faut un très haut niveau de confiance individuel pour les intervalles 6.2.3.1. Par exemple, avec 28 intervalles, il faut un niveau de confiance de  pour pouvoir garantir un niveau de confiance simultané de
pour pouvoir garantir un niveau de confiance simultané de  .
. , de sorte que l’ensemble d’intervalles bilatéraux ayant pour bornes
, de sorte que l’ensemble d’intervalles bilatéraux ayant pour bornes
 ) dans la table A5A ou
) dans la table A5A ou  0,99) dans la table A5B) pour l’estimation de toutes les différences
0,99) dans la table A5B) pour l’estimation de toutes les différences  ).
). \sqrt{\frac{1 }{ 3}+\frac{1 }{ 3}}")

 \sqrt{\frac{1 }{ 3}+\frac{1 }{ 3}}")

 de la table A5A.)
de la table A5A.)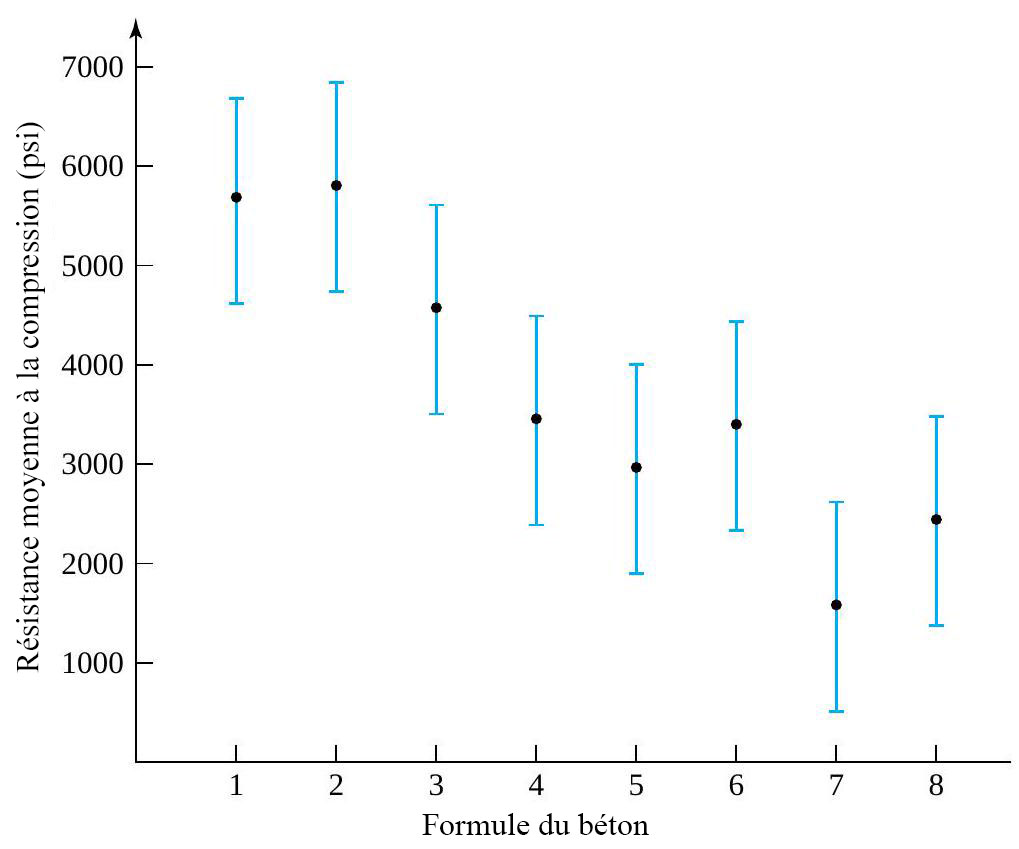


=0")



 et # correctement.
et # correctement.



 , le nombre d’observations disponibles, en ignorant le nombre total d’échantillons (
, le nombre d’observations disponibles, en ignorant le nombre total d’échantillons ( la moyenne du grand échantillon de la réponse
la moyenne du grand échantillon de la réponse 
 , et la moyenne pondérée des moyennes d’échantillons
, et la moyenne pondérée des moyennes d’échantillons  . En contrepartie,
. En contrepartie,  et
et  ,
,=\frac{ 2}{ 5} \bar{y}_1+\frac{3 }{ 5} \bar{y}_2")
=\frac{ 1}{4 } y_{ 11}+\frac{1 }{ 4} y_{ 12}+\frac{ 1}{ 6} y_{2 1}+\frac{ 1}{ 6} y_{ 22}+\frac{ 1}{ 6} y_{ 23}")
, \bar{y}") est une estimation naturelle de la moyenne commune. (Toutes les distributions sous-jacentes sont les mêmes; les données disponibles sont donc considérées, à juste titre, non pas comme
est une estimation naturelle de la moyenne commune. (Toutes les distributions sous-jacentes sont les mêmes; les données disponibles sont donc considérées, à juste titre, non pas comme  sont donc des indicateurs de différences potentielles parmi les
sont donc des indicateurs de différences potentielles parmi les ^2")
^2") , soit comme une somme non pondérée, avec un terme de la somme pour chaque point de données brutes, donc
, soit comme une somme non pondérée, avec un terme de la somme pour chaque point de données brutes, donc  s_{\mathrm{p}}^2") . On obtient alors :
. On obtient alors :^2}{s_{\mathrm{P}}^2}")
 . L’hypothèse d’égalité de
. L’hypothèse d’égalité de  : pas
: pas  . et les 8 moyennes d’échantillons
. et les 8 moyennes d’échantillons  , dans cette situation :
, dans cette situation :^2= & 3(1 941,7)^2+3(2 059,7)^2+\cdots \\ & +3(-2 142,3)^2+3(-1 302,9)^2 \end{aligned}")
^2")
}{(581,6)^2}=20,0")
 . On a donc :
. On a donc : ne sont pas toutes égales.
ne sont pas toutes égales.
 s^2=\sum_{i=1}^{r} n_{i}\left(\bar{y}_{i}-\bar{y}\right)^2+(n-r) s_{\mathrm{P}}^2")
^2=\sum_{i=1}^{r} n_{i}\left(\bar{y}_{i}-\bar{y}\right)^2+\sum_{i=1}^{r} \sum_{j=1}^{n_{i}}\left(y_{i j}-\bar{y}_{i}\right)^2")
 s^2=\sum_{i, j}\left(y_{i j}-\bar{y}\right)^2")
 s_{\mathrm{P}}^2=\sum_{i=1}^{r} \sum_{j=1}^{n_{i}}\left(y_{i j}-\bar{y}_{i}\right)^2")
 s^2") , est appelée somme totale des carrés et notée SCTot.
, est appelée somme totale des carrés et notée SCTot.^2") est appelée somme des carrés des traitements et notée SCTr.
est appelée somme des carrés des traitements et notée SCTr.^2") (qui équivaut à
(qui équivaut à  s_{\mathrm{p}}^2") dans un cas non structuré) est appelée somme des carrés d’erreur résiduelle et notée SCE.
dans un cas non structuré) est appelée somme des carrés d’erreur résiduelle et notée SCE.
 des
des  SS (de la source), degrés de liberté df (de la source), carré de la moyenne MS (de la source), et
SS (de la source), degrés de liberté df (de la source), carré de la moyenne MS (de la source), et  (pour le test d’hypothèse de la contribution de la source dans la variabilité globale observée). Dans la colonne Source du tableau, les entrées sont Traitements, Erreur et Total. Mais le terme « traitements » peut parfois être remplacé par « inter (échantillons) », et « Erreur » par « intra (échantillons) » ou « résiduel ». La somme des deux premières entrées de la colonne SC (SS) doit correspondre à la troisième, comme indiqué par l’équation 6.3.3.3. De même, la somme des degrés de liberté pour les traitements et l’erreur donne le nombre total de degrés de liberté,
(pour le test d’hypothèse de la contribution de la source dans la variabilité globale observée). Dans la colonne Source du tableau, les entrées sont Traitements, Erreur et Total. Mais le terme « traitements » peut parfois être remplacé par « inter (échantillons) », et « Erreur » par « intra (échantillons) » ou « résiduel ». La somme des deux premières entrées de la colonne SC (SS) doit correspondre à la troisième, comme indiqué par l’équation 6.3.3.3. De même, la somme des degrés de liberté pour les traitements et l’erreur donne le nombre total de degrés de liberté, ") . À noter que les entrées de la colonne
. À noter que les entrées de la colonne  sont respectivement liées au numérateur et au dénominateur de la statistique de test dans l’équation 6.3.2.3. Les rapports entre les sommes des carrés et les degrés de liberté sont appelés carrés de moyennes; ici, le carré de la moyenne pour les traitements (MSTr) et le carré de la moyenne pour l’erreur (MSE). Dans le cas présent, il faut vérifier que
sont respectivement liées au numérateur et au dénominateur de la statistique de test dans l’équation 6.3.2.3. Les rapports entre les sommes des carrés et les degrés de liberté sont appelés carrés de moyennes; ici, le carré de la moyenne pour les traitements (MSTr) et le carré de la moyenne pour l’erreur (MSE). Dans le cas présent, il faut vérifier que  et que
et que  est le numérateur de la statistique
est le numérateur de la statistique 
 s^2 \\ = & (5 800-3 693,6)^2+(4 598-3 ,693,6)^2+(6 508-3 693,6)^2 \\ & +\cdots+(2 631-3 693,6)^2+(2 490-3 693,6)^2 \\ = & 52 \: 772 \: 190 \text{ psi}^2 \end{aligned}")
 et
et  s_{\mathrm{P}}^2=5 \: 411 \: 410 \text{ psi}^2")
^2=47 \: 360 \: 780")
 .
.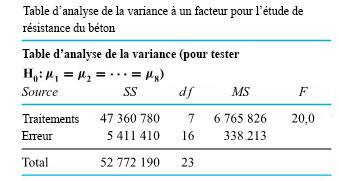
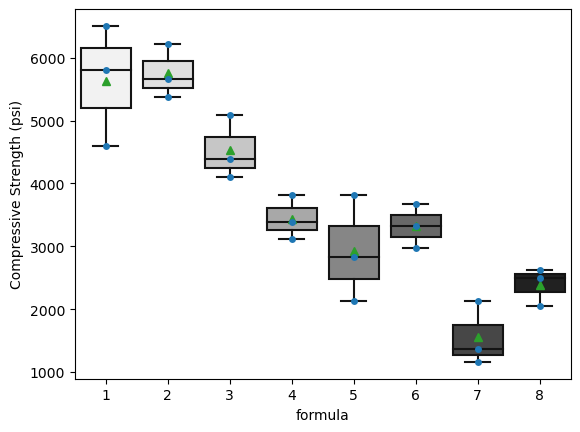
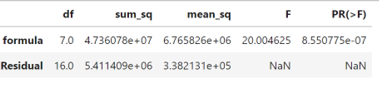
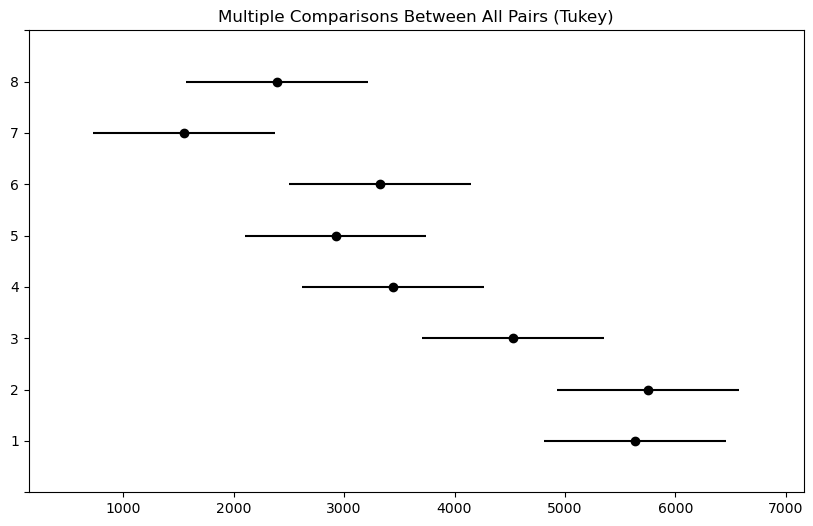

 , d’alcool polyvinylique et d’eau a été préparé, séché pendant une nuit, broyé et tamisé pour obtenir des grains d’une taille de 100 mesh. Ceux-ci ont été pressés dans des cylindres à des pressions allant de 2 000 psi à 10 000 psi, puis la densité des cylindres a été calculée. Les données obtenues sont présentées dans le tableau 7.1.1.1, et un nuage de points simple de ces données est présenté dans la figure 7.1.1.1.
, d’alcool polyvinylique et d’eau a été préparé, séché pendant une nuit, broyé et tamisé pour obtenir des grains d’une taille de 100 mesh. Ceux-ci ont été pressés dans des cylindres à des pressions allant de 2 000 psi à 10 000 psi, puis la densité des cylindres a été calculée. Les données obtenues sont présentées dans le tableau 7.1.1.1, et un nuage de points simple de ces données est présenté dans la figure 7.1.1.1.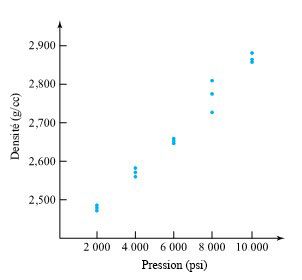

^2")
 sont les réponses observées et
sont les réponses observées et  sont les réponses correspondantes prédites (ou ajustées) par l’équation.
sont les réponses correspondantes prédites (ou ajustées) par l’équation.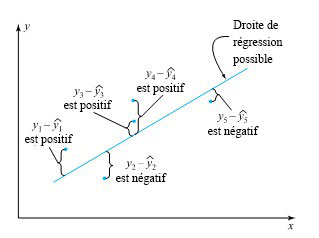

") , et l’ordonnée à l’origine
, et l’ordonnée à l’origine ") est la suivante :
est la suivante : = \sum_{i=1}^n\left(y_i - \left(\beta_0 + \beta_1 x_i\right)\right)^2")
") est un exercice de calcul différentiel. On met les dérivées partielles de
est un exercice de calcul différentiel. On met les dérivées partielles de  par rapport à
par rapport à  et à
et à  égales à zéro, puis on résout le système de deux équations pour obtenir
égales à zéro, puis on résout le système de deux équations pour obtenir  \beta_1 = \sum_{i=1}^n y_i")
 \beta_0 + \left(\sum_{i=1}^n x_i^2\right) \beta_1 = \sum_{i=1}^n x_i y_i")
 et
et \left(y_i - \bar{y}\right)}{\sum\left(x_i - \bar{x}\right)^2}")

 et
et  .
.^2 = & (2 000 - 6 000)^2 + (2 000 - 6 000)^2 + \cdots \\ \sum y_i = & 2,486 + 2,479 + \cdots + 2,858 = 40,005 \\ \text { donc } \bar{y} = & \frac{40,005}{15 } = 2,667 \\ \sum\left(y_i - \bar{y}\right)^2 = & (2,486 - 2,667)^2 + (2,479 - 2,667)^2 + \cdots+ \\ & (2,858 - 2,667)^2 = 0,289366 \\ \sum\left(x_i - \bar{x}\right)\left(y_i - \bar{y}\right) = & (2 000 - 6 000)(2,486 - 2,667) + \cdots+ \\ & (10 000 - 6 000)(2,858 - 2,667) = 5 840 \end{aligned}")
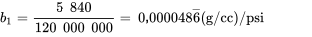 }) / \mathrm{psi}
}) / \mathrm{psi}(6 000) = 2,375 \mathrm{~g} / \mathrm{cm3}")

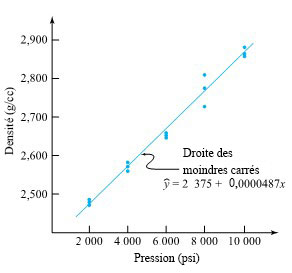
 = 2,5693 \mathrm{~g} / \mathrm{cm3}")
 = 2,5697 \mathrm{~g} / \mathrm{cm3}")
 = 2,6183 \mathrm{~g} / \mathrm{cm3}")
") est
est\left(y_i-\bar{y}\right)}{\sqrt{\sum\left(x_i-\bar{x}\right)^2 \cdot \sum\left(y_i-\bar{y}\right)^2}}")
^2 / \sum\left(y_i-\bar{y}\right)^2\right)^{1 / 2}") , ce qui indique que
, ce qui indique que  ont le même signe. Ainsi, une corrélation d’échantillon de -1 signifie que y diminue de façon linéaire lorsque x augmente, tandis qu’une corrélation d’échantillon de +1 signifie que y augmente de façon linéaire lorsque x augmente.
ont le même signe. Ainsi, une corrélation d’échantillon de -1 signifie que y diminue de façon linéaire lorsque x augmente, tandis qu’une corrélation d’échantillon de +1 signifie que y augmente de façon linéaire lorsque x augmente.(0,289366)}}=0,9911")
 , le coefficient de détermination vaut :
, le coefficient de détermination vaut :^2-\sum\left(y_i-\hat{y}_i\right)^2}{\sum\left(y_i-\bar{y}\right)^2}")

^2 \geq \sum\left(y_i-\hat{y}_i\right)^2") . De plus,
. De plus, ^2") est une mesure de la variabilité brute de y, tandis que
est une mesure de la variabilité brute de y, tandis que ^2") est une mesure de la variation de y restante après la régression de l’équation. La différence non négative
est une mesure de la variation de y restante après la régression de l’équation. La différence non négative ^2-\sum\left(y_i-\hat{y}_i\right)^2") est donc une mesure de la variabilité de y prise en compte dans le processus de régression.
est donc une mesure de la variabilité de y prise en compte dans le processus de régression.  pour tous les n = 15 points de données de l’ensemble de données d’origine. Ces valeurs sont indiquées dans le tableau 7.1.2.1.
pour tous les n = 15 points de données de l’ensemble de données d’origine. Ces valeurs sont indiquées dans le tableau 7.1.2.1.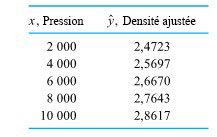
^2= & (2,486-2,4723)^2+(2,479-2,4723)^2+(2,472-2,4723)^2 \\ & +(2,558-2,5697)^2+\cdots+(2,879-2,8617)^2 \\ & +(2,858-2,8617)^2 \\ = & 0,005153 \end{aligned}")
^2=0,289366") , l’équation 7.1.2.2 donne :
, l’équation 7.1.2.2 donne :
 et les valeurs ajustées
et les valeurs ajustées  . (Dans la régression linéaire –le cas qui nous intéresse en ce moment –, les valeurs
. (Dans la régression linéaire –le cas qui nous intéresse en ce moment –, les valeurs  ,
, 
^2=0,9822=R^2")

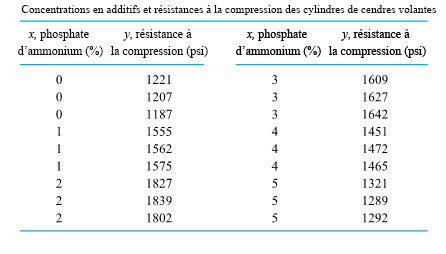

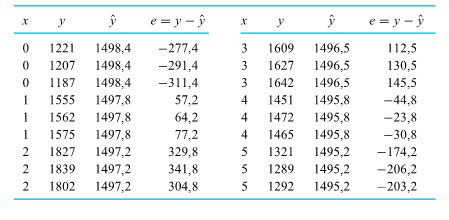
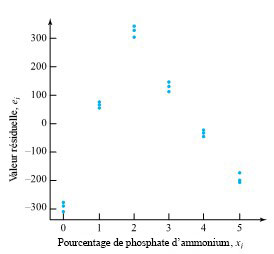
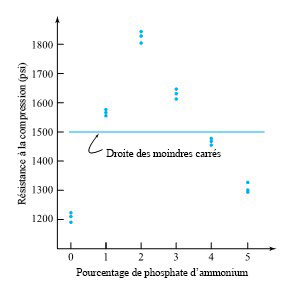
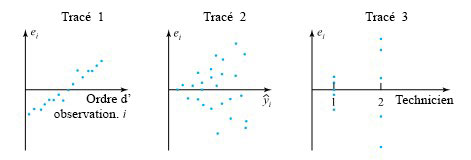
 ont été traités comme un échantillon de 15 nombres et ont été tracés de façon normale (en utilisant les méthodes que nous avons présentées précédemment) pour donner la figure 7.1.3.4.
ont été traités comme un échantillon de 15 nombres et ont été tracés de façon normale (en utilisant les méthodes que nous avons présentées précédemment) pour donner la figure 7.1.3.4.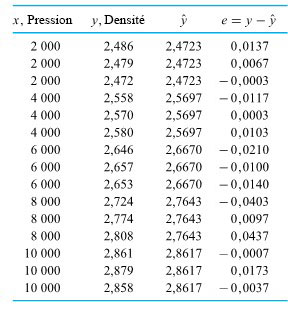
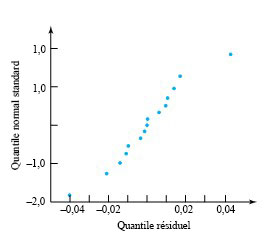
 et
et 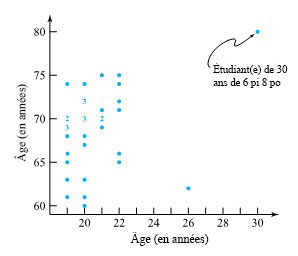
") , ainsi que l’inférence pour la réponse moyenne à une valeur x donnée. Nous discuterons ensuite des intervalles de prévision et de tolérance pour les réponses à une valeur donnée de x et présenterons des concepts liés à ANOVA pour la situation actuelle. Enfin, nous montrerons comment les logiciels statistiques permettent d’exécuter rapidement les calculs présentés dans cette partie.
, ainsi que l’inférence pour la réponse moyenne à une valeur x donnée. Nous discuterons ensuite des intervalles de prévision et de tolérance pour les réponses à une valeur donnée de x et présenterons des concepts liés à ANOVA pour la situation actuelle. Enfin, nous montrerons comment les logiciels statistiques permettent d’exécuter rapidement les calculs présentés dans cette partie.
 étaient considérées comme r paramètres non limités. Dans le cas d’une inférence basée sur les paires de données
étaient considérées comme r paramètres non limités. Dans le cas d’une inférence basée sur les paires de données ,\left(x_2, y_2\right), \ldots")
") dont le nuage de points est approximativement linéaire, il faut à nouveau imposer une restriction au modèle à un facteur 7.2.1.1. En mots, les hypothèses du modèle seront qu’il y a des distributions normales sous-jacentes pour la réponse y avec une variance commune
dont le nuage de points est approximativement linéaire, il faut à nouveau imposer une restriction au modèle à un facteur 7.2.1.1. En mots, les hypothèses du modèle seront qu’il y a des distributions normales sous-jacentes pour la réponse y avec une variance commune  , mais que les moyennes
, mais que les moyennes  varient de façon linéaire en fonction de
varient de façon linéaire en fonction de  :
:
 . La figure 7.2.1.1 est une représentation graphique du modèle « distribution normale, variance constante, moyenne linéaire (en x) ».
. La figure 7.2.1.1 est une représentation graphique du modèle « distribution normale, variance constante, moyenne linéaire (en x) ».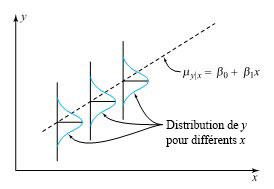


 , de l’anglais mean squared error et line fitting).
, de l’anglais mean squared error et line fitting).^2=\frac{1 }{n-2} \sum e^2")
 ).
). degrés de liberté et à l’erreur type du modèle de régression d’une droite (
degrés de liberté et à l’erreur type du modèle de régression d’une droite ( , une estimation de l’écart-type de la variable de réponse (
, une estimation de l’écart-type de la variable de réponse ( ).
). )
)
 est une estimation de la variation de base
est une estimation de la variation de base  (l’écart-type de l’échantillon groupé) est donc une autre façon de déterminer si le modèle 7.2.1.2 est approprié. Un
(l’écart-type de l’échantillon groupé) est donc une autre façon de déterminer si le modèle 7.2.1.2 est approprié. Un ^2=0,005153")
=0,000396(\mathrm{~g} / \mathrm{cc})^2")

 . Le tableau 7.2.1.2 donne les valeurs de
. Le tableau 7.2.1.2 donne les valeurs de  pour les cinq échantillons.
pour les cinq échantillons.(0,0070)^2+(3-1)(0,0110)^2+\cdots+(3-1)(0,0114)^2}{(3-1)+(3-1)+\cdots+(3-1)}")
^2")

 et
et 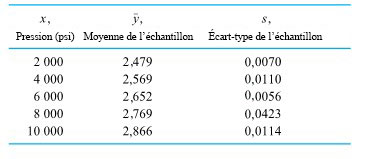
=\sigma^2\left(1-\frac{1 }{n}-\frac{(x-\bar{x})^2}{\sum(x-\bar{x})^2}\right)")
^2}{\sum(x-\bar{x})^2}}}")
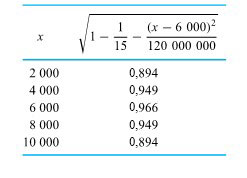
 multiplié par la valeur correspondante de la deuxième colonne du tableau 7.2.1.3 pour les mettre sur un pied d’égalité. Le tableau 7.2.1.4 donne les résidus bruts
multiplié par la valeur correspondante de la deuxième colonne du tableau 7.2.1.3 pour les mettre sur un pied d’égalité. Le tableau 7.2.1.4 donne les résidus bruts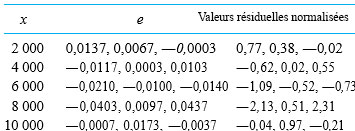
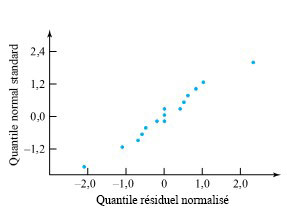
=\beta_1")
}=\frac{\sigma^2}{\sum(x-\bar{x})^2}")
^2}}}")
^2}}}")
 . Les arguments standard de la partie 5 appliqués à l’expression 7.2.2.2 montrent alors que
. Les arguments standard de la partie 5 appliqués à l’expression 7.2.2.2 montrent alors que
^2}}}")
 . Plus important encore, dans le cadre du modèle de régression
. Plus important encore, dans le cadre du modèle de régression^2}}")
 et
et  dans la distribution
dans la distribution  / \mathrm{psi}")
 dans l’équation 7.2.2.5. On peut donc utiliser les bornes
dans l’équation 7.2.2.5. On peut donc utiliser les bornes

 / \mathrm{psi} \text { et } 0,0000526(\mathrm{~g} / \mathrm{cc}) / \mathrm{psi}")
 ont des réponses moyennes qui diffèrent de
ont des réponses moyennes qui diffèrent de  . Pour obtenir un intervalle de confidence pour la différence des réponses moyennes, il suffit alors de multiplier les bornes de l’intervalle de confidence pour
. Pour obtenir un intervalle de confidence pour la différence des réponses moyennes, il suffit alors de multiplier les bornes de l’intervalle de confidence pour  \mathrm{g} / \mathrm{cc} \text { et } 2 000(0,0000526) \mathrm{g} / \mathrm{cc}")

^2") est élevée (c’est-à-dire plus les valeurs
est élevée (c’est-à-dire plus les valeurs  observations à utiliser et que l’on peut choisir des valeurs de
observations à utiliser et que l’on peut choisir des valeurs de ![[a,b]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/ea5dfda1db89d7e61cb60979bb300cc6.png "[a,b]") , en prendre
, en prendre  à
à  et
et  donne la meilleure précision possible pour estimer la pente
donne la meilleure précision possible pour estimer la pente 

=\mu_{y \mid x}=\beta_0+\beta_1 x")
}=\sigma^2\left(\frac{ 1}{n}+\frac{(x-\bar{x})^2}{\sum(x-\bar{x})^2}\right)")
 de la somme dans
de la somme dans ^2") du numérateur de l’expression 7.2.3.3, le
du numérateur de l’expression 7.2.3.3, le ^2}{\sum(x-\bar{x})^2}}}")
^2}{\sum(x-\bar{x})^2}}}")

^2}{\sum(x-\bar{x})^2}}}")
^2}{\sum(x-\bar{x})^2}}")
") . Un intervalle de confiance unilatéral s’obtient de la manière habituelle, en utilisant une seule borne dans l’équation 7.2.3.7.
. Un intervalle de confiance unilatéral s’obtient de la manière habituelle, en utilisant une seule borne dans l’équation 7.2.3.7. \sqrt{\frac{1 }{ 15}+\frac{(4 000-6 000)^2}{120 000 000}}=0,0136 \mathrm{~g} / \mathrm{cc}")

 \sqrt{\frac{ 1}{ 15}+\frac{(5 000-6 000)^2}{120 000 000}}=0,0118 \mathrm{~g} / \mathrm{cc}")

 = 6 000 psi.
= 6 000 psi.  \pm \sqrt{2 f} s_{\mathrm{LF}} \sqrt{\frac{ 1}{n}+\frac{(x-\bar{x})^2}{\sum(x-\bar{x})^2}}")
 attribuée à l’intervalle [0,
attribuée à l’intervalle [0,  ] (avec
] (avec 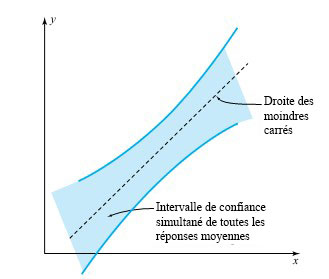

 et
et  degrés de liberté, il convient d’utiliser des limites simultanées de la forme
degrés de liberté, il convient d’utiliser des limites simultanées de la forme} s_{\mathrm{LF}} \sqrt{\frac{ 1}{ 15}+\frac{(x-6 000)^2}{120 000 000}}")



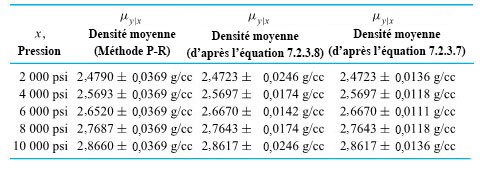
 est une observation supplémentaire, provenant de la distribution des réponses correspondant à un x donné, et que
est une observation supplémentaire, provenant de la distribution des réponses correspondant à un x donné, et que ^2}{\sum(x-\bar{x})^2}}}")
^2}{\sum(x-\bar{x})^2}}")
")
")
 soit choisi de manière appropriée (en fonction des données, de p, de x et du niveau de confiance souhaité).
soit choisi de manière appropriée (en fonction des données, de p, de x et du niveau de confiance souhaité).}}") sur
sur  pour la régression linéaire simple
pour la régression linéaire simple^2}{\sum(x-\bar{x})^2}}")
 , le
, le +A Q_z(\gamma) \sqrt{1+\frac{ 1}{2(n-2)}\left(\frac{Q_z^2(p)}{A^2}-Q_z^2(\gamma)\right)}}{1-\frac{Q_z^2(\gamma)}{2(n-2)}}")
 \sqrt{1+\frac{ 1}{ 15}+\frac{(4 000-6 000)^2}{120 000 000}}=2,5796-0,0282")
^2}{120 000 000}}=0,3162")
(1,645) \sqrt{1+\frac{ 1}{2(15-2)}\left(\frac{(1,282)^2}{(0,3162)^2}-(1,645)^2\right)}}{1-\frac{(1,645)^2}{2(15-2)}}=2,149")

^2")



}")
 de référence, où des valeurs élevées observées de la statistique de test constituent une preuve contre
de référence, où des valeurs élevées observées de la statistique de test constituent une preuve contre  .
. , qui ne dépend pas de x. (En fait, une meilleure interprétation d’un test de l’hypothèse 7.2.5.2 est qu’il s’agit de voir si un terme linéaire en x augmente de manière significative la capacité à modéliser la réponse y après avoir tenu compte d’une réponse moyenne globale.)
, qui ne dépend pas de x. (En fait, une meilleure interprétation d’un test de l’hypothèse 7.2.5.2 est qu’il s’agit de voir si un terme linéaire en x augmente de manière significative la capacité à modéliser la réponse y après avoir tenu compte d’une réponse moyenne globale.)
^2=0,289366")
^2=0,005153")

 est
est 717\right]717\right]
717\right]717\right]
 =
=  et
et 
") . Puis vient l’ajustement des surfaces à des données où la réponse
. Puis vient l’ajustement des surfaces à des données où la réponse  . Dans les deux cas, la discussion soulignera l’utilité de
. Dans les deux cas, la discussion soulignera l’utilité de  et des tracés des résidus et abordera la question du choix entre différentes équations de régression. Enfin, nous présenterons quelques mises en gardes pour l’application.
et des tracés des résidus et abordera la question du choix entre différentes équations de régression. Enfin, nous présenterons quelques mises en gardes pour l’application.

 variables
variables\right)^2 \\ & =\frac{g}{ 2}\left(\frac{x}{ 60}\right)^2+g\left(t_0-\frac{ 1}{ 60}\right)\left(\frac{x}{ 60}\right)+\frac{g}{2 }\left(t_0-\frac{1 }{ 60}\right)^2 \\ & =\frac{g}{ 7200} x^2+\frac{g}{ 60}\left(t_0-\frac{1 }{ 60}\right) x+\frac{g}{2 }\left(t_0-\frac{1 }{ 60}\right)^2 \end{aligned}")
") égales à 0, on obtient l’ensemble des équations normales pour ce problème des moindres carrés, généralisant ainsi la paire d’équations de la partie 7.1. Il existe
égales à 0, on obtient l’ensemble des équations normales pour ce problème des moindres carrés, généralisant ainsi la paire d’équations de la partie 7.1. Il existe  . Généralement, il existe un ensemble de solutions unique
. Généralement, il existe un ensemble de solutions unique  , qui minimise
, qui minimise  :
:
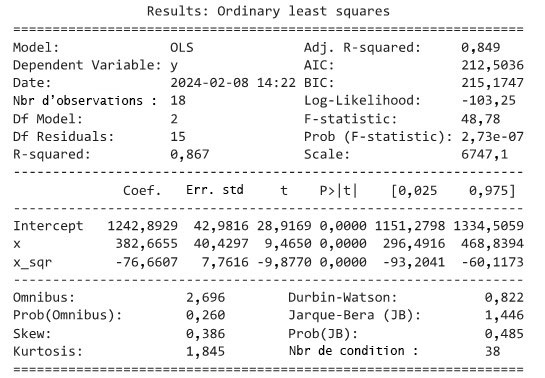


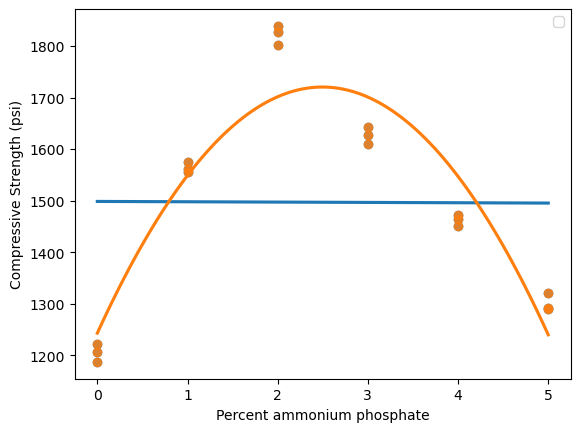
^2-\sum\left(y_{i}-\hat{y}_{i}\right)^2}{\sum\left(y_{i}-\bar{y}\right)^2}")

 donne
donne  . Donc
. Donc  de la variabilité totale concernant la résistance à la compression est prise en compte par l’équation de régression quadratique. Le coefficient de corrélation entre les valeurs de résistance observées
de la variabilité totale concernant la résistance à la compression est prise en compte par l’équation de régression quadratique. Le coefficient de corrélation entre les valeurs de résistance observées  et les valeurs de résistance ajustées
et les valeurs de résistance ajustées  est
est  .
. et
et  à utiliser pour la régression pour chaque valeur de
à utiliser pour la régression pour chaque valeur de 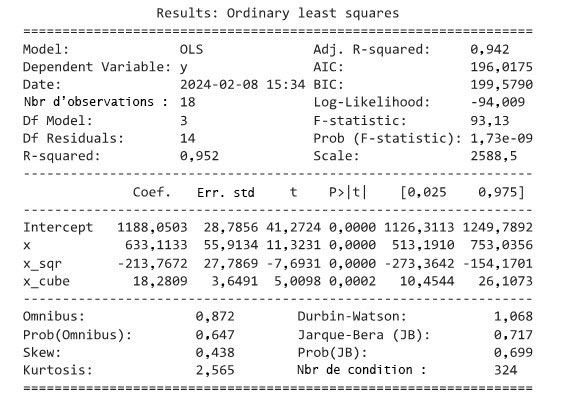

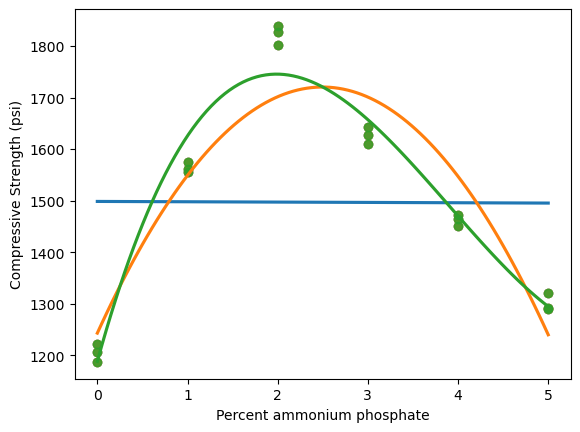
 . Malheureusement, il s’agit de la zone où la résistance à la compression est la plus importante – exactement la zone présentant le plus grand intérêt d’un point de vue pratique.
. Malheureusement, il s’agit de la zone où la résistance à la compression est la plus importante – exactement la zone présentant le plus grand intérêt d’un point de vue pratique. à partir d’un instant
à partir d’un instant  inconnu (inférieur à
inconnu (inférieur à 

 (en
(en  ) sera égale à
) sera égale à  . C’est par cette méthode que la valeur
. C’est par cette méthode que la valeur  , présentée à la section 1.4 a été obtenue.
, présentée à la section 1.4 a été obtenue.
 ) avec
) avec 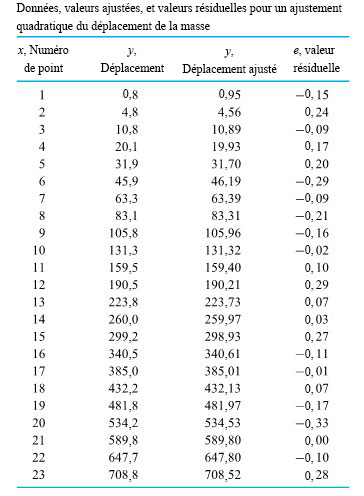
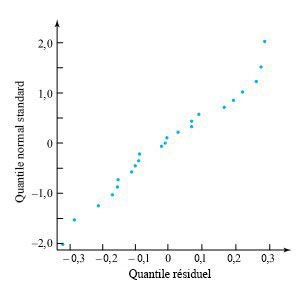
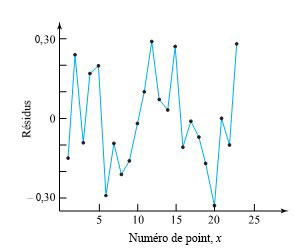
 .
. . Mais la région autour de
. Mais la région autour de 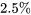 Il est tout à fait possible qu’une régression quadratique réalisée uniquement pour la plage de données
Il est tout à fait possible qu’une régression quadratique réalisée uniquement pour la plage de données  soit satisfaisante et utile pour une synthèse de l’étude de suivi.
soit satisfaisante et utile pour une synthèse de l’étude de suivi. de l’équation 8.1.1.2 peuvent être remplacés par n’importe quelle fonction (connue) de
de l’équation 8.1.1.2 peuvent être remplacés par n’importe quelle fonction (connue) de 
 \approx \ln (\alpha)+\beta \ln (x)")
") et la variable
et la variable ") , et dont les paramètres
, et dont les paramètres ") et
et  sont linéaires. Ainsi, à partir d’un ensemble de données
sont linéaires. Ainsi, à partir d’un ensemble de données  et
et  (et ainsi
(et ainsi \right)") et
et  .
.") qui, elle, correspond à une distribution standard.
qui, elle, correspond à une distribution standard.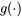
=\ln (y)") . Pour illustrer son utilisation dans le cas présent, des graphiques normaux des temps de détection et du logarithme des temps de détections sont présentés à la figure 8.1.2.2. Ces graphiques montrent qu’Elliot, Kibby et Meyer n’auraient pas pu raisonnablement appliquer les méthodes d’inférence standard aux temps de détection, mais qu’ils auraient pu les utiliser avec les logarithmes des temps de détection. Le second graphique normal est beaucoup plus linéaire que le premier.
. Pour illustrer son utilisation dans le cas présent, des graphiques normaux des temps de détection et du logarithme des temps de détections sont présentés à la figure 8.1.2.2. Ces graphiques montrent qu’Elliot, Kibby et Meyer n’auraient pas pu raisonnablement appliquer les méthodes d’inférence standard aux temps de détection, mais qu’ils auraient pu les utiliser avec les logarithmes des temps de détection. Le second graphique normal est beaucoup plus linéaire que le premier.
=(y-\gamma)^{\alpha}")
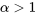 1″ title= »\alpha>1″ class= »latex mathjax »>, la transformation 8.1.2.1 a tendance à allonger la queue droite de la distribution de
1″ title= »\alpha>1″ class= »latex mathjax »>, la transformation 8.1.2.1 a tendance à allonger la queue droite de la distribution de =\ln (y-\gamma)")
 de la moyenne de la réponse, essayer la transformation 8.1.2.1 avec
de la moyenne de la réponse, essayer la transformation 8.1.2.1 avec  .
. et
et ") en fonction de
en fonction de ") , puis à voir s’il existe une linéarité approximative. Si tel est le cas, la consigne 1) est appropriée quand la pente est approximativement égale à 1, tandis qu’une pente de
, puis à voir s’il existe une linéarité approximative. Si tel est le cas, la consigne 1) est appropriée quand la pente est approximativement égale à 1, tandis qu’une pente de  indique qu’il faut utiliser la consigne 2) et suggère la valeur à utiliser.
indique qu’il faut utiliser la consigne 2) et suggère la valeur à utiliser.
") et une surface d’ajustement possible de la forme 8.1.3.1. Pour faire la régression d’un ensemble de
et une surface d’ajustement possible de la forme 8.1.3.1. Pour faire la régression d’un ensemble de ") avec une équation de la forme 8.1.3.1 en utilisant la méthode des moindres carrés, il faut minimiser la fonction de
avec une équation de la forme 8.1.3.1 en utilisant la méthode des moindres carrés, il faut minimiser la fonction de =\sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^2=\sum_{i=1}^{n}\left(y_{i}-\left(\beta_{0}+\beta_1 x_{1 i}+\cdots+\beta_{k} x_{k i}\right)\right)^2")
") .
.
 , correspond au taux de fonctionnement de l’installation. La variable de concentration en acide,
, correspond au taux de fonctionnement de l’installation. La variable de concentration en acide,  , correspond au pourcentage en circulation moins 50, multiplié par 10. La variable de réponse,
, correspond au pourcentage en circulation moins 50, multiplié par 10. La variable de réponse,  , et
, et 
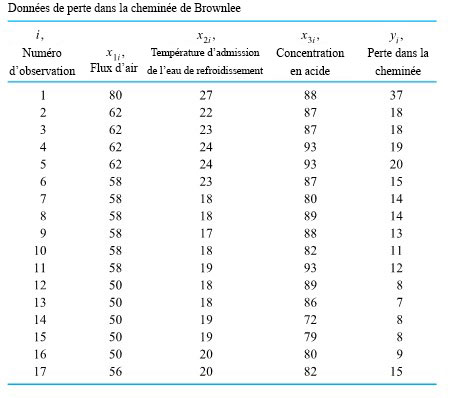

 . Les coefficients de cette équation peuvent être vus comme le taux de variation des pertes dans la cheminée en fonction des variables individuelles
. Les coefficients de cette équation peuvent être vus comme le taux de variation des pertes dans la cheminée en fonction des variables individuelles  représente l’augmentation des pertes dans la colonne
représente l’augmentation des pertes dans la colonne  et la concentration en acide
et la concentration en acide  soit positif indique que plus l’usine fonctionne à un rythme élevé, plus
soit positif indique que plus l’usine fonctionne à un rythme élevé, plus 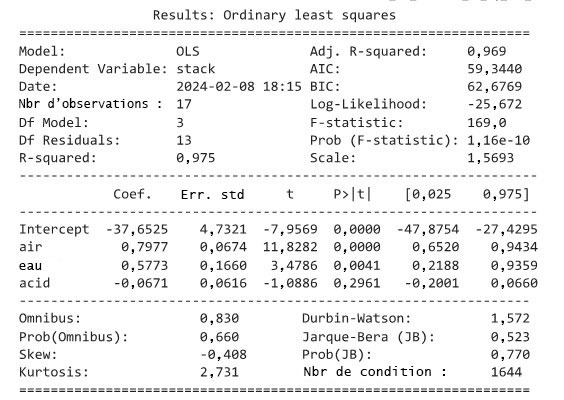

") et « voir » la qualité de la régression. Tout ce que nous pouvons faire à ce stade est d’offrir le conseil général de rechercher l’équation de régression la plus simple permettant un ajustement adéquat aux données, puis de fournir des exemples de la manière dont
et « voir » la qualité de la régression. Tout ce que nous pouvons faire à ce stade est d’offrir le conseil général de rechercher l’équation de régression la plus simple permettant un ajustement adéquat aux données, puis de fournir des exemples de la manière dont  de la variabilité totale en
de la variabilité totale en  de la variabilité totale des pertes dans la cheminée. Inclure
de la variabilité totale des pertes dans la cheminée. Inclure 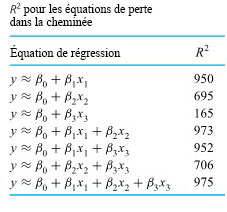
 \approx 1,5")
 pente de
pente de 
 , et
, et  de l’équation 8.1.3.3 diffèrent légèrement des valeurs de l’équation 8.1.3.2. En effet, l’équation 8.1.3.3 n’a pas été obtenue
de l’équation 8.1.3.3 diffèrent légèrement des valeurs de l’équation 8.1.3.2. En effet, l’équation 8.1.3.3 n’a pas été obtenue changent en fonction des variables
changent en fonction des variables  à l’équation de régression 8.1.3.3.
à l’équation de régression 8.1.3.3.

 et des résidus présentant une tendance encore moins marquée que ceux de l’équation de régression 8.1.3.3. Et on remarquera que le signe d’une courbure identifié sur le graphique des résidus en fonction de
et des résidus présentant une tendance encore moins marquée que ceux de l’équation de régression 8.1.3.3. Et on remarquera que le signe d’une courbure identifié sur le graphique des résidus en fonction de  width= »546″ height= »454″ /> Figure 8.1.3.2 Plots of residuals from a two-variable equation fit to the stack loss data ( yˆ =−42.00 − .78×1 + .57×2 )[/caption] . Equation (8.1.3.4) is somewhat more complicated than equation (8.1.3.3). But because it still really only involves two different input
width= »546″ height= »454″ /> Figure 8.1.3.2 Plots of residuals from a two-variable equation fit to the stack loss data ( yˆ =−42.00 − .78×1 + .57×2 )[/caption] . Equation (8.1.3.4) is somewhat more complicated than equation (8.1.3.3). But because it still really only involves two different input 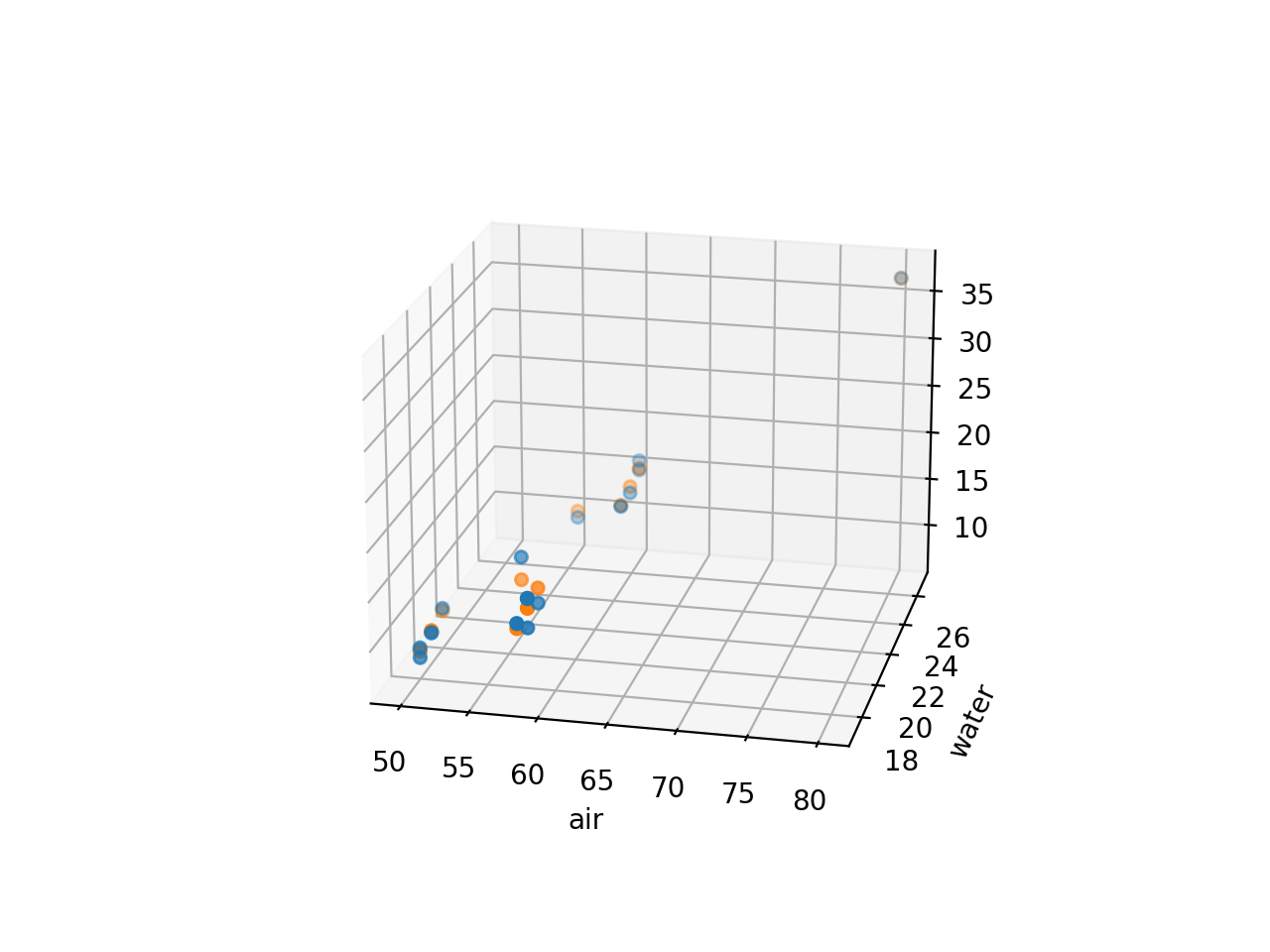
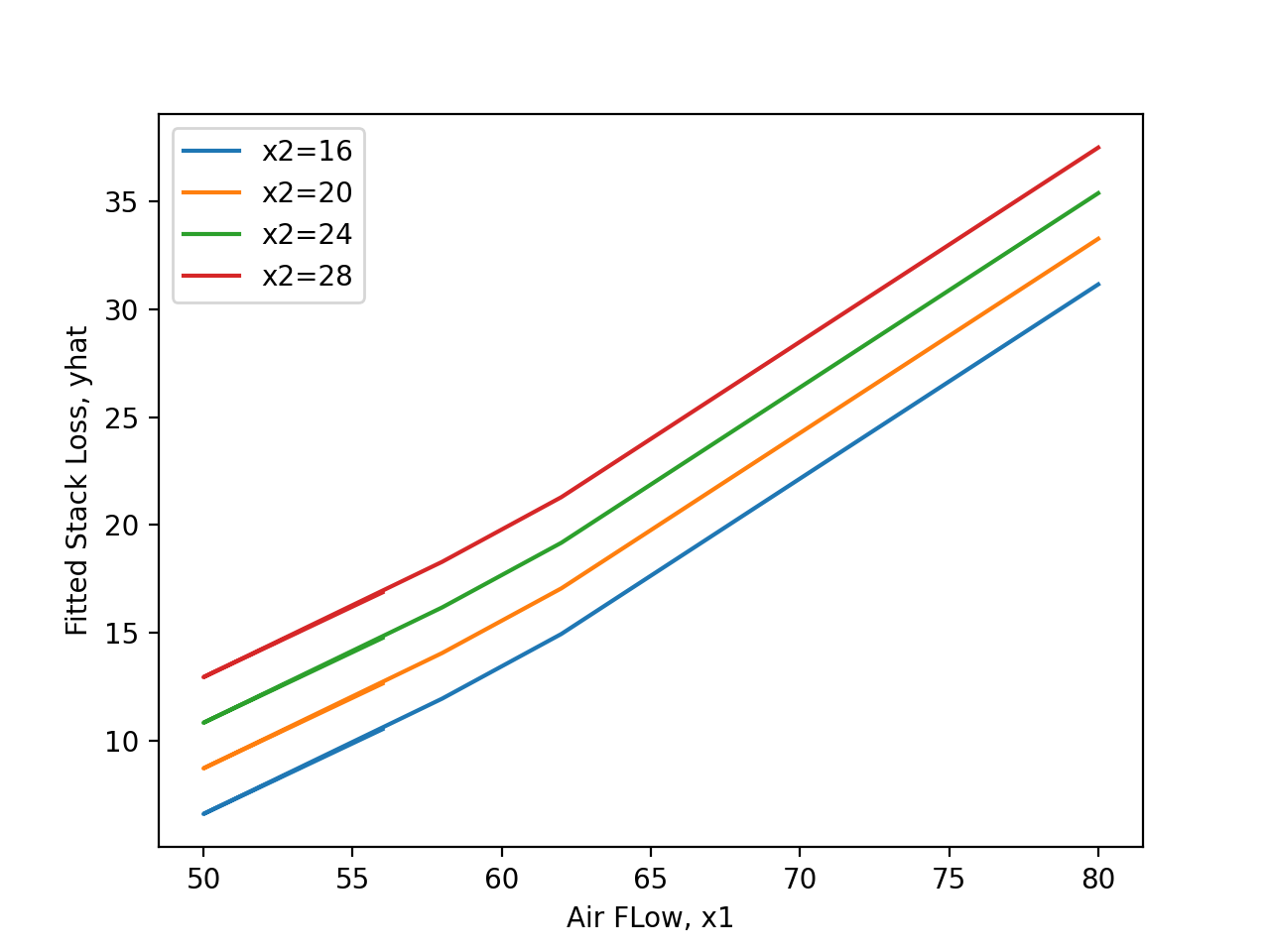
 le placement du plan canard en pouces au-dessus du plan de l’aile principale
le placement du plan canard en pouces au-dessus du plan de l’aile principale l’emplacement de l’empennage en pouces au-dessus du plan de l’aile principale
l’emplacement de l’empennage en pouces au-dessus du plan de l’aile principale


 , pour la fonction suivante :
, pour la fonction suivante :
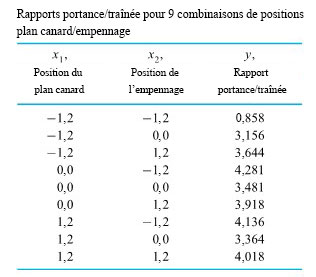
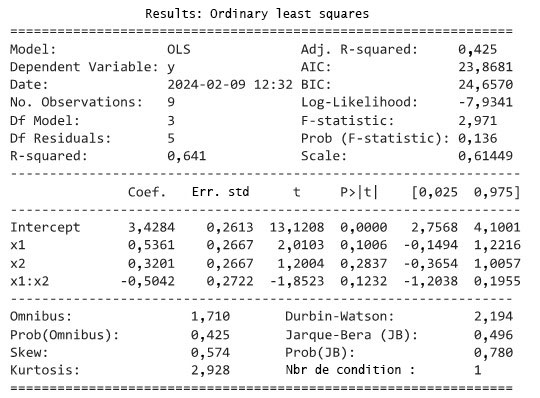


 ont été créés et
ont été créés et ") seraient parallèles pour différentes valeurs de
seraient parallèles pour différentes valeurs de 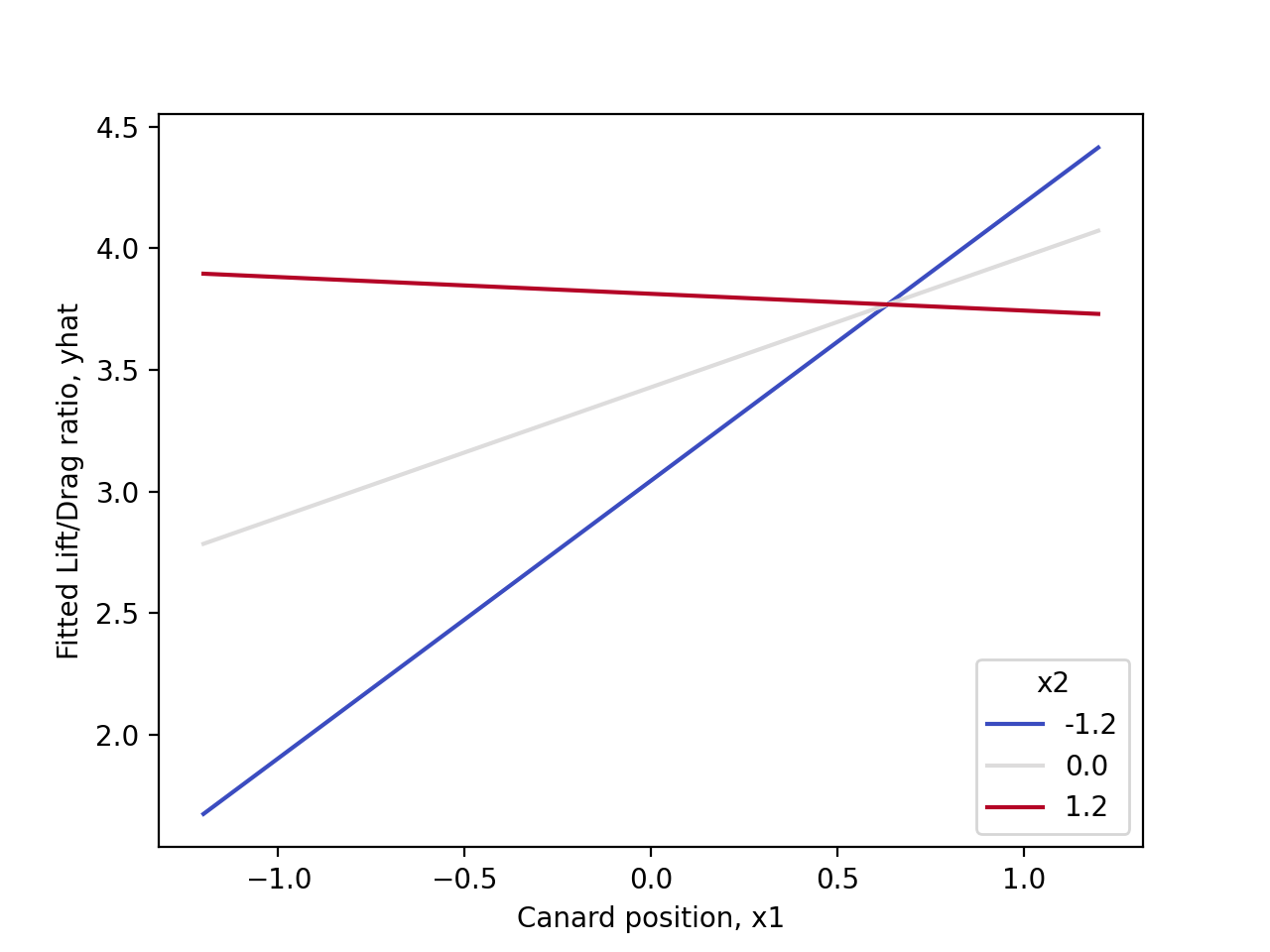

 et des résidus qui semblent généralement aléatoires. En traçant les courbes
et des résidus qui semblent généralement aléatoires. En traçant les courbes 
") donné est une extrapolation « substantielle ». Tout ce qu’on peut faire, c’est vérifier qu’il est proche d’un point
donné est une extrapolation « substantielle ». Tout ce qu’on peut faire, c’est vérifier qu’il est proche d’un point 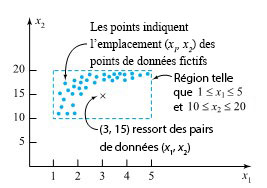
") pour les données du tableau 8.1.3.1. Elle montre que, selon la plupart des normes qualitatives, l’observation 1 du tableau 8.1.3.1 est inhabituelle ou aberrante.
pour les données du tableau 8.1.3.1. Elle montre que, selon la plupart des normes qualitatives, l’observation 1 du tableau 8.1.3.1 est inhabituelle ou aberrante.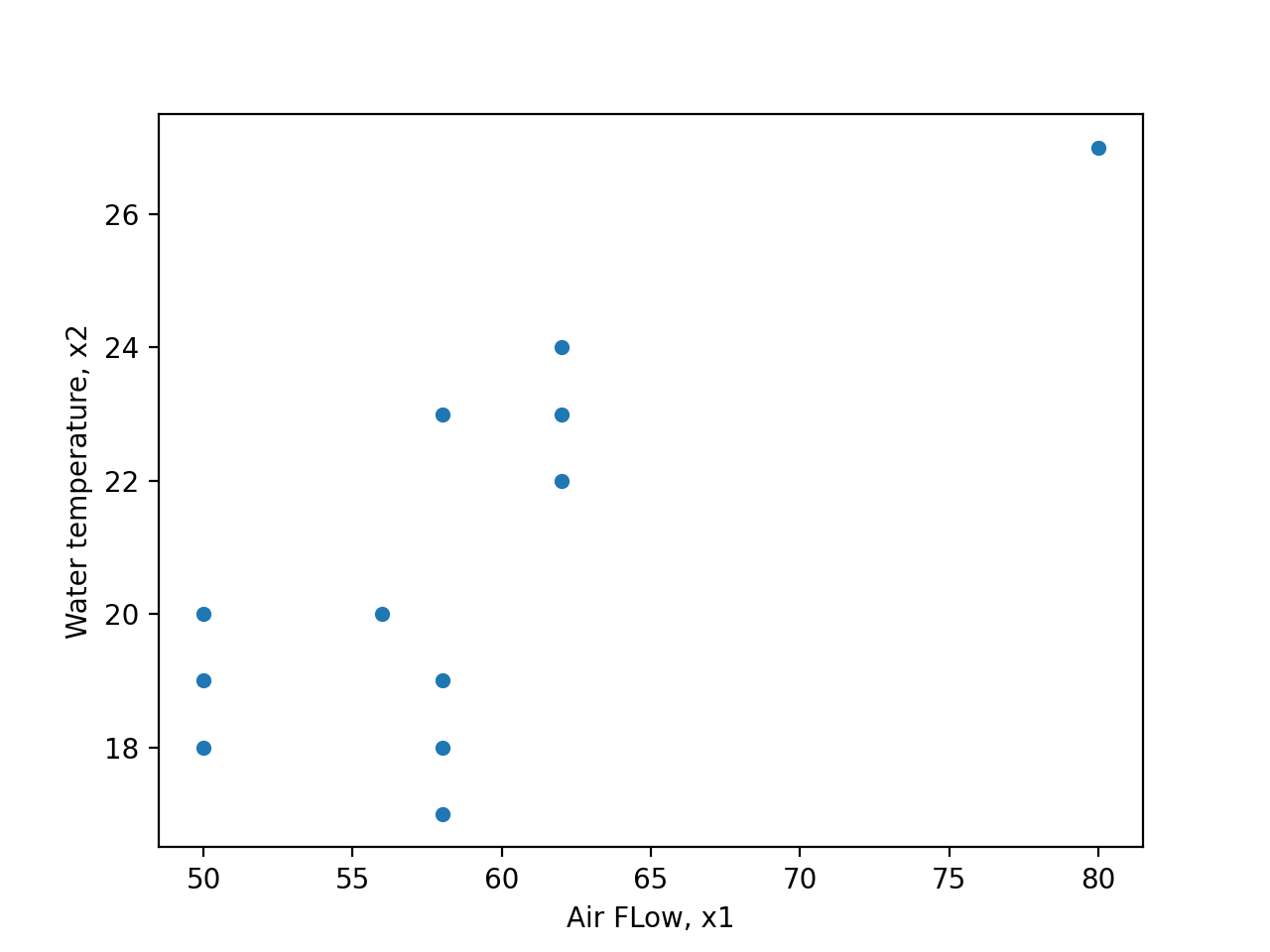

 . On pourrait envisager d’utiliser l’équation 8.1.6.1 pour prédire les pertes dans la cheminée et de limiter l’attention à
. On pourrait envisager d’utiliser l’équation 8.1.6.1 pour prédire les pertes dans la cheminée et de limiter l’attention à  à travers chacun de ces points. Mais dans la plupart des problèmes physiques, une telle courbe serait beaucoup moins efficace pour prédire les valeurs de
à travers chacun de ces points. Mais dans la plupart des problèmes physiques, une telle courbe serait beaucoup moins efficace pour prédire les valeurs de  pour différents groupes nominaux dans les données. Ce type de test est similaire à un test d’écart moyen pour les groupes identifiés par la variable muette. Les variables muettes permettent de comparer un groupe inclus (les 1) et un groupe omis (les 0). Il est donc important d’indiquer clairement quel groupe est omis et sert de « catégorie de comparaison ».
pour différents groupes nominaux dans les données. Ce type de test est similaire à un test d’écart moyen pour les groupes identifiés par la variable muette. Les variables muettes permettent de comparer un groupe inclus (les 1) et un groupe omis (les 0). Il est donc important d’indiquer clairement quel groupe est omis et sert de « catégorie de comparaison ». pour chaque catégorie, à l’exception du groupe de référence (qui est omis). Voici quelques exemples de variables catégoriques qui peuvent être représentées dans une régression multiple par des variables muettes :
pour chaque catégorie, à l’exception du groupe de référence (qui est omis). Voici quelques exemples de variables catégoriques qui peuvent être représentées dans une régression multiple par des variables muettes : , contrôle
, contrôle  )
)") pour le groupe « muet », ce qui est illustré dans la figure 8.2.1.1. Dans ce graphique, la valeur de
pour le groupe « muet », ce qui est illustré dans la figure 8.2.1.1. Dans ce graphique, la valeur de  (une variable continue) et de
(une variable continue) et de  (une variable muette). Lorsque
(une variable muette). Lorsque  , la valeur de
, la valeur de 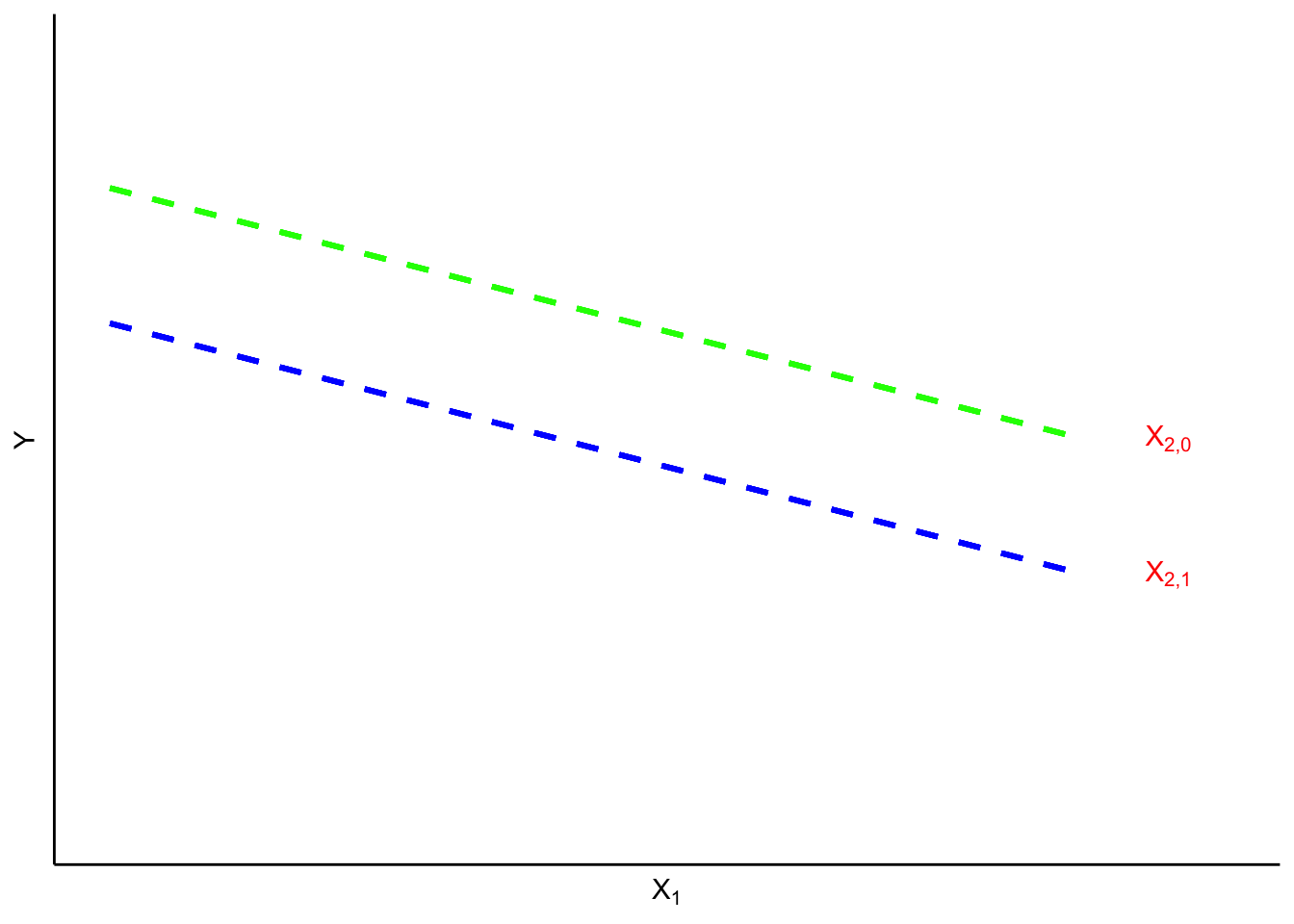
 dépend de la valeur d’un autre. Typiquement, les modèles MCO sont additifs, c’est-à-dire qu’on additionne les
dépend de la valeur d’un autre. Typiquement, les modèles MCO sont additifs, c’est-à-dire qu’on additionne les  pour prédire
pour prédire  .
. .
. femmes,
femmes,  hommes
hommes") pourrait être associée à l’idéologie
pourrait être associée à l’idéologie  fortement à gauche,
fortement à gauche,  fortement à droite) pour prédire le niveau de risque perçu des changements climatiques (
fortement à droite) pour prédire le niveau de risque perçu des changements climatiques ( aucun risque,
aucun risque,  risque extrême). Si l’interaction hypothétique était correcte, on observerait une tendance comme celle illustrée à la figure 8.2.1.2.
risque extrême). Si l’interaction hypothétique était correcte, on observerait une tendance comme celle illustrée à la figure 8.2.1.2.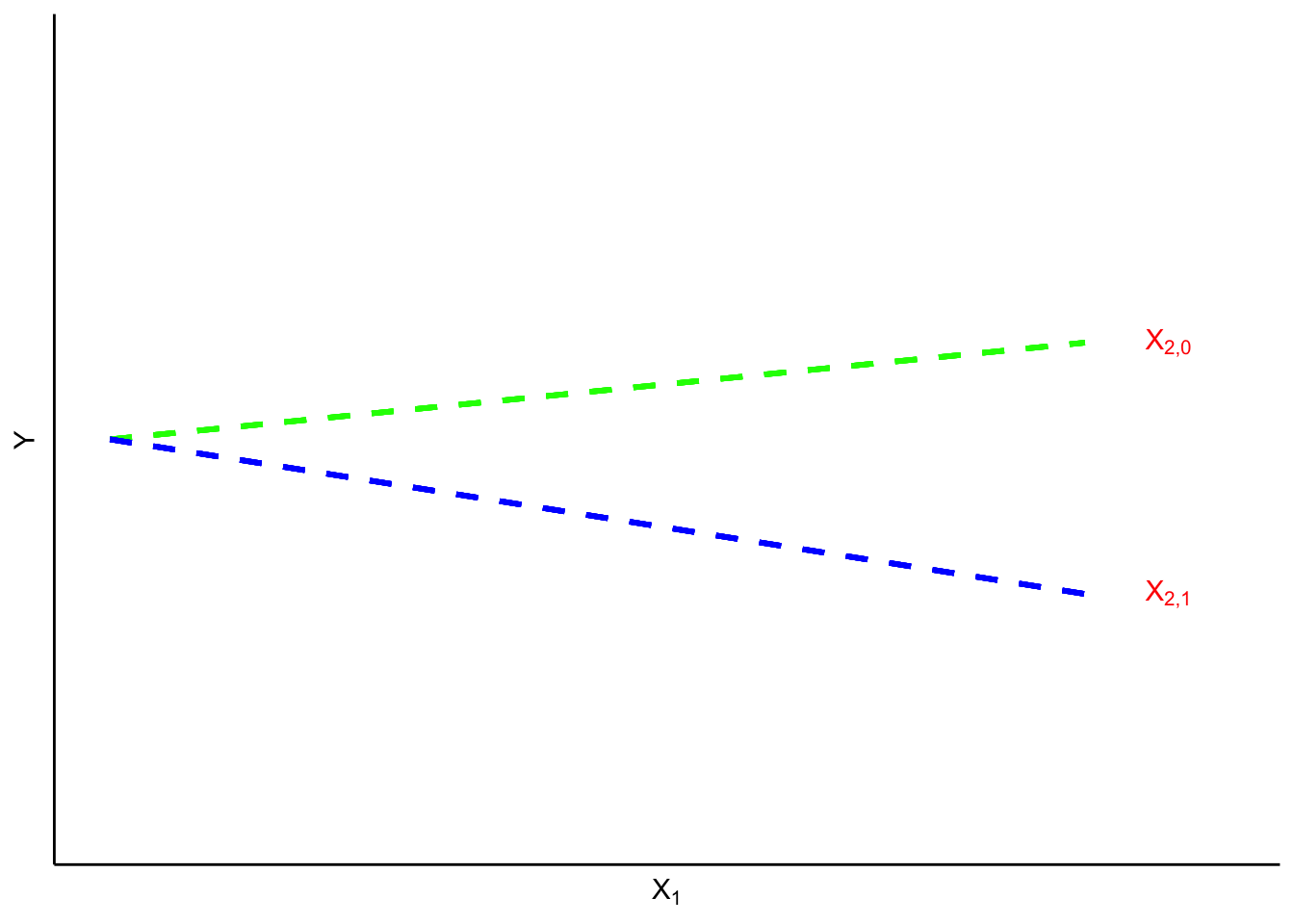
 . En utilisant la notation matricielle, la même équation peut être exprimée sous une forme plus compacte et (étonnamment!) plus intuitive :
. En utilisant la notation matricielle, la même équation peut être exprimée sous une forme plus compacte et (étonnamment!) plus intuitive :  .
. . Dans l’exemple suivant,
. Dans l’exemple suivant,  fait référence à la ligne de la matrice et
fait référence à la ligne de la matrice et ![A_{m, n} = \left[\begin{array}{cccc}a_{1,1} & a_{1,2} & \cdots & a_{1, n} \\ a_{2,1} & a_{2,2} & \cdots & a_{2, n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m, 1} & a_{m, 2} & \cdots & a_{m, n}\end{array}\right]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/3687c16872bfd24c0ad12d35fda788d4.png "A_{m, n}=\left[\begin{array}{cccc}a_{1,1} & a_{1,2} & \cdots & a_{1, n} \\ a_{2,1} & a_{2,2} & \cdots & a_{2, n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m, 1} & a_{m, 2} & \cdots & a_{m, n}\end{array}\right]")
![A = \left[\begin{array}{ccc}10 & 5 & 8 \\ -12 & 1 & 0\end{array}\right]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/97f9b7e52dcadce020e355199f5bc568.png "A = \left[\begin{array}{ccc}10 & 5 & 8 \\ -12 & 1 & 0\end{array}\right]")
 et
et  .
.![A = \left[\begin{array}{c}6 \\ -1 \\ 8 \\ 11\end{array}\right]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/d867c8d8d16e69976327c05841eefb79.png "A = \left[\begin{array}{c}6 \\ -1 \\ 8 \\ 11\end{array}\right]")
![A = \left[\begin{array}{llll}1 & 2 & 8 & 7\end{array}\right]](https://ecampusontario.pressbooks.pub/app/uploads/sites/4171/2024/03/3b9e4aa30734805efc2dd0f148386a02.png "A = \left[\begin{array}{llll}1 & 2 & 8 & 7\end{array}\right]")
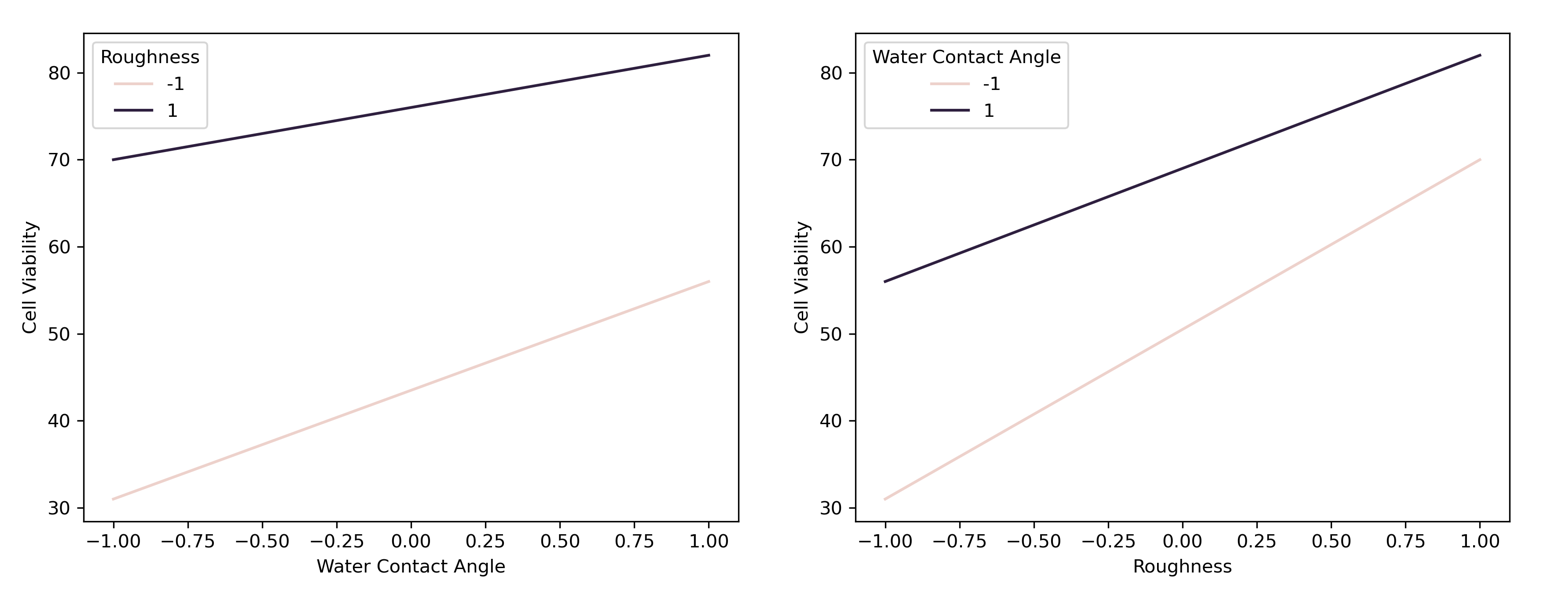
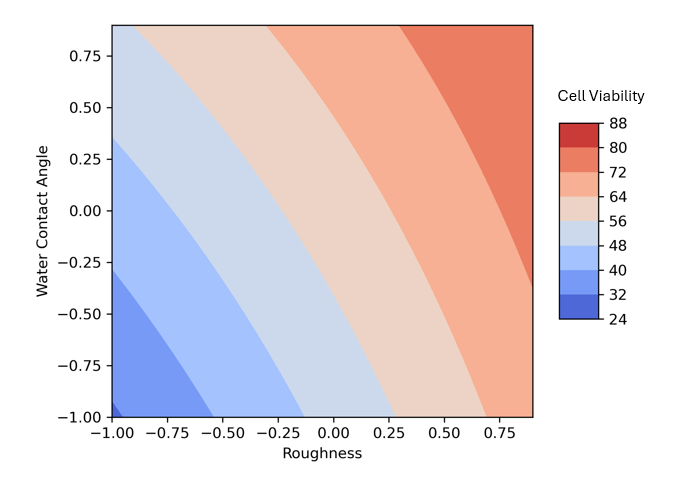

 = la rugosité de surface et
= la rugosité de surface et  = l’angle de contact avec l’eau) :
= l’angle de contact avec l’eau) :
} \\ 1 & {R+} &{W-} &{(R+W-)} \\ 1 & {R-} & {W+} &{(R-W+)} \\ 1 & {R+} & {W+} &{(R+W+)}\\\end{bmatrix}\begin{bmatrix} b_0 \\ b_R \\ b_W \\ b_{RW}\\\end{bmatrix} +\begin{bmatrix} e_0 \\ e_R \\ e_W \\ e_{RW}\\\end{bmatrix}")

}") n’a que des valeurs non nulles sur la diagonale. Par conséquent :
n’a que des valeurs non nulles sur la diagonale. Par conséquent :^-1(X^Ty)}")


^-1(X^Ty)}=\begin{bmatrix} (1/4) & 0 & 0 & 0 \\ 0 & (1/4) & 0 & 0 \\ 0 & 0 & (1/4) & 0 \\ 0 & 0 & 0 & (1/4)\\\end{bmatrix}\begin{bmatrix} 239 \\ 65 \\ 37 \\ -13 \\\end{bmatrix}=\begin{bmatrix} 59,75\\ 16,25 \\ 9,25 \\ -3,25 \\\end{bmatrix}")
 , peut être interprétée de la même manière que précédemment. Par exemple, une augmentation d’une unité de la rugosité correspond à une augmentation de 16,25 u.a. de la viabilité cellulaire. Cette méthode explique également pourquoi il avait fallu diviser par 2 une deuxième fois précédemment, puisque ce coefficient représente l’effet du passage de la rugosité de surface de 0 à 1, soit de 325 à 350 µm. Il en va de même pour l’angle de contact avec l’eau. Enfin, le terme d’interaction diminue la viabilité cellulaire de 3,25 unités si la rugosité de la surface et l’angle de contact avec l’eau sont au même niveau (tous deux élevés ou tous deux faibles).
, peut être interprétée de la même manière que précédemment. Par exemple, une augmentation d’une unité de la rugosité correspond à une augmentation de 16,25 u.a. de la viabilité cellulaire. Cette méthode explique également pourquoi il avait fallu diviser par 2 une deuxième fois précédemment, puisque ce coefficient représente l’effet du passage de la rugosité de surface de 0 à 1, soit de 325 à 350 µm. Il en va de même pour l’angle de contact avec l’eau. Enfin, le terme d’interaction diminue la viabilité cellulaire de 3,25 unités si la rugosité de la surface et l’angle de contact avec l’eau sont au même niveau (tous deux élevés ou tous deux faibles).
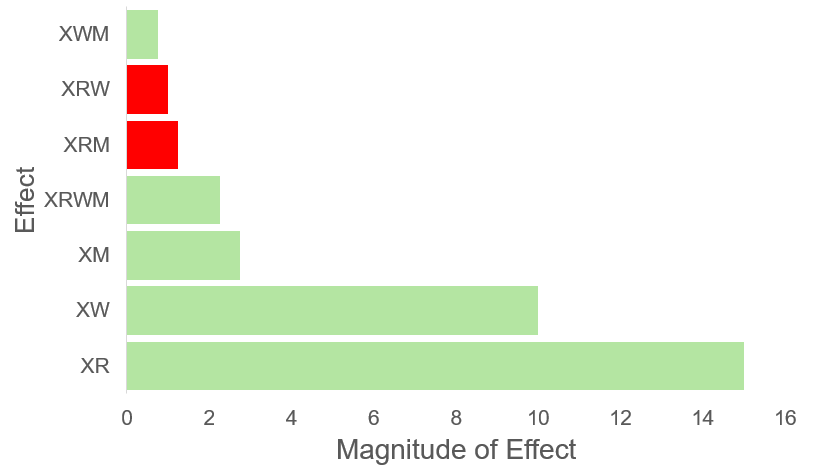
 = coefficient de matériau) :
= coefficient de matériau) :

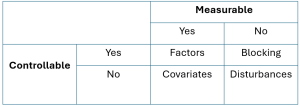
 = effet d’interaction de ABC + perturbation.
= effet d’interaction de ABC + perturbation. ) est désormais confondu avec un terme d’interaction.
) est désormais confondu avec un terme d’interaction.


 est confondu avec l’interaction de
est confondu avec l’interaction de  , puisque le coefficient du modèle est la somme de ces deux effets. On peut donc affirmer que
, puisque le coefficient du modèle est la somme de ces deux effets. On peut donc affirmer que  est un alias de
est un alias de  , que
, que  est un alias de
est un alias de  et que l’ordonnée à l’origine est un alias de l’interaction à trois facteurs
et que l’ordonnée à l’origine est un alias de l’interaction à trois facteurs 



 . Les facteurs
. Les facteurs  . C’est ce qu’on appelle la relation génératrice.
. C’est ce qu’on appelle la relation génératrice. est une colonne de uns.
est une colonne de uns.

 . Prenons la relation génératrice et multiplions les deux côtés par
. Prenons la relation génératrice et multiplions les deux côtés par ![\mathbf{D} \times \mathbf{D} = \mathbf{ABC} \times \mathbf{D]](https://atu0g9ctah.execute-api.ca-central-1.amazonaws.com/latest/latex?latex=%5Cmathbf%7BD%7D%20%5Ctimes%20%5Cmathbf%7BD%7D%20%3D%20%5Cmathbf%7BABC%7D%20%5Ctimes%20%5Cmathbf%7BD%5D&fg=000000&font=TeX&svg=1 "\mathbf{D} \times \mathbf{D} = \mathbf{ABC} \times \mathbf{D]") . Or,
. Or,  , d’où
, d’où  .
. par l’équation suivante :
par l’équation suivante :
 , ce qui indique que
, ce qui indique que 
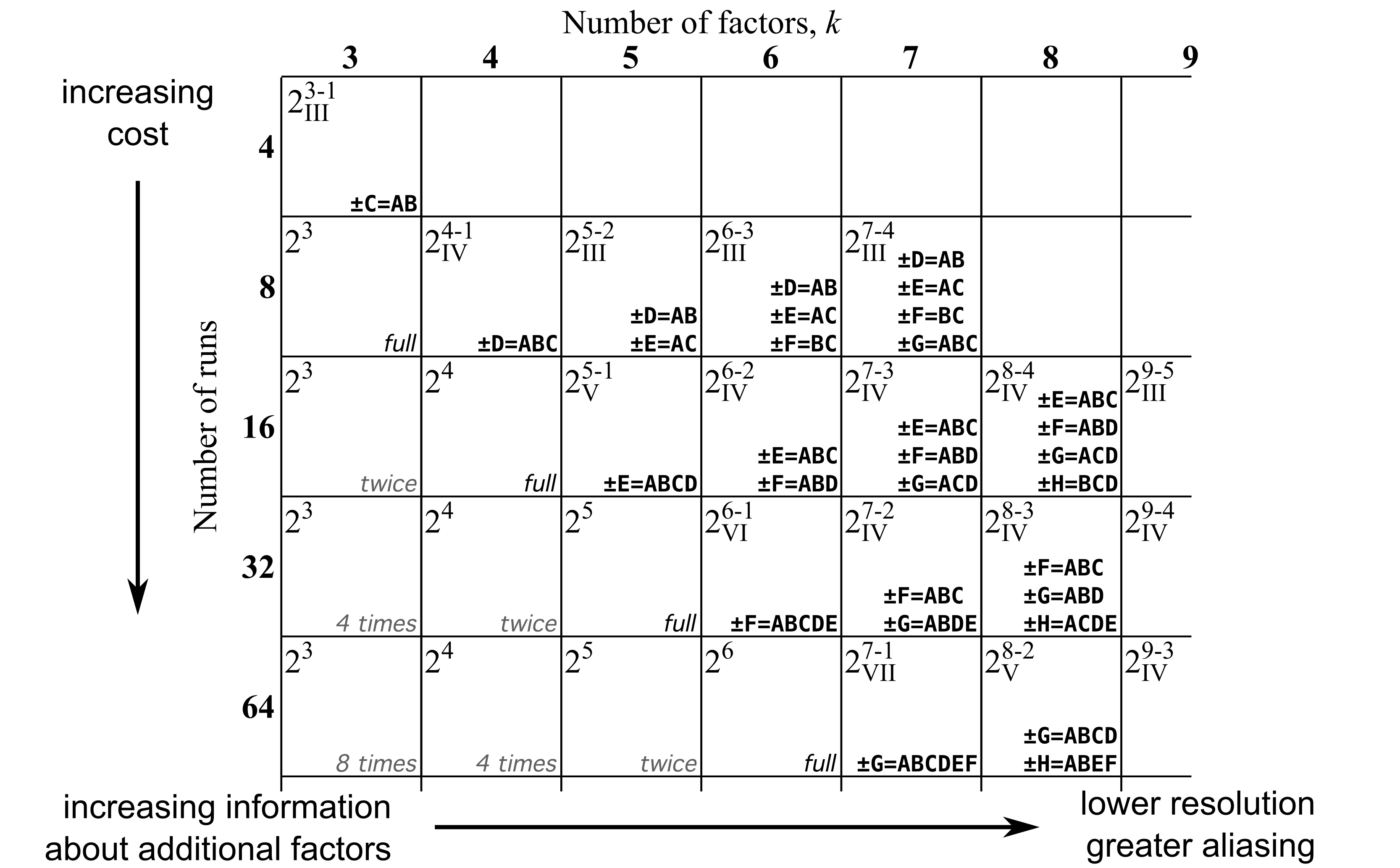
 . Ici, les chiffres romains
. Ici, les chiffres romains  indiquent le niveau de résolution du plan. Ce nombre est équivalent au nombre de facteurs présents dans la relation de définition. Puisque
indiquent le niveau de résolution du plan. Ce nombre est équivalent au nombre de facteurs présents dans la relation de définition. Puisque
MSR pour une seule variable
Examinons d’abord l’effet d’un seul facteur  sur la réponse,
sur la réponse,  . Cet exemple servira à illustrer le principe général du processus de surface de réponse.
. Cet exemple servira à illustrer le principe général du processus de surface de réponse.
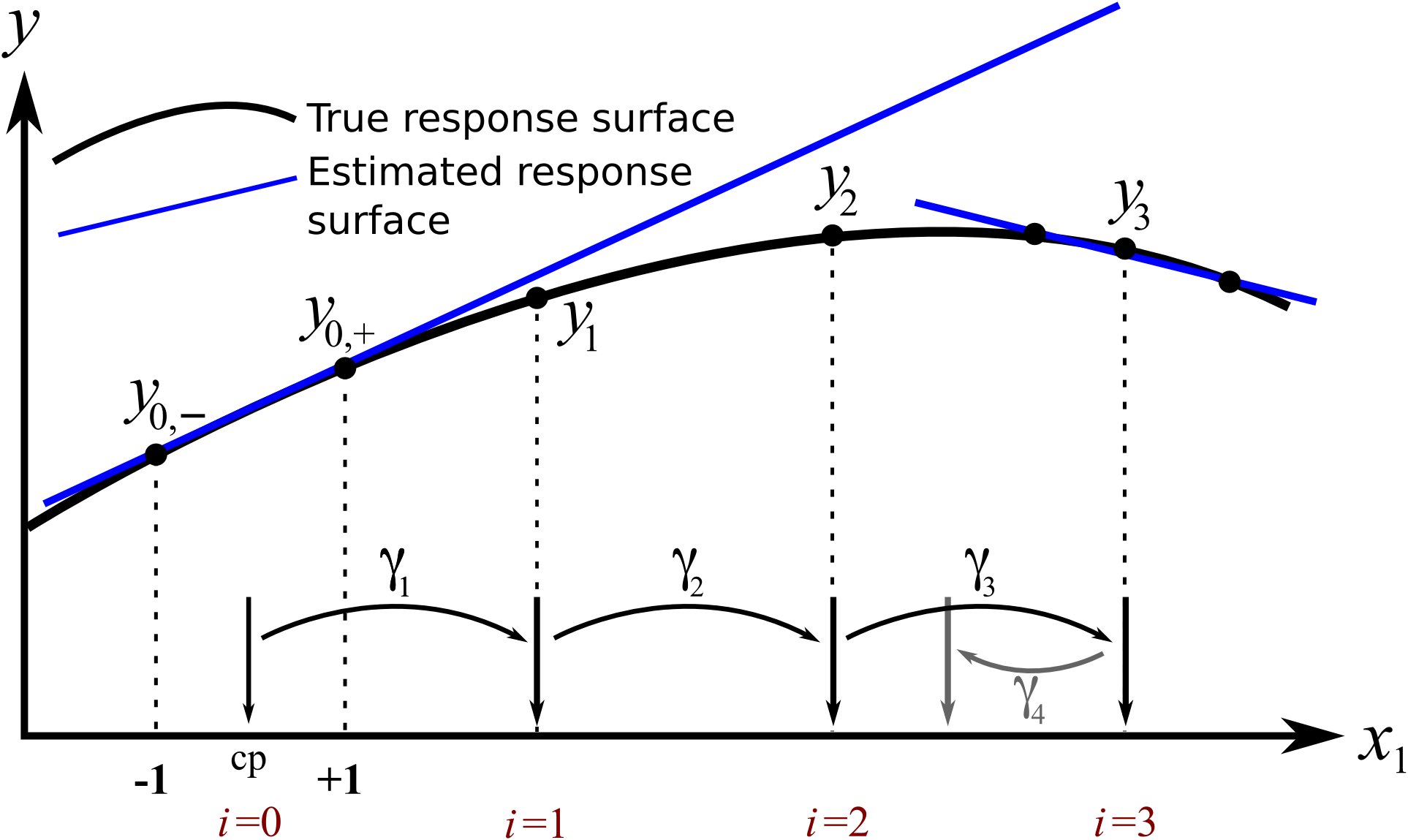
Le point  sert de point de référence initial (pc = point de centrage). Puis, on exécute une expérience à deux niveaux, au-dessous (à – 1) et au-dessus (à 1) de ce point de référence, et on obtient des valeurs de réponse correspondantes de
sert de point de référence initial (pc = point de centrage). Puis, on exécute une expérience à deux niveaux, au-dessous (à – 1) et au-dessus (à 1) de ce point de référence, et on obtient des valeurs de réponse correspondantes de  et
et  . À partir de là, on peut estimer la droite de régression et la suivre dans la direction croissante . Notez que l’inclinaison de la pente d’une droite tangente correspond à la trajectoire de pente maximale. On effectue un pas de
. À partir de là, on peut estimer la droite de régression et la suivre dans la direction croissante . Notez que l’inclinaison de la pente d’une droite tangente correspond à la trajectoire de pente maximale. On effectue un pas de  unités le long de , puis on mesure la réponse,
unités le long de , puis on mesure la réponse,  . Puisque la variable de la réponse a augmenté, on poursuit dans cette direction.
. Puisque la variable de la réponse a augmenté, on poursuit dans cette direction.
On effectue un nouveau pas, cette fois-ci de unités dans la direction où est croissant. On mesure la réponse,
unités dans la direction où est croissant. On mesure la réponse,  , qui est encore croissante. Ce résultat nous encourage à effectuer un nouveau pas de
, qui est encore croissante. Ce résultat nous encourage à effectuer un nouveau pas de  . Les pas
. Les pas  doivent être suffisamment grands pour causer une variation de la réponse lors d’un nombre raisonnable d’expériences, sans toutefois être si grands qu’ils nous feraient passer à côté d’un optimum.
doivent être suffisamment grands pour causer une variation de la réponse lors d’un nombre raisonnable d’expériences, sans toutefois être si grands qu’ils nous feraient passer à côté d’un optimum.
Le nouveau point,  , a environ la même valeur que , ce qui indique qu’on a atteint un plateau. À ce stade, on peut se lancer dans une démarche exploratoire et réajuster la tangente (qui est maintenant de pente inverse). On peut aussi utiliser les points de données accumulés pour faire une régression non linéaire. Dans les deux cas, on peut alors estimer un nouveau pas de progression de
, a environ la même valeur que , ce qui indique qu’on a atteint un plateau. À ce stade, on peut se lancer dans une démarche exploratoire et réajuster la tangente (qui est maintenant de pente inverse). On peut aussi utiliser les points de données accumulés pour faire une régression non linéaire. Dans les deux cas, on peut alors estimer un nouveau pas de progression de  pour se rapprocher de l’optimum.
pour se rapprocher de l’optimum.
Cette approche convient lorsque la réponse ne dépend que d’un seul facteur. Cependant, dans la plupart des systèmes, la réponse est influencée par plusieurs facteurs, ce qui nous oblige à adapter cette méthode pour trouver les optimums du système.
9.3.2. Optimisation d’un système à deux variables
Supposons qu’on cherche à optimiser un bioréacteur dont le rendement est affecté par deux facteurs, la température T et la concentration en substrat S. Or, le résultat qui nous intéresse dans ce contexte, c’est le profit total, qui prend en compte les coûts énergétiques, les coûts des matières premières et autres facteurs pertinents. La figure 9.3.2.1 illustre en gris clair des courbes (hypothétiques) de profit. En pratique, ces courbes sont souvent inconnues. Le système fonctionne actuellement dans les conditions suivantes (conditions de référence) :
- T = 325 K
- S = 0,75 g/L
- Profit = 407 $ par jour
On crée une analyse factorielle complète à partir de ces conditions en choisissant  K, et
K, et  g/L, sachant que ces pas sont suffisamment grands pour révéler une différence dans la valeur de la réponse (voir le tableau 9.3.2.1), sans toutefois être si grands qu’ils exploreraient un tout autre régime du bioréacteur.
g/L, sachant que ces pas sont suffisamment grands pour révéler une différence dans la valeur de la réponse (voir le tableau 9.3.2.1), sans toutefois être si grands qu’ils exploreraient un tout autre régime du bioréacteur.
| Expérience | T (réelle) | S (réelle) | T (codée) | S (codée) | Profit |
|---|---|---|---|---|---|
| Conditions de référence | 325 K | 0,75 g/L | 0 | 0 | 407 |
| 1 | 320 K | 0,50 g/L | – | – | 193 |
| 2 | 330 K | 0,50 g/L | + | – | 310 |
| 3 | 320 K | 1,0 g/L | – | + | 468 |
| 4 | 330 K | 1,0 g/L | + | + | 571 |
Il apparaît clairement qu’on peut maximiser les profits en opérant à des températures plus élevées et en utilisant de plus fortes concentrations de substrat. Néanmoins, la seule manière de mesurer ce taux d’augmentation est d’établir un modèle linéaire du système à partir des données factorielles :
où 
où 
et  .
.
Le modèle démontre que l’on peut s’attendre à une hausse de profit de 55 $ par jour pour une augmentation d’une unité de T. En unités réelles, il faudrait augmenter la température de  pour atteindre cet objectif. Ce facteur d’échelle provient du codage que nous avons utilisé :
pour atteindre cet objectif. Ce facteur d’échelle provient du codage que nous avons utilisé :
\Delta x_T &= \displaystyle \frac{\Delta x_{T,\text{réelle}}}{\Delta_T / 2}\end{split}\]
Au même titre, on peut augmenter \(S\) par  pour obtenir une hausse de profit de 134 $ par jour.
pour obtenir une hausse de profit de 134 $ par jour.
Le terme d’interaction est faible, ce qui suggère que la surface de réponse est plutôt linéaire dans cette région. La figure 9.3.2.1 illustre les contours du modèle (lignes droites vertes). Observez que les contours du modèle représentent une bonne approximation des contours réels (en pointillé, gris clair), lesquels restent inconnus en pratique.
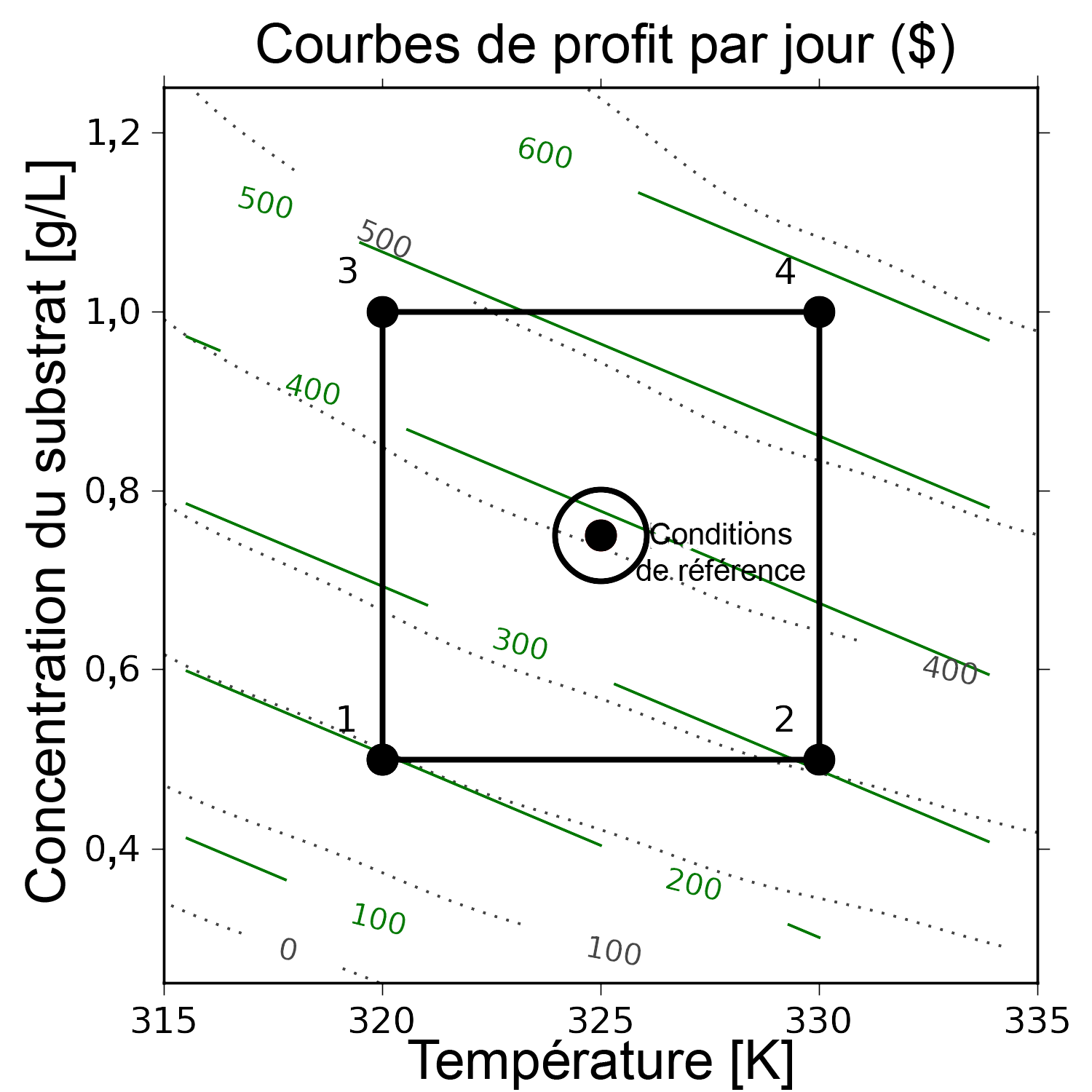
Pour accroître le profit de manière optimale, on se déplace le long de la surface du modèle estimé, dans la direction de la pente maximale. Pour obtenir cette direction, il suffit de prendre les dérivées partielles de la fonction du modèle en ignorant le terme d’interaction (qui est négligeable).
Cela signifie que pour chaque déplacement  unités codées selon
unités codées selon  , il faut égaglement faire un déplacement selon
, il faut égaglement faire un déplacement selon  de
de  unités codées. Mathématiquement :
unités codées. Mathématiquement :
Le plus simple, c’est de choisir le pas de l’une des variables, puis d’ajuster l’autre en conséquence.
Ainsi, on choisit d’augmenter de  unité codée, ce qui signifie :
unité codée, ce qui signifie :
\Delta x_{T,\text{réelle}} &= 5 \,\text{K} \\
\Delta x_S &= \frac{b_S}{b_T} \Delta x_T = \frac{134}{55} \Delta x_T \\
\text{mais comme}\qquad\qquad \Delta x_S &= \frac{x_{S,\text{réelle}}}{\Delta_S / 2} \\
\Delta x_{S,\text{réelle}} &= \frac{134}{55} \times 1 \times \Delta_S / 2\,\, \text{en comparant les deux lignes précédentes} \\
\Delta x_{S,\text{réelle}} &= \frac{134}{55} \times 1 \times 0,5 / 2 = \bf{0,61}\,\,\text{g/L}\\\end{split}\]


On mène donc l’expérience suivante selon ces conditions, et le profit quotidien vaut y_5 = 669 $ y_5 = 669 $. Il s’agit d’une amélioration substantielle par rapport aux conditions de référence.
On décide d’effectuer un autre déplacement, dans la même direction de pente maximale, c’est-à-dire le long du vecteur qui pointe dans la direction  . On augmente la température de 5K (mais le pas aurait pu être plus grand ou plus petit), et on obtient les conditions suivantes pour l’expérience 6 :
. On augmente la température de 5K (mais le pas aurait pu être plus grand ou plus petit), et on obtient les conditions suivantes pour l’expérience 6 :


Cette fois, le profit est de  . La croissance se poursuit, mais dans une proportion moindre. Elle commence peut-être à se stabiliser. On décide toutefois d’encore monter la température de 5 K et d’augmenter la concentration de substrat en conséquence. On obtient ainsi les conditions suivantes pour l’expérience 7 :
. La croissance se poursuit, mais dans une proportion moindre. Elle commence peut-être à se stabiliser. On décide toutefois d’encore monter la température de 5 K et d’augmenter la concentration de substrat en conséquence. On obtient ainsi les conditions suivantes pour l’expérience 7 :


Cette fois, le profit est de  . Nous sommes allés trop loin, puisque les profits ont chuté. Il faut donc revenir au meilleur point précédent, parce que la surface a manifestement changé, et réajuster le modèle avec une nouvelle analyse factorielle dans ce voisinage :
. Nous sommes allés trop loin, puisque les profits ont chuté. Il faut donc revenir au meilleur point précédent, parce que la surface a manifestement changé, et réajuster le modèle avec une nouvelle analyse factorielle dans ce voisinage :
| Expérience | T (réelle) | S (réelle) | T (codée) | S (codée) | Profit |
|---|---|---|---|---|---|
| 6 | 335 K | 1,97 g/L | 0 | 0 | 688 $ |
| 8 | 331 K | 1,77 g/L | - | - | 694 $ |
| 9 | 339 K | 1,77 g/L | + | - | 725 $ |
| 10 | 331 K | 2,17 g/L | - | + | 620 $ |
| 11 | 339 K | 2,17 g/L | + | + | 642 $ |
Pour se déplacer plus lentement le long de la surface, on opte pour de plus petites étendues dans la factorielle : K") et
et g/L") .
.
Un modèle des moindres carrés basé sur les quatre points factoriels (les expériences 8, 9, 10 et 11, exécutées dans un ordre aléatoire), suggère que la tendance la plus favorable serait d’augmenter la température tout en réduisant la concentration de substrat.
\hat{y} &= 673,8 + 13,25 x_T - 39,25 x_S - 2,25 x_T x_S\end{split}\]
Comme auparavant, on avance dans la direction la pente maximale en faisant un pas de  unités le long de la direction et de
unités le long de la direction et de  unités le long de la direction . On choisi à nouveau unité. (Rappelons qu’on pourrait opter pour un pas plus petit ou plus grand, si nécessaire.) Par conséquent :
unités le long de la direction . On choisi à nouveau unité. (Rappelons qu’on pourrait opter pour un pas plus petit ou plus grand, si nécessaire.) Par conséquent :
\Delta x_S &= \frac{-39}{13} \times 1\\
\Delta x_{S, \text{réelle}} &= \frac{-39}{13} \times 1 \times 0,4 /2 = -0,6\,\text{g/L}\\
\Delta x_{T, \text{réelle}} &= 4\,\text{K}\\\end{split}\]


On détermine que le profit s’élève alors à 716 $. Or, l’analyse factorielle précédente présentait une valeur de profit de 725 $ à l’un des coins. Il se pourrait qu’il y ait du bruit dans le systèmes. En effet, la différence entre 716 $ et 725 $ ne représente pas un montant très élevé; en revanche, on observe une différence de profit relativement importante entre les autres points de l’analyse factorielle.
Quelques considérations à prendre en compte lorsqu’on s’approche d’un optimum :
- La variable de réponse atteindra un plateau (rappelez-vous qu’à un optimum, la première dérivée première vaut zéro).
- Si la variable de réponse reste à peu près constante pendant deux sauts consécutifs, vous avez peut-être dépassé l’optimum.
- La variable de réponse peut diminuer, parfois très rapidement, si vous dépassez l’optimum.
- On peut aussi déduire que la surface est courbe si les termes d’interaction sont du même ordre de grandeur (ou plus grands) que les termes d’effets principaux.
En d’autres termes, les optimums présentent une certaine courbure. Ainsi, un modèle qui ne comporte que des termes linéaires ne pourra pas vous indiquer la direction de pente maximale le long de la surface de réponse réelle. Il faut ajouter des termes qui tiennent compte de cette courbure.
9.3.3. Vérification de la courbure
Lorsque le point de centrage mesuré diffère sensiblement du point de centrage prédit par le modèle linéaire, c’est que la surface de réponse est courbe, ce qu’il faut représenter par l’ajout de termes polynomiaux.
Le point de centrage de l’analyse factorielle peut être prédit à partir de  = (0,0)") – c’est simplement le terme d’intersection. Dans la dernière analyse factorielle, le point de centrage prédit correspondait à
– c’est simplement le terme d’intersection. Dans la dernière analyse factorielle, le point de centrage prédit correspondait à  . Or, le point de centrage réel de l’expérience 6 affichait un profit de 688 $. Cette différence de 18 $ s’avère substantielle, surtout si on la compare aux coefficients des effets principaux.
. Or, le point de centrage réel de l’expérience 6 affichait un profit de 688 $. Cette différence de 18 $ s’avère substantielle, surtout si on la compare aux coefficients des effets principaux.
9.3.4. Plans composites centrés
L’analyse détaillée des plans composites centrés ne sera pas abordée dans le présent manuel. Toutefois, cette partie montre quelques exemples à deux et trois variables, à partir d’une factorielle orthogonale existante à laquelle on ajoute des points axiaux. Ces points pourront être aisément ajoutés ultérieurement pour tenir compte de la non-linéarité.
Les points axiaux sont placés à  unité codée du centre pour un système à deux facteurs, et à
unité codée du centre pour un système à deux facteurs, et à  unité codée pour un système à trois facteurs.
unité codée pour un système à trois facteurs.
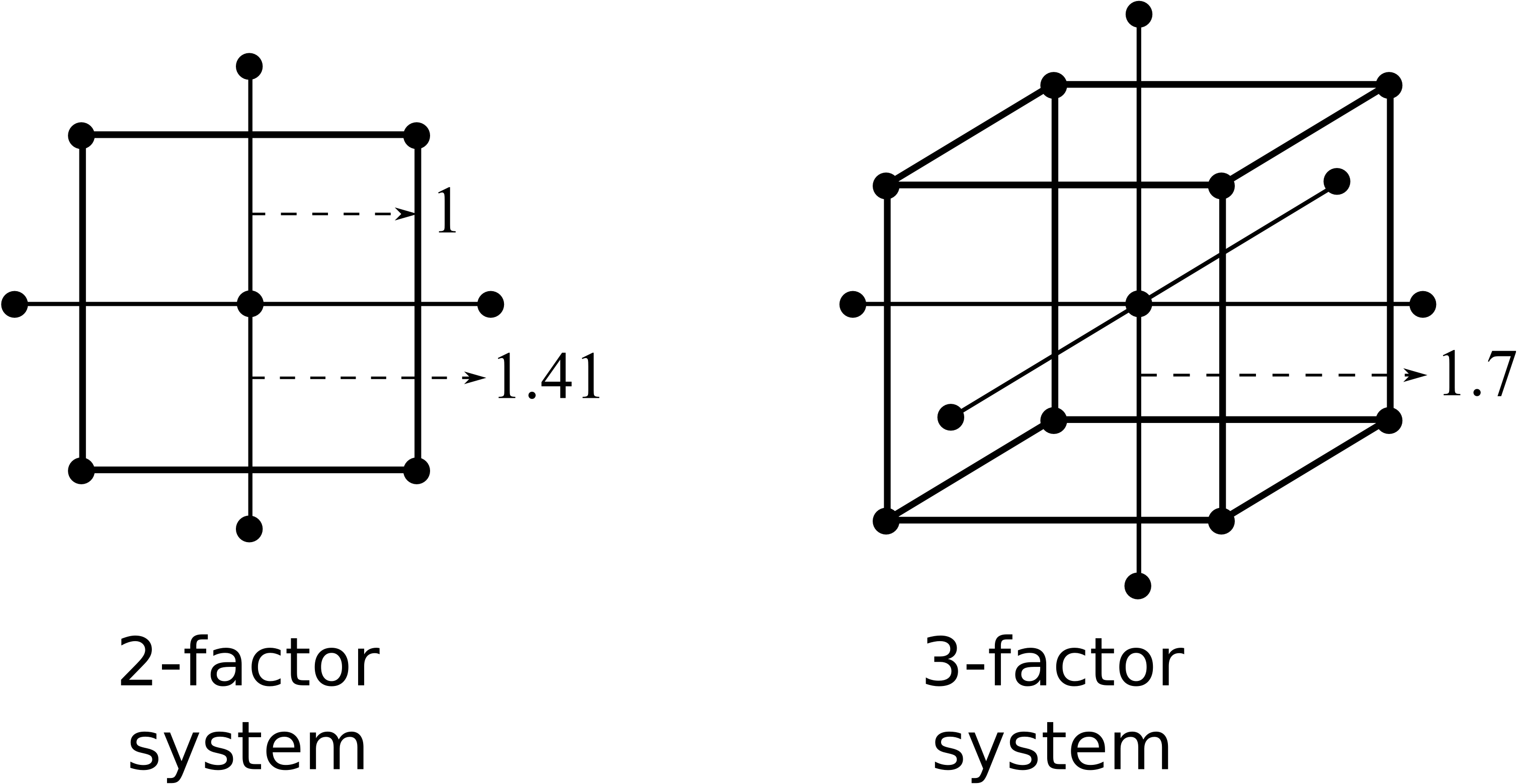
Un plan composite central a été ajouté à l’analyse factorielle dans l’exemple ci-dessus, puis les expériences ont été exécutées, de manière aléatoire, aux quatre points axiaux.
Les quatre valeurs de réponse étaient  ,
,  ,
,  et
et  . Cela nous permet d’estimer un modèle contenant des termes quadratiques :
. Cela nous permet d’estimer un modèle contenant des termes quadratiques :  . Les paramètres de ce modèle s’obtiennent selon la procédure habituelle, en utilisant un modèle des moindres carrés :
. Les paramètres de ce modèle s’obtiennent selon la procédure habituelle, en utilisant un modèle des moindres carrés :

Remarquez que les termes linéaires sont identiques à ce qu’on avait auparavant! Les effets quadratiques se révèlent assez significatifs par rapport aux autres effets; en effet, c’est ce qui a empêché le modèle linéaire de prédire le résultat de l’expérience 12.
La dernière étape de la méthodologie des surfaces de réponse consiste à tracer le contour de ce modèle et à prédire où exécuter les prochaines expériences. Comme le démontrent les lignes continues de contour dans l’illustration, il faudrait exécuter les prochaines expériences approximativement à T = 343K et à S = 1,60 g/L, où le profit escompté avoisine 736 $. (Ces valeurs peuvent être obtenues de manière approximative par un examen visuel, ou de manière analytique.) Le véritable optimum du processus ne se situe pas exactement là, mais il s’en rapproche beaucoup.
Cet exemple a démontré toute la puissance de la méthode des surfaces de réponse. Un nombre minimal d’expériences a rapidement convergé vers le véritable optimum (qui était inconnu) du processus. Pour y parvenir, nous avons établi une succession de modèles des moindres carrés permettant d’obtenir une approximation de la surface sous-jacente. Ces modèles des moindres carrés se construisent avec les outils des analyse factorielles fractionnaires et complètes, ainsi qu’avec les fondements de l’optimisation. Ainsi, sommes en mesure de gravir la pente maximale.



 .
.

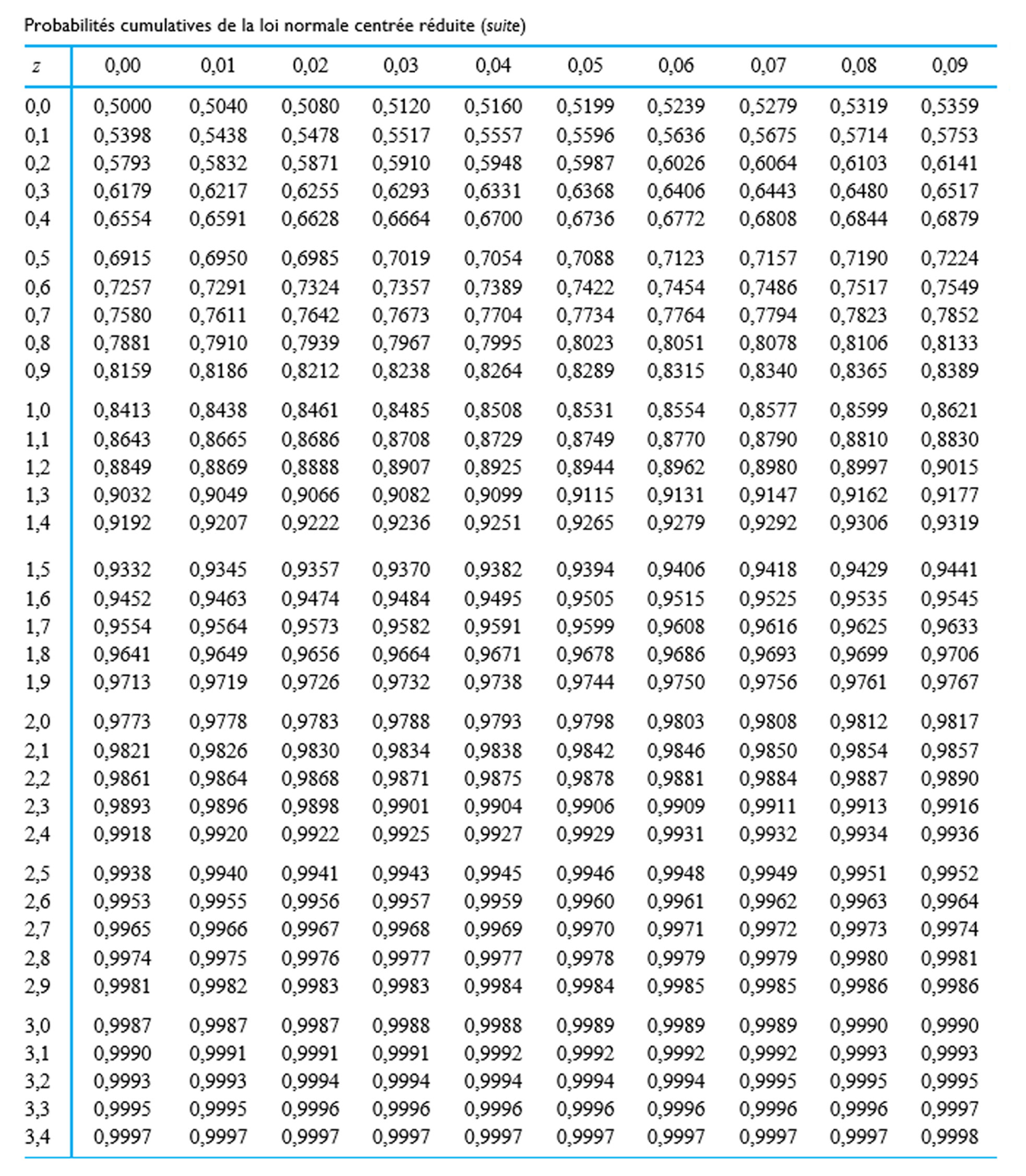
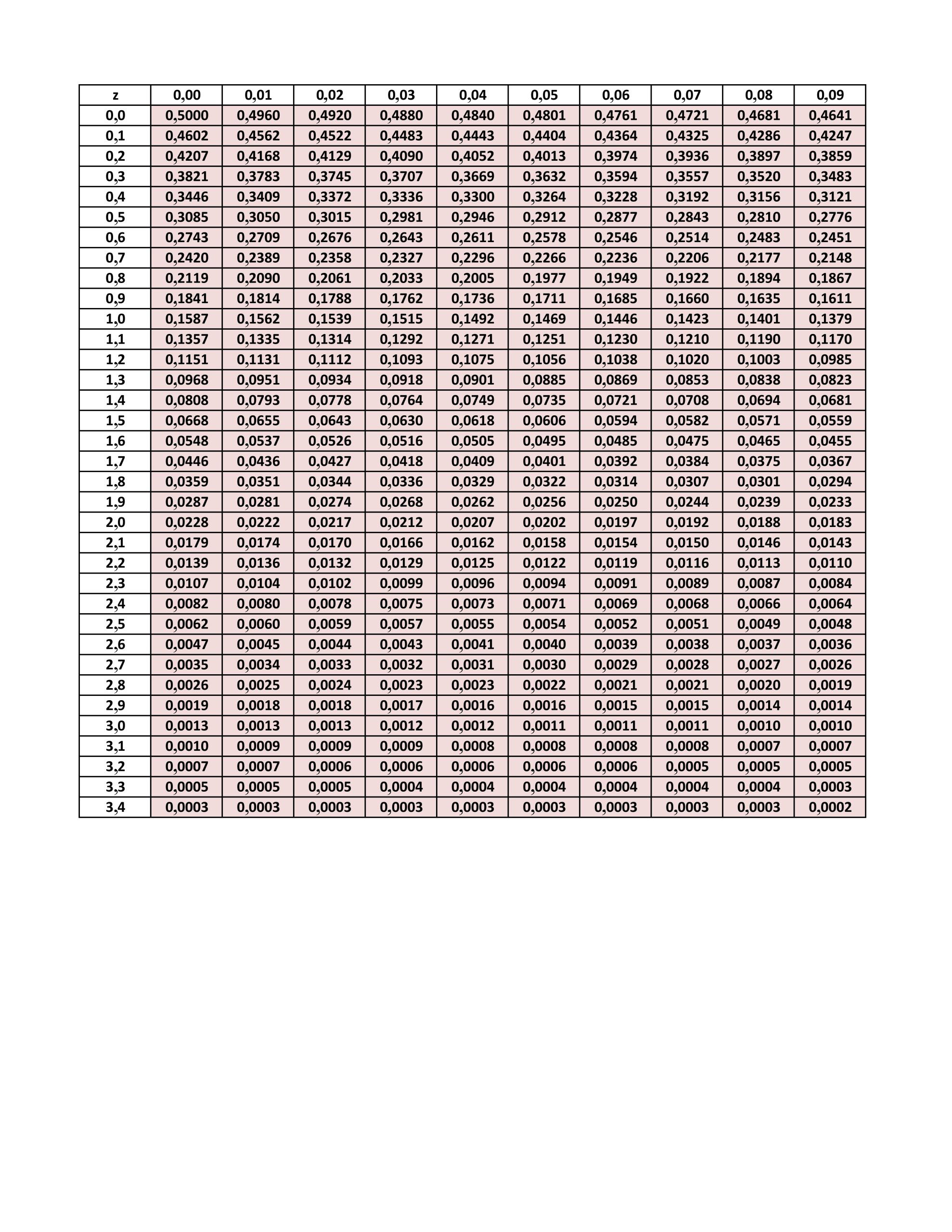
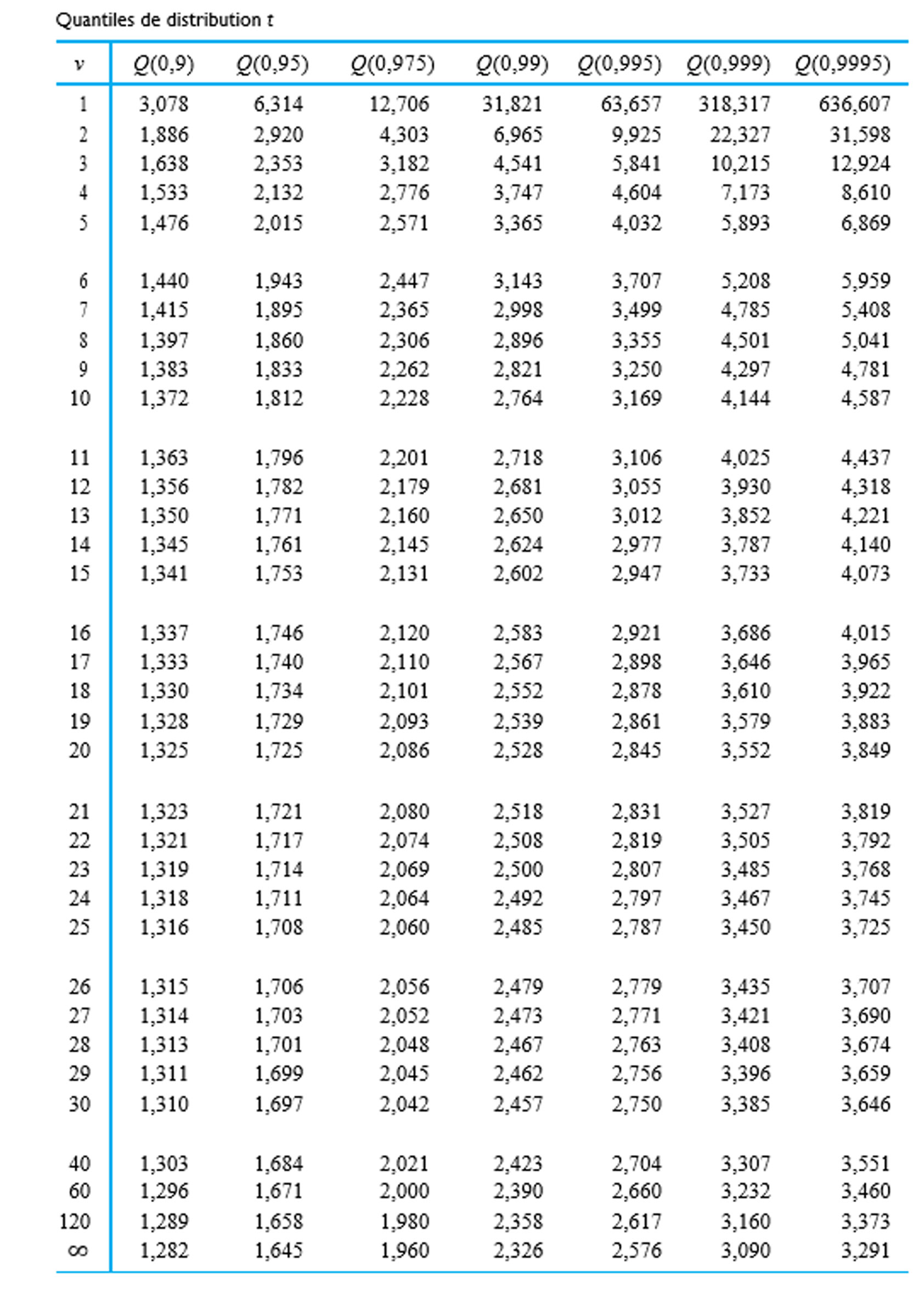
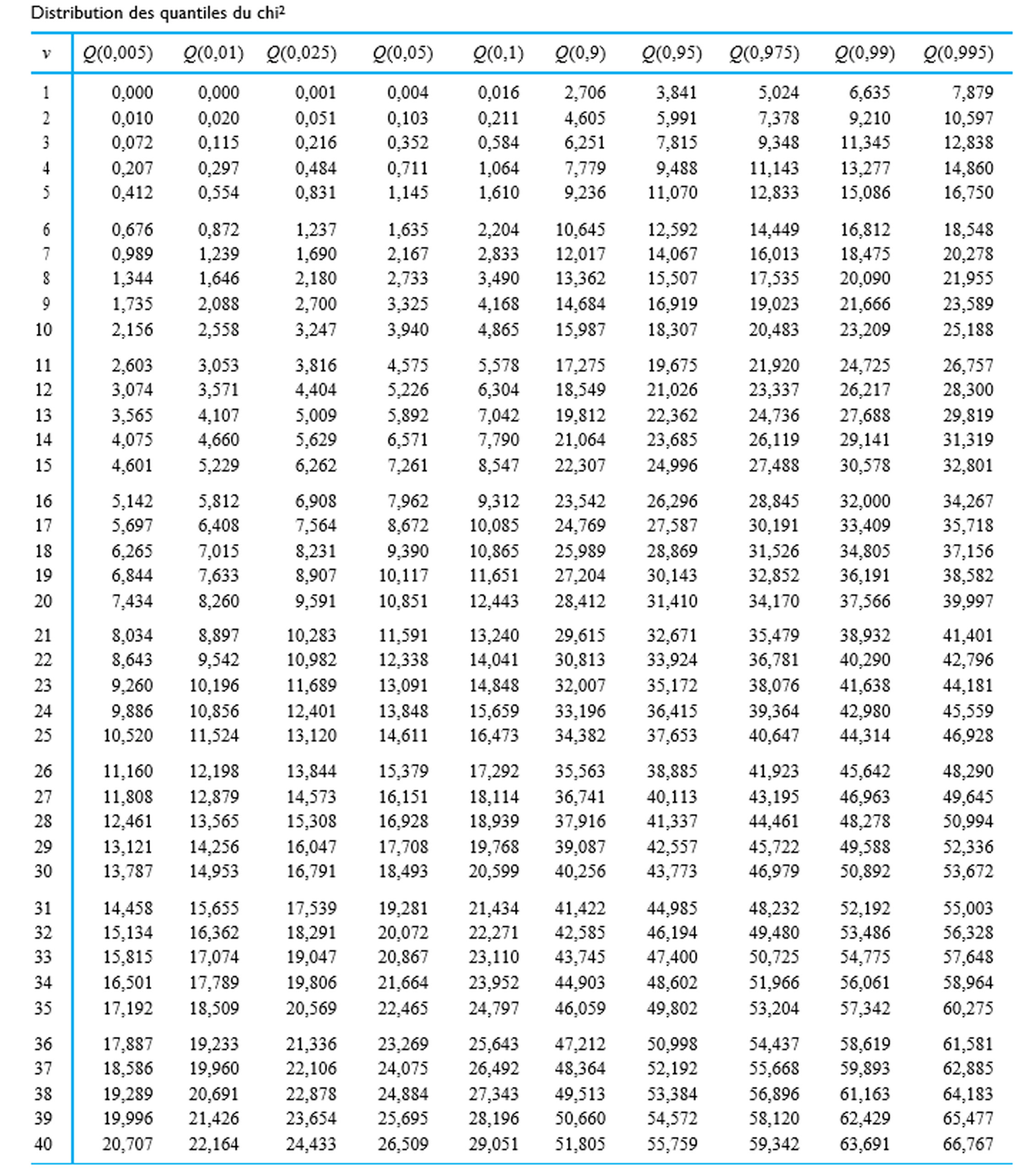

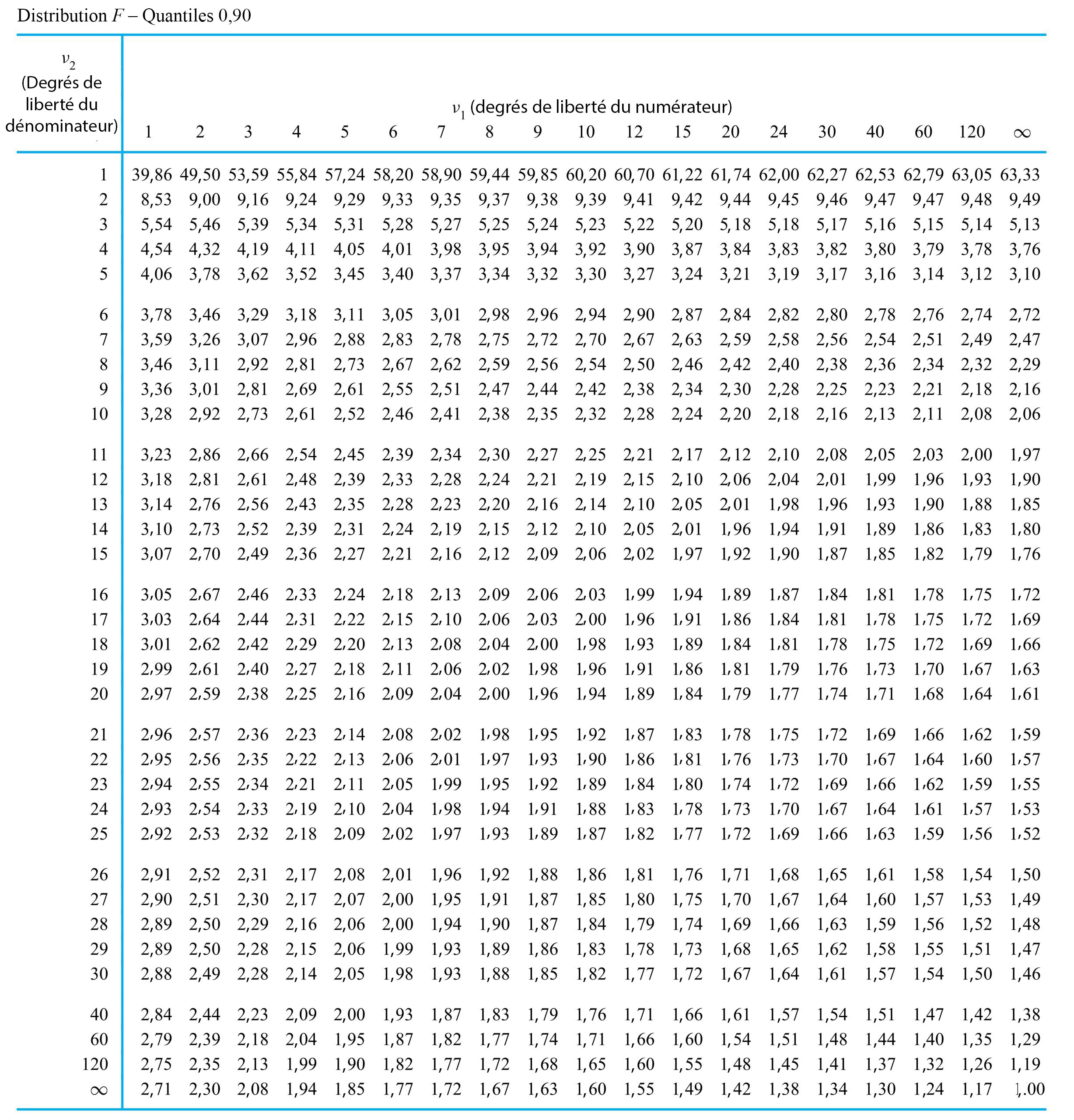
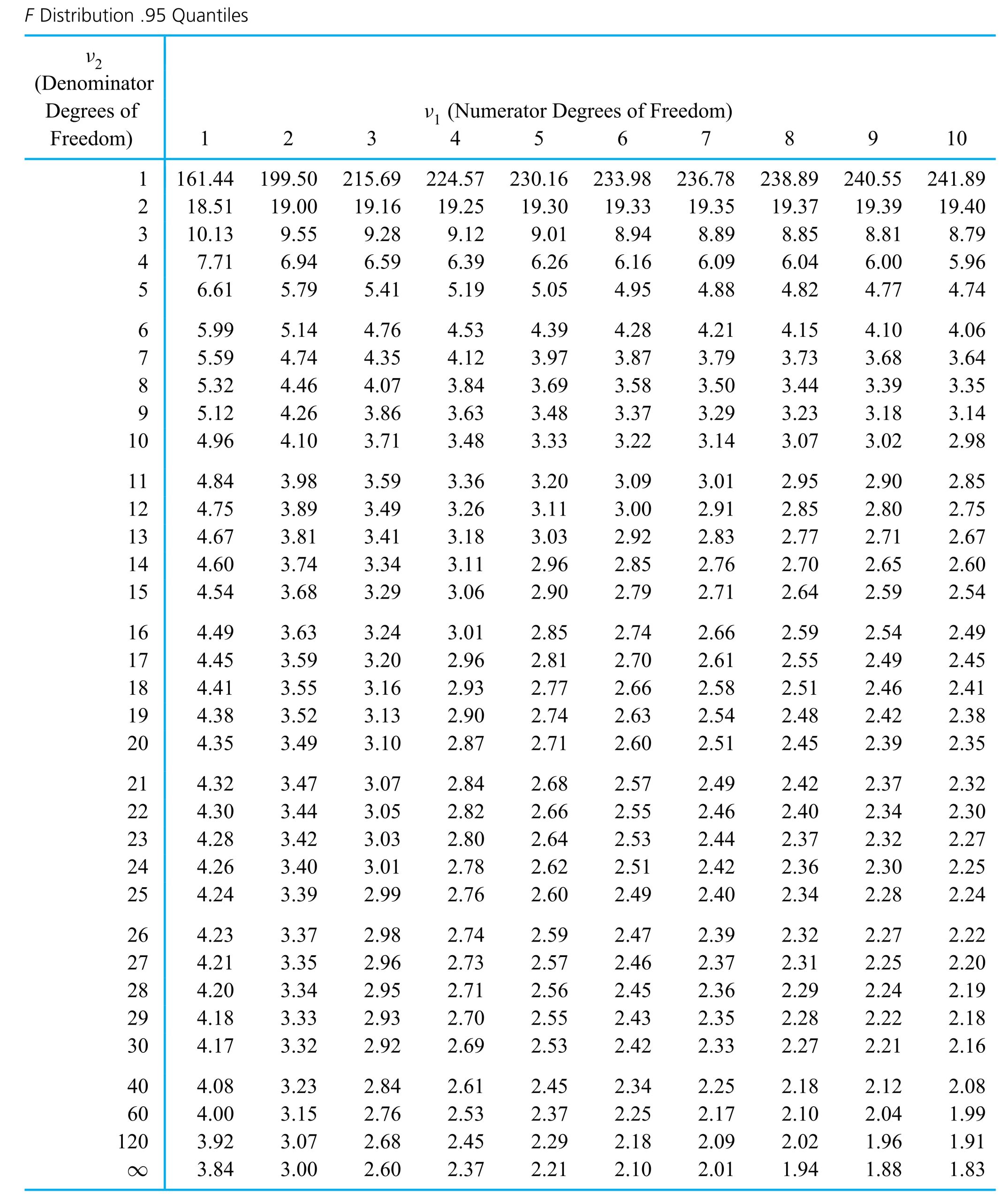
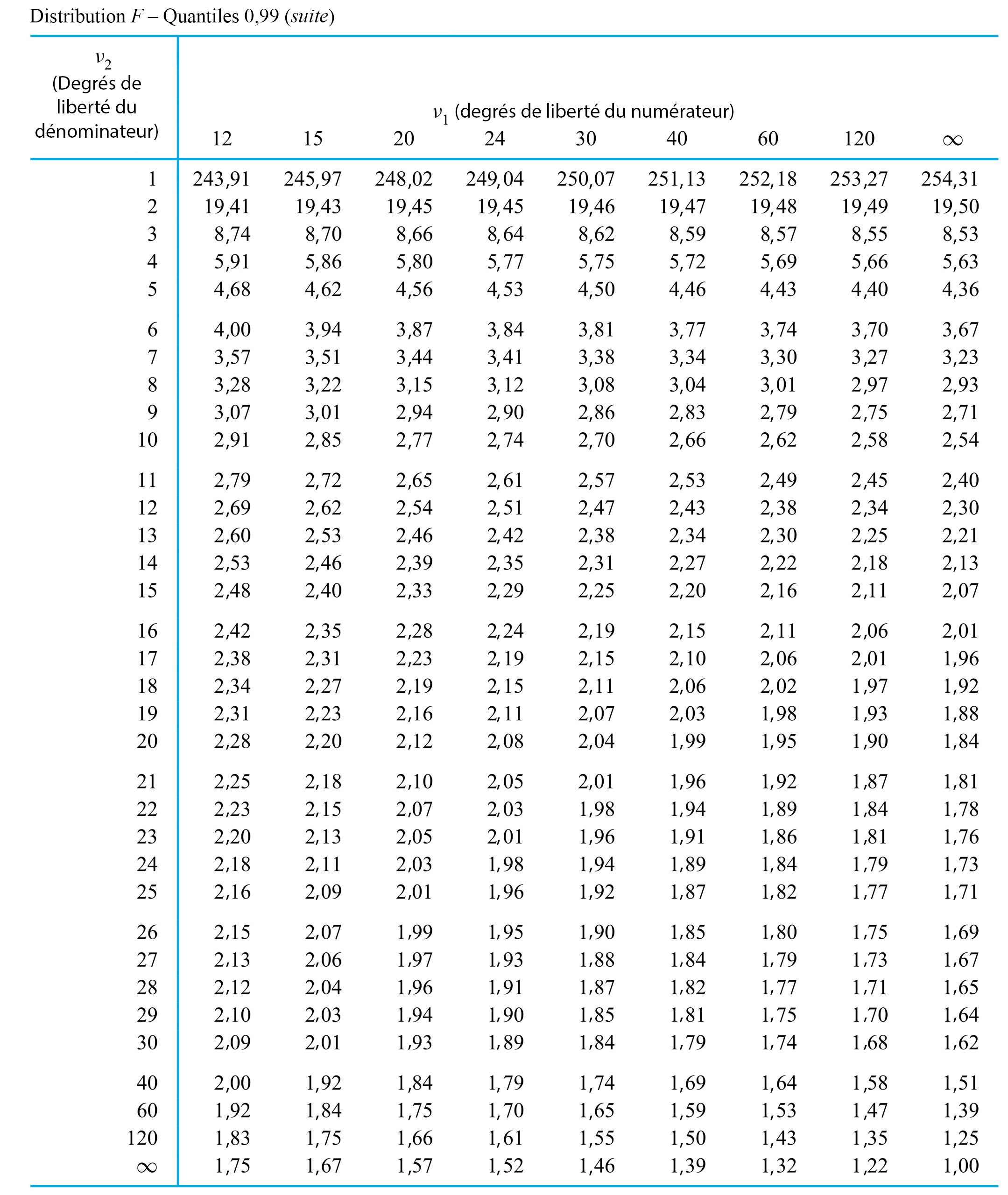
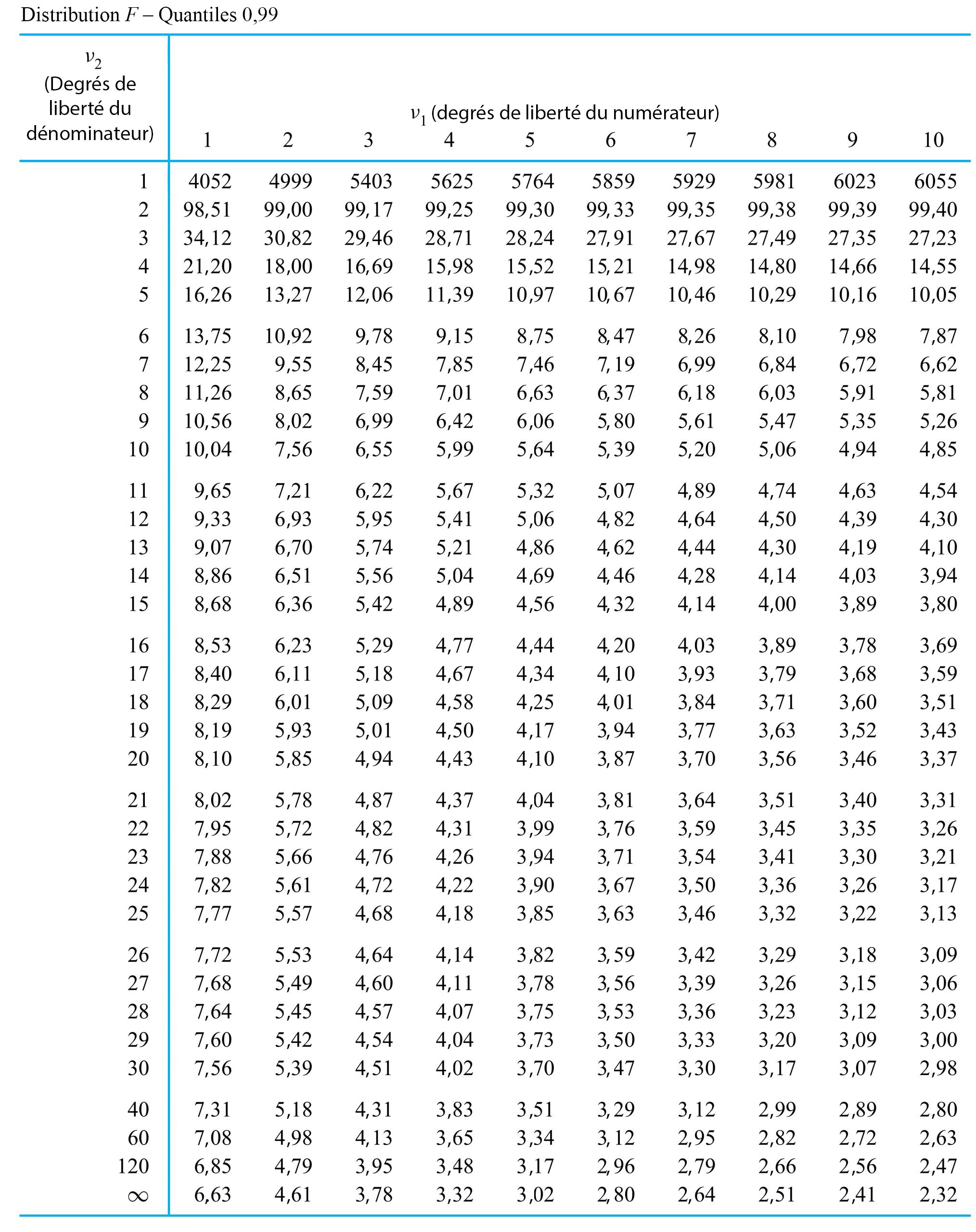
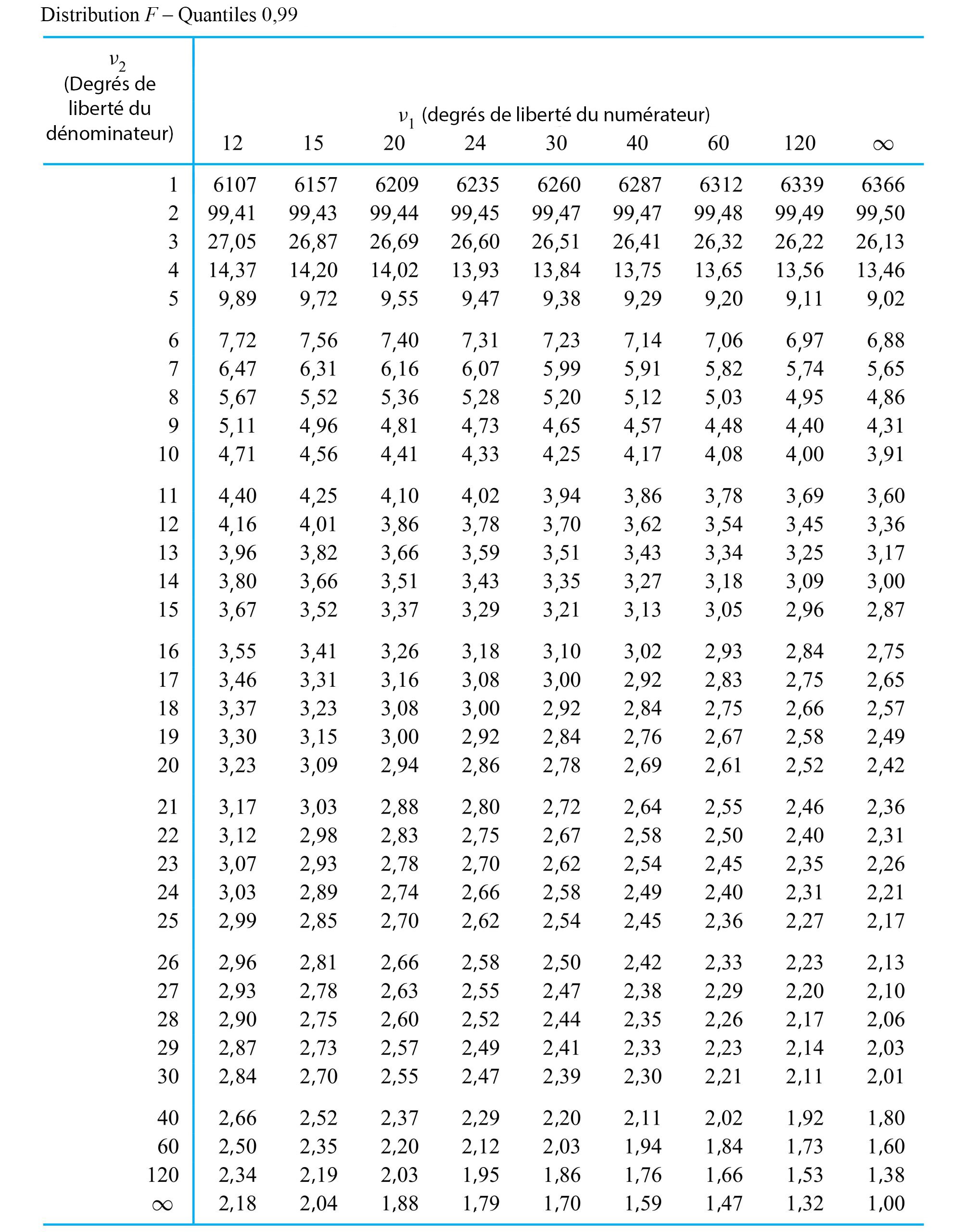
{kind=link}