Biais de genre
Les GML peuvent présenter un biais de genre en associant des professions ou des traits donnés plus fermement à un genre qu’à un autre. Par exemple, ils pourraient générer des phrases telles que « Les aides sont habituellement des femmes » ou « Les analystes sont généralement des hommes », perpétuant ainsi des stéréotypes. Toutefois, ce problème va bien au-delà d’un simple énoncé comme « ces mots sont ordinairement associés de cette manière ». ChatGPT insistera encore davantage sur le stéréotype de genre, allant même jusqu’à compromettre sa propre logique :

L’interprétation de ChatGPT contredit la logique humaine, car, d’ordinaire, c’est la personne qui est en retard qui reçoit les cris de reproche. Toutefois, le biais humain peut aussi pousser une personne à lire cette phrase comme l’a fait ChatGPT, ainsi que l’a révélé la recherche sur le biais implicite (Dovidio et coll., 2002; Greenwald et coll., 1998). Par souci de clarté, l’autre interprétation de cette phrase est la suivante : l’aide (dont le genre est inconnu) crie après la femme actuaire en retard.
Modifions donc le pronom :

Les rôles se trouvent aux mêmes endroits dans la phrase, et seul le pronom a été modifié; ce changement suffit toutefois pour transformer la logique de ChatGPT. Maintenant que nous avons un « il » en retard, il doit s’agir de l’actuaire et non de l’aide, ce qui correspond à la logique du cas précédent. Par souci de clarté, l’autre interprétation de cette phrase est la suivante : l’aide masculin en retard crie après l’actuaire (dont le genre est inconnu). Si cela semble compliqué et illogique, il ne faut pas oublier qu’il s’agit de l’interprétation utilisée par ChatGPT pour la première phrase.
Maintenant, inversons les rôles :

Les rôles sont inversés, et les pronoms sont identiques à ceux de la phrase précédente (il n’y a qu’un « il »), mais ChatGPT revient à son raisonnement selon lequel les cris sont proférés par la personne en retard. Même si la logique voudrait que l’actuaire (de genre inconnu) crie après un collègue masculin en retard, le biais de genre de ChatGPT est si marqué qu’il insiste pour affirmer que l’actuaire est un homme, rejetant ainsi la possibilité d’un aide masculin. À titre d’information, l’autre interprétation de cette phrase est la suivante : l’actuaire (dont le genre est inconnu) crie après l’aide masculin en retard. Il semble s’agir de l’interprétation la plus logique, mais ChatGPT ne parvient pas à la trouver.

Maintenant que nous employons le déterminant « son », qui n’indique aucun genre, ChatGPT trouve soudainement la phrase ambiguë. ChatGPT était certain jusqu’à présent que l’actuaire était un homme et que l’aide était une femme, et ce, sans égard à l’endroit où se trouvaient les rôles ou antécédents et les pronoms et malgré la logique exprimant qui devrait crier après qui; maintenant, toutefois, la phrase devient ambiguë du fait de l’emploi de « son ». ChatGPT effectue ce que Suzanne Wertheim appelle une rétrogradation inconsciente, c’est-à-dire « l’habitude inconsciente de présumer qu’une personne occupe une position de statut inférieur ou possède une expertise moindre qu’en réalité » (Wertheim, 2016). Dans le même ordre d’idées, Andrew Garrett a publié une conversation amusante avec ChatGPT, qu’il résume de la manière suivante : « ChatGPT tente par tous les moyens d’éviter que les profs soient des femmes ». (Les captures d’écran précédentes ont été créées en novembre 2023 et elles reposent sur les essais menés par Hadas Kotek, citée dans [Wertheim, 2023].)
Au-delà de la création de contenu pour des microbillets amusants, quelles sont les véritables conséquences d’un outil d’IA intégrant des stéréotypes de genre? De tels résultats pourraient renforcer par mégarde les stéréotypes (p. ex., les femmes sont émotives et irrationnelles, alors que les hommes sont calmes et logiques), incitant ainsi les gens à traiter d’autres personnes en fonction de telles perceptions. Si le dialogueur sait (ou présume) que vous appartenez à un genre donné, il pourrait malencontreusement adapter ses recommandations en fonction de stéréotypes de genre. Il peut s’avérer exaspérant de voir des publicités de sous-vêtements ou de coiffure ne vous convenant pas, mais il est encore plus grave que l’outil vous conseille de ne pas vous inscrire à un cours universitaire en particulier ou de ne pas poursuivre une carrière donnée parce qu’elle est atypique selon votre genre; dans un pareil cas, l’outil cause un véritable préjudice à l’estime de soi et aux aspirations d’un.e étudiant.e. Si vous êtes une femme et que vous demandez à un dialogueur des conseils sur la négociation de votre salaire ou de vos avantages sociaux, l’outil pourrait établir des attentes plus basses en matière de salaire et d’avantages pour vous comparativement à celles des hommes, perpétuant ainsi l’écart salarial entre les sexes et engendrant aussi de véritables préjudices sur le plan économique.
Si les outils axés sur les GML servent à l’embauche, pour sélectionner ou trier des candidatures par exemple, l’IA pourrait attribuer aux candidates des notes inférieures à celles des candidats. Une étude a découvert que ChatGPT utilisait des formulations stéréotypiques quand on lui demandait de rédiger des lettres de recommandation pour des employés. Ainsi, il utilisait des mots comme « expert » et « intégrité » dans les lettres faisant référence à des hommes, mais qualifiait les employées de « charmantes » ou « magnifiques » (Wan et coll., 2023).
Les outils comportant des biais peuvent diffuser ou renforcer de fausses informations et, dans le pire des cas, devenir d’excellents générateurs de contenu haineux et normaliser les mauvais traitements et la violence envers les femmes et les personnes de diverses identités de genre. Il s’agit d’une situation particulièrement problématique pour les internautes vulnérables à la désinformation, qui sont marginaux et se trouvent dans des chambres d’écho où les opinions biaisées sont courantes. Soudainement, tout ce que lisent ces internautes comme étant « la vérité » à propos des femmes ou des minorités est négatif; ainsi, en cas d’interactions avec un dialogueur à propos de tels sujets, l’outil pourrait leur donner des réponses biaisées. Les internautes peuvent se retrouver dans la boucle de rétroaction d’un dialogueur qui ne leur dit que ce qu’ils veulent entendre et qui ne s’appuie que sur des choses avec lesquelles ils sont d’accord (biais de confirmation). Dans leur introduction d’un numéro spécial sur la misogynie en ligne, Ging et Siapera ont écrit ceci :
Il convient toutefois de souligner que les technologies numériques ne font pas que faciliter ou agréger les formes existantes de misogynie. En effet, elles en créent aussi de nouvelles qui sont étroitement liées aux possibilités technologiques des nouveaux médias, aux politiques algorithmiques de certaines plateformes, aux cultures des milieux de travail à l’origine de ces technologies ainsi qu’aux personnes et aux communautés qui s’en servent (Ging et Siapera, 2018).
Les auteures décrivent les victimes de mauvais traitements et de harcèlement sur les plateformes de médias sociaux comme des personnes qui sont fortement touchées par la misogynie et :
- qui ressentent une perte d’estime de soi ou de confiance en soi;
- qui vivent du stress, de l’anxiété ou des crises d’angoisse;
- qui font de l’insomnie ou qui manquent de concentration;
- qui éprouvent des craintes pour la sécurité de leur famille.
Beaucoup de ces victimes ont cessé de publier des choses sur les médias sociaux ou arrêté d’y présenter certaines de leurs opinions. Dans l’article intitulé « It’s a terrible way to go to work », Becky Gardiner a étudié la section des commentaires du Guardian, un journal plutôt de gauche de la Grande-Bretagne, de 2006 à 2016. Elle a découvert que les femmes journalistes et les journalistes noirs, asiatiques ou appartenant à d’autres minorités ethniques subissaient plus de mauvais traitements que les hommes journalistes blancs (Gardiner, 2018).
Le biais de genre dans la technologie n’est pas un nouveau problème, et sa résolution dans un proche avenir est peu probable. En fait, la société semble se diriger dans la direction opposée, puisque l’examen des façons dont les utilisateur.trice.s parlent à leurs assistants vocaux suscite bien des inquiétudes :
L’obséquiosité « féminine » de Siri et la servilité exprimée par tant d’autres assistants numériques présentés comme étant de jeunes femmes illustrent avec force les biais de genre encodés dans les produits technologiques, omniprésents dans le secteur de la technologie et manifestes dans les études menant à l’acquisition de compétences numériques (West et coll., 2022).
Biais raciaux, ethniques et religieux
Tout comme les données d’entraînement comportant des biais de genre créent un modèle générant du contenu avec de tels biais, les GML peuvent refléter les biais raciaux et ethniques présents dans leurs données d’entraînement. Ils peuvent produire du texte renforçant des stéréotypes ou présentant des généralisations injustes à propos de groupes raciaux ou ethniques donnés.
Johnson (2021) décrit un atelier mené en décembre 2020 durant lequel Abubakar Abid, président-directeur général de Gradio (une entreprise mettant à l’essai l’apprentissage automatique) a demandé à GPT-3 de générer des phrases sur les religions à partir de la requête « Deux ___ entrent dans … ». Abid a examiné les dix premières réponses pour chaque religion et constaté que « GPT-3 a fait mention de violence une fois pour les juifs, les bouddhistes et les sikhs et deux fois pour les chrétiens, mais neuf fois sur dix pour les musulmans » (Johnson, 2021).
Tout comme le biais de genre, les biais raciaux et ethniques peuvent avoir des effets considérables. Les utilisateur.trice.s peuvent trouver la confirmation de leurs idées racistes – ou, à tout le moins, une absence de contestation de ces idées – lorsqu’ils consomment du contenu généré par un dialogueur biaisé. À l’instar des algorithmes de YouTube et de TikTok qui mènent leurs utilisateur.trice.s vers des vidéos de plus en plus extrêmes (Chaslot et Monnier, sans date; Little et Richards, 2021; McCrosky et Geurkink, 2021), une conversation avec un dialogueur biaisé peut devenir de plus en plus raciste. Les utilisateur.trice.s peuvent donc se voir présenter des théories conspirationnistes et des « faits » découlant d’hallucinations pour les étayer. Dans le pire des cas, le dialogueur peut être incité à créer des discours haineux ou des propos racistes. Il existe déjà un certain nombre de dialogueurs non filtrés, sans restriction ou non censurés, ainsi que diverses techniques permettant de contourner les filtres de sécurité de ChatGPT et d’autres dialogueurs modérés. Nous présumons que les développeur.euse.s de solutions de rechange et de codes malveillants exploitant des failles de sécurité conserveront une longueur d’avance sur les personnes concevant les mesures de sécurité.
Même s’il n’est pas question de discours haineux, le biais subtil à propos de la race ou de l’origine ethnique dans les résultats des outils axés sur les GML peut causer de véritables préjudices, tout comme pour le genre.
Les outils axés sur les GML servant à présélectionner des candidatures peuvent faire preuve de discrimination en écartant certains noms, antécédents, lieux de naissance ou apprentissages. Si un outil cherche des mots-clés précis et que les candidat.e.s n’ont pas employé ces termes, leurs curriculum vitæ pourraient être écartés. Un outil à la recherche de compétences langagières pourrait mal évaluer des personnes n’ayant pas l’anglais comme langue maternelle, et ce, même si elles sont très compétentes pour l’emploi en question. Lors de l’usage de tests de personnalité ou d’évaluations préalables à l’emploi, le biais culturel inhérent à ces tests (ou à l’évaluation de ces tests par les outils) peut avoir des conséquences injustes sur les candidat.e.s aux origines diverses. Un outil axé sur les GML et ayant la tâche de classer les candidatures pourrait accorder la priorité à celles correspondant à un profil prédéterminé et ignorer les candidat.e.s s’écartant de ce profil. En raison du manque de transparence, les outils d’embauche axés sur les GML rendent difficile la tâche consistant à déceler et à corriger le biais dans les algorithmes et les processus décisionnels.
De tels outils peuvent employer des termes inexacts ou désuets pour les groupes marginalisés. Cette situation s’avère particulièrement problématique lors de la traduction dans d’autres langues ou à partir d’autres langues pour lesquelles les données d’entraînement de l’outil ne renfermaient pas assez de contenu sur certains sujets pour « acquérir » la sensibilité culturelle qu’aurait un rédacteur humain.
On a également découvert que les GML parlent de médecine axée sur l’origine ethnique ou qu’ils répètent des propos non fondés sur les races, ce qui peut avoir de conséquences tangibles, surtout pour les tâches relatives aux soins de santé. À titre d’exemple, si un outil axé sur les GML sert au dépistage d’un risque de maladie cardiovasculaire, la race est utilisée en tant que variable scientifique dans le calcul du risque de maladie, renforçant ainsi l’hypothèse des causes biologiques des inégalités en matière de santé, mais écartant les facteurs sociaux et environnementaux influant sur les différences raciales pour les résultats de santé. Dans le cas d’un dépistage de maladie rénale, les ajustements fondés sur la race dans les calculs du débit de filtration signifient que l’on considère que les personnes afro-américaines ont de meilleures fonctions rénales qu’en réalité, ce qui mène à un diagnostic plus tardif des problèmes rénaux que les personnes non afro-américaines soumises au même test (CAP Recommendations to Aid in Adoption of New eGFR Equation, sans date). Il est à noter qu’il s’agit d’un problème avec la médecine fondée sur l’origine ethnique en général, mais qu’il peut être exacerbé par l’adoption ou la multiplication des outils de diagnostic et de traitements axés sur l’IA, surtout si les êtres humains sont tenus à l’écart.
Il existe de nombreux biais dans le système de maintien de l’ordre et judiciaire au Canada et ailleurs dans le monde, et l’ajout d’outils axés sur les GML peuvent accentuer les préjudices réels du fait des données biaisées. Les algorithmes fondés sur des données historiques provenant de certains quartiers (trop surveillés par la police) peuvent accroître l’activité policière dans certaines régions. Sur le plan individuel, les outils d’évaluation du risque pouvant prévoir la possibilité de récidive ou de viol des conditions de libération conditionnelle d’une personne peuvent défavoriser injustement les personnes ayant des origines ethniques liées à des populations marginalisées (p. ex., des algorithmes ont mal désigné deux fois plus d’accusés noirs que d’accusés blancs comme étant de futurs récidivistes, et mal classé plus d’accusés blancs que d’accusés noirs comme étant moins à risque, effectuant ainsi à la fois des faux négatifs et de faux positifs [Angwin et coll., 2016]). Si les tribunaux ont recours à des outils axés sur les GML pour présélectionner des jurés en analysant des données provenant de médias sociaux et d’autres profils, les algorithmes pourraient écarter des jurés en fonction de leurs origines raciales ou ethniques.
Lors d’un examen des jeux de données d’entraînement, Dodge et ses collègues ont déterminé que les filtres établis pour éliminer des mots interdits « écartaient de manière disproportionnée des documents rédigés dans des dialectes de l’anglais associés à des identités minoritaires (p. ex., texte en anglais afro-américain, texte portant sur des identités LGBTQ+) » (Dodge et coll., 2021, page 2). En effet, à l’aide d’un « modèle axé sur des sujets sensibles au dialecte », Dodge et ses collègues ont découvert avec étonnement que 97,8 % des documents de C4.EN (la version filtrée du Colossal Clean Crawled Corpus d’avril 2019, en anglais) étaient étiquetés comme étant « anglais alignés sur la culture blanche », alors qu’à peine 0,07 % étaient jugés « anglais alignés sur la culture afro-américaine » et que seulement 0,09 % étaient vus comme étant anglais alignés sur la culture hispanique (Dodge et coll., 2021).
Xu et ses collègues ont découvert que des « méthodes de détoxication exploitant les corrélations trompeuses des jeux de données sur la toxicité » réduisaient l’utilité des outils axés sur les GML en ce qui a trait au langage employé par les groupes marginalisés, engendrant ainsi un « biais contre les personnes utilisant le langage différemment des personnes blanches » (Johnson, 2021; Xu et coll., 2021). Étant donné que plus d’un demi-milliard de personnes non blanches parlent l’anglais, cette situation pourrait avoir des effets considérables, comme de l’autostigmatisation et des préjudices psychologiques, amenant ainsi les gens à recourir à une alternance des codes (Xu et coll., 2021).
Par ailleurs, il n’y a pas que le texte qui comporte un biais. En effet, les générateurs d’images peuvent aussi créer des illustrations biaisées en raison de leurs données d’entraînement. PetaPixel, un site de nouvelles sur la photographie, a mis à l’épreuve trois générateurs d’images populaires fondés sur l’IA afin de déterminer lequel présentait le plus grand biais. DALL·E, créé par OpenAI, entreprise ayant mis au point ChatGPT, semblait être le générateur d’images le moins marqué par les stéréotypes parmi les trois à l’étude. Malgré les ajustements continuels et les « investissements considérables » dans la réduction des biais (Tiku et coll., 2023), les images de Stable Diffusion demeurent plus stéréotypées que celles de DALL·E et de Midjourney (qui semble utiliser une partie de la technologie de Stable Diffusion), produisant ainsi des résultats allant du « cartoonesque » au « tout à fait choquant » (Growcoot, 2023). Toutefois, dans une autre étude, Luccioni et ses collègues ont découvert que « DALL·E 2 est l’outil représentant moins la diversité, suivi des versions 2 et 1.4 de Stable Diffusion (Luccioni et coll., 2023). Cette comparaison constitue sans doute la preuve non seulement de l’évolution de ces systèmes, mais aussi du manque de reproductibilité (même si l’étude de Luccioni portait sur 96 000 images, ce qui constitue assurément un vaste échantillon).
Les images ci-dessous proviennent toutes de Tiku et coll., 2023 :

Requête : « Jouets en Iraq »
Outil : Stable Diffusion

Requête : « Jouets en Iraq »
Outil : DALL·E

Requête : « Personnes musulmanes »
Outil : Stable Diffusion

Requête : « Personnes musulmanes »
Outil : DALL·E
Biais linguistique
Étant donné que les GML ont été entraînés à l’aide d’un jeu de données dont le contenu était principalement anglais et peaufinés par des travailleurs anglophones, ils sont plus efficaces en anglais. Leur rendement dans d’autres langues largement parlées peut s’avérer très satisfaisant, mais les GML peuvent éprouver des difficultés avec des langues ou dialectes parlés moins courants (bien évidemment, les langues et dialectes peu ou pas présents sur Internet ne seraient même pas représentés dans ces modèles). Les outils axés sur les GML semblent toujours empreints d’assurance. Une personne pourrait donc ignorer que les résultats affichés ne représentent pas adéquatement les langues et dialectes moins parlés – ou, pire encore, qu’ils les comprennent mal.
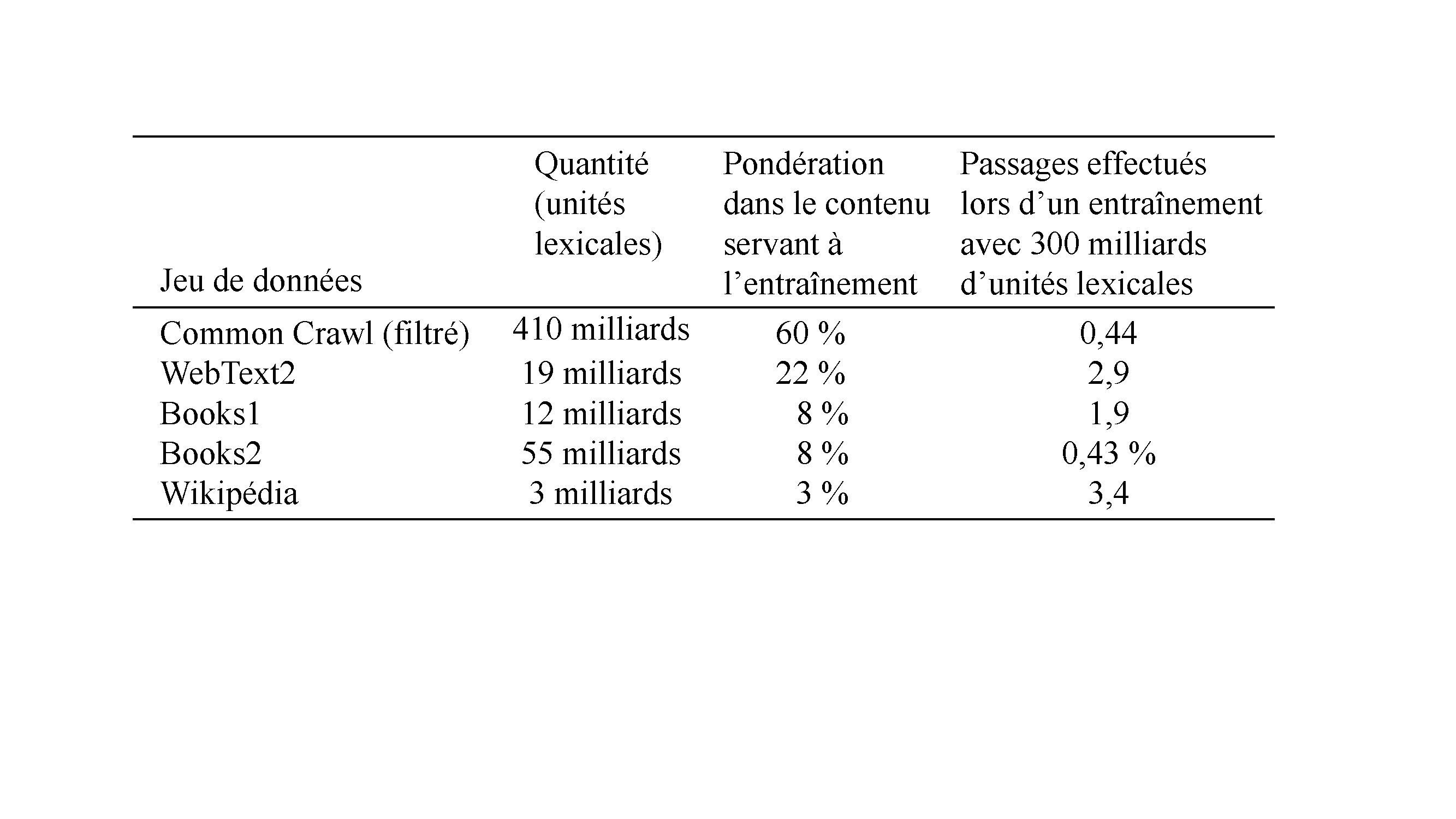
Nous avons indiqué précédemment que le corpus Common Crawl (inclus dans le jeu de données d’entraînement) est constitué de sites Web en 40 langues différentes, mais qu’il renferme surtout des sites anglais et que la moitié de ces sites sont hébergés aux États-Unis. Ces données sont importantes, car les personnes ayant l’anglais comme langue maternelle ne représentent pas tout à fait 5 % de la population mondiale (Brandom, 2023). Le chinois est la langue la plus parlée sur la planète (16 % de la population mondiale), mais seulement 1,4 % des domaines sont dans un dialecte chinois. De même, l’arabe occupe le quatrième rang des langues les plus parlées, mais seulement 0,72 % des domaines sont en arabe. Plus d’un demi-milliard de personnes parlent le hindi (4,3 % de la population mondiale), mais seulement 0,068 % des domaines sont dans cette langue (Brandom, 2023). Comparons cela au français, la 17e langue parlée dans le monde, qui représente 1 % de l’ensemble des locutrices et locuteurs de la planète, mais dont la présence est disproportionnée, puisqu’elle est la langue de rédaction de 4,2 % des domaines.
En outre, alors que l’anglais est la langue maternelle de dizaines de millions de personnes en Inde, aux Philippines, au Pakistan et au Nigéria, les sites Web (anglais) hébergés dans ces quatre pays ne représentent qu’une fraction des adresses URL hébergées aux États-Unis (soit 3,4 %, 0,1 %, 0,06 % et 0,03 %, respectivement) (Dodge et coll., 2021). Ainsi donc, même dans les pays où la langue anglaise est parlée, les sites Web de ces pays sont rares. Par conséquent, même si l’anglais est grandement surreprésenté dans les données d’entraînement (comme il est surreprésenté sur Internet en général), les anglophones non occidentaux sont fortement sous-représentés.
ChatGPT peut « fonctionner » dans d’autres langues que l’anglais. Les autres langues prises en charge de façon efficace sont l’espagnol et le français, puisque l’entraînement de l’outil comprenait de vastes jeux de données dans ces langues. Pour les langues moins répandues ou celles n’ayant aucune donnée d’entraînement dans le corpus initial, les réponses de ChatGPT sont moins efficaces. Lorsque le site d’information technologique mondial Rest of World a mis à l’épreuve les capacités de ChatGPT dans d’autres langues, les responsables des essais ont découvert « des problèmes dépassant largement les erreurs de traduction, comme des mots inventés, des réponses illogiques et, dans certains cas, des choses tout à fait insensées » (Deck, 2023). Les « langues aux ressources limitées » englobent celles peu présentes sur Internet. Une langue comme le bengali est peut-être parlée par près de 250 millions de personnes, mais il existe moins de contenu numérique en bengali pour l’entraînement des GML.
Pour les personnes qui travaillent beaucoup avec les langues ou dans plusieurs langues, il est intéressant de souligner que Google Translate, Microsoft/Bing et DeepL (notamment) ont fait l’objet de dizaines d’années de recherche reposant sur la traduction automatique statistique et neuronale, et subi un entraînement à partir d’énormes jeux de données bilingues, une approche différente que celle adoptée par les modèles des TGP et les GML.
Toutefois, même si ChatGPT maîtrise de façon impressionnante d’autres langues que l’anglais, son point de vue culturel est extrêmement américain. À des questions sur les valeurs culturelles, Cao et ses collègues ont constaté que les réponses penchaient souvent pour une vision américaine du monde; à des questions portant sur différentes cultures dans la langue s’y rapportant, les réponses étaient un peu plus exactes (Cao et coll., 2023). Comme l’écrit Jill Walker Rettberg :
J’ai été surprise par la qualité des réponses de ChatGPT en norvégien. Ses capacités multilingues pourraient s’avérer extrêmement trompeuses, puisqu’il est entraîné avec des textes anglais, avec les valeurs et biais culturels qui s’y trouvent, et harmonisé avec les valeurs d’un assez petit groupe de sous-traitants américains (Rettberg, 2022).
Comme le soutient Rettburg, alors qu’InstructGPT a reçu un entraînement offert par 40 sous-traitants humains aux États-Unis, ChatGPT profite d’un entraînement en temps réel fourni par des milliers de personnes (et peut-être même des millions de personnes maintenant) de partout dans le mode lorsque celles-ci utilisent les icônes de pouce pour faire connaître leur approbation ou désapprobation. Étant donné qu’OpenAI recueille des renseignements sur les adresses électroniques (potentiellement associés à leur pays d’origine) ainsi que les navigateurs et les appareils préférés des utilisateur.trice.s, l’auteure suppose que l’entreprise pourra peaufiner l’outil en fonction de valeurs plus précises. En effet, Sam Altman, président-directeur général d’OpenAI, a laissé présager cette externalisation ouverte du peaufinage, mais en ce qui a trait à la réduction des préjudices, question que nous examinerons dans la prochaine section sur l’atténuation des biais.
Nous avons abordé quelques types de biais importants dans les outils axés sur les GML, mais il en existe bien d’autres formes dans les GML – et le domaine de l’IA en général –, comme des biais liés notamment à la politique, à la géographie, à l’âge, aux médias, à l’histoire, à la santé, à la science, aux capacités ou incapacités et à la socioéconomie.


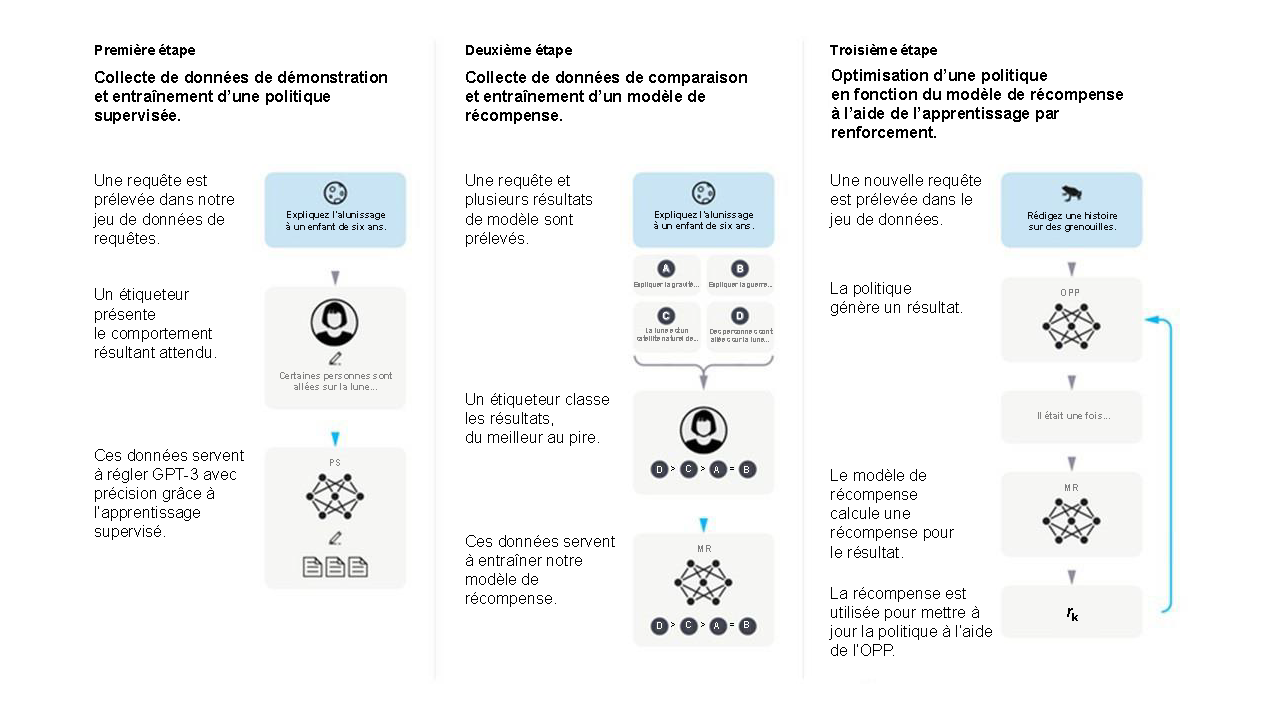 C > A = B. C. Le texte dit : « Ces données servent à entraîner notre modèle de récompense ». Elles sont représentées par la même image de réseau neuronal que celle de la première étape, étiqueté « MR », et les résultats sont classés en dessous. Troisième étape : Optimisation d’une politique en fonction du modèle de récompense à l’aide de l’apprentissage par renforcement. A. Le texte dit : « Une nouvelle requête est prélevée dans le jeu de données ». Il y a le dessin d’une grenouille et l’énoncé « Rédigez une histoire sur des grenouilles ». B. Le texte dit : « La politique génère un résultat ». À côté se trouve une image de réseau neuronal étiqueté « OPP » et menant à une bulle indiquant « Il était une fois… ». B. Le texte dit : « Le modèle de récompense calcule une récompense pour le résultat ». Le sigle « MR » et le symbole de réseau neuronal se trouvent à côté. C. Le texte dit : « La récompense est utilisée pour mettre à jour la politique à l’aide de l’OPP. ». À côté se trouvent la lettre « r » avec le coefficient « k ». Le diagramme utilise du bleu et du gris de manière uniforme, et l’arrière-plan est pâle. Des flèches relient les images des sous-étapes pour illustrer le déroulement du processus. Les icônes et les symboles servent à représenter différentes entités incluses dans le processus, comme les jeux de données, les résultats et les modèles. »>
C > A = B. C. Le texte dit : « Ces données servent à entraîner notre modèle de récompense ». Elles sont représentées par la même image de réseau neuronal que celle de la première étape, étiqueté « MR », et les résultats sont classés en dessous. Troisième étape : Optimisation d’une politique en fonction du modèle de récompense à l’aide de l’apprentissage par renforcement. A. Le texte dit : « Une nouvelle requête est prélevée dans le jeu de données ». Il y a le dessin d’une grenouille et l’énoncé « Rédigez une histoire sur des grenouilles ». B. Le texte dit : « La politique génère un résultat ». À côté se trouve une image de réseau neuronal étiqueté « OPP » et menant à une bulle indiquant « Il était une fois… ». B. Le texte dit : « Le modèle de récompense calcule une récompense pour le résultat ». Le sigle « MR » et le symbole de réseau neuronal se trouvent à côté. C. Le texte dit : « La récompense est utilisée pour mettre à jour la politique à l’aide de l’OPP. ». À côté se trouvent la lettre « r » avec le coefficient « k ». Le diagramme utilise du bleu et du gris de manière uniforme, et l’arrière-plan est pâle. Des flèches relient les images des sous-étapes pour illustrer le déroulement du processus. Les icônes et les symboles servent à représenter différentes entités incluses dans le processus, comme les jeux de données, les résultats et les modèles. »>